前段时间一直想扩展双臂,因为桌面变了,摄像头调高了才能看见全貌
训练效果一直很差
希望(500epcho):
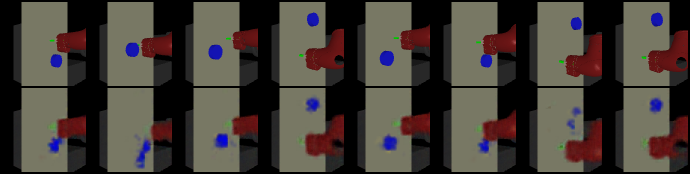
现实(5000epcho):
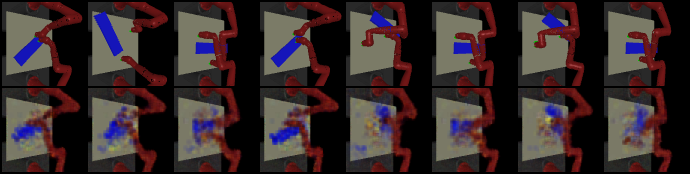
发现了这篇arXiv:1509.06113
稍微总结一下要点,防止以后忘了,这里是另一种autoencoder
并没有支持变分,不过名字叫 Deep Spatial Autoencoder,
与一般的autoencoder不同的是,这个算法关注的是where而不是一般的what
隐空间z里面存的是feature points的坐标。然后在原图中标记出来

算法首先搜集数据然后训练编码器,loss依然是自动编码器的那个loss: ∣∣x−x^∣∣22
其中x是原图,x^是还原后的图像

encoder如上图,先是三层卷积层然后softmax scij=eacij/α/∑i′j′eaci′j′/α把他变成一个分布,然后求期望fc=(∑ii∗scij,∑jj∗scij)求出16个坐标也就是32个数字
一个全联通的线性模型来恢复原图,loss:
LDSAE=t,k∑∥I downsamp,k ,t−hdec(fk,t)∥∥22+g slow (fk,t)
第k个样本,第t时刻的图片,fk,t=henc(Ik,t)是编码后的feature
g slow (ft)=∥(ft+1−ft)−(ft−ft−1)∥22可以理解为机械臂的移动的加速度,最小化这个目的是让机械臂尽量匀速
自己原来的vae里的z是没管里面是啥的,这里是feature points的pos,似乎也可以假设他服从正态分布。这样一来,是不是就是个,ummmmm,Deep Spatial VAE了,好的,我摸了
老板让先用ground turth的先把强化的框架跑出来,毕竟,要毕业嘛,先记在这个小本本上,估计后面再摸吧


 浙公网安备 33010602011771号
浙公网安备 33010602011771号