视觉语言导航综述Visual Language Navigation
abstract: |
视觉语言导航任务(Visual Language Navigation)
是让智能体跟着自然语言指令进行导航,这个任务需要同时理解自然语言指令与视角中可以看见的图像信息,然后在环境中对自身所处状态做出对应的动作,最终达到目标位置。该问题的难点还有自然语言指令的复杂、包含了当前可见与不可见的信息,环境给的反馈非常模糊使得智能体很难判断自身位置。本文从仿真环境与文本数据来源先简单回顾了视觉语言导航任务的历史,然后对于最新的Room-to-Room数据集上冲上榜的算法逐个解读,其都基于seq-to-seq的结构,分别从对齐、数据增强、强化学习三个角度对算法做出改进,使得模型可以更好的理解环境的信息与反馈。另外,对于这一系列问题而言,数据集与仿真环境代价愈发昂贵,真实度愈发接近真实环境,在带标签数据越来越难以满足需求且无标签数据几乎free的背景下,能否使用一些半监督自监督的方法生成数据,是一个值得思考的问题。
(
latex文件转的md,制作比较粗糙
)
概述
视觉语言导航(Vision Language
Navigation)已经有了很多年的历史,本文从仿真环境(simulator)和语料信息的收集方法两角度简短地回忆一下过往的任务与环境。然后着重介绍2018年发表的Room-to-Room数据集[@Anderson2018]并一一分析排行榜上的sota的算法,并总结其共性与特性。各种优化算法都使用的基础的seq-to-seq的框架,并在此基础上主要从对齐、数据增强、强化学习三个角度做优化。对于数据来源目前监督学习依然是底牌,但是其日益增长的带标签数据的需求越发越难以满足,在此出现了很多自监督与半监督的方法,其能够尽最大可能达到接近于监督学习的效果。
视觉语言导航任务
仿真环境与数据来源
视觉语言导航任务比较古老,[@Vogel2010]中在一张画布中遍开始了很原始的视觉语言导航任务的研究。如图1{reference-type=“ref”
reference=“Fig.paint”}中左图所示,在一张手绘的地图中根据自然语言指令标注出对应应该走的路线。其数据收集方法如右图,在一个打印好的模板地图中,两名志愿者,一个用自己的语言描述出路线,另一个根据其语言画出对应的轨迹,最终若说话的人脑中所想的路线与目的地与完成的图片中的路线一致,则为一条有效数据。这个2010年的工作在今天看来已经非常的原始,有点像"你画我猜"游戏。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XVaJj1WH-1578753807547)(image/paint.png)]{#Fig.paint
width=“50%”}
另一个也是广泛被应用的方法是构建一个仿真环境,在环境中做导航。[@Tellex2011]中在仿真环境下完成了一个叉车搬运物体的任务,其自然语言指令主要通过斯坦福NLP的语法树来生成(图2{reference-type=“ref”
reference=“Fig.mobile”})。由于是2011年的工作,在神经网络没有大规模应用的时代,原文中定义了很多传统的方法来解决这一特定场景下的问题,由于问题过于特殊,在此不做过多展开。
![左图,环境中的一个任务的示例:首先移动到物体附近,然后用叉车运送物体到指定地点,最后把物体放在桌子上;右图:自然语言指令使用了斯坦福NLP组的工具生成,原理是语法树.图片来源[@Tellex2011]](https://img-blog.csdnimg.cn/2020011122453441.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2N3dzk3,size_16,color_FFFFFF,t_70)
[@Chen2011; @Chaplot2018; @Sinha2019]都在类似游戏的3D模拟器中完成导航任务,文本数据也较为简单,基本可以通过一些人为构造出的规则生成出。其模拟环境大多是简单的3D建模,配合一定的纹理贴图或者图像贴图。其中[@Chaplot2018]中环境与指令如图rua所示,在仿真环境中"Go
to the short red
torch",这里的句子非常简短也几乎是结构化的,在其开放的源码中可以看见其手动输入的70个指令,然后对其中一部分词进行替换,比如物体的特征与物体等等(颜色,火炬)。结合在环境中的不同采样,可以短时间几乎没有代价的生成大量数据。
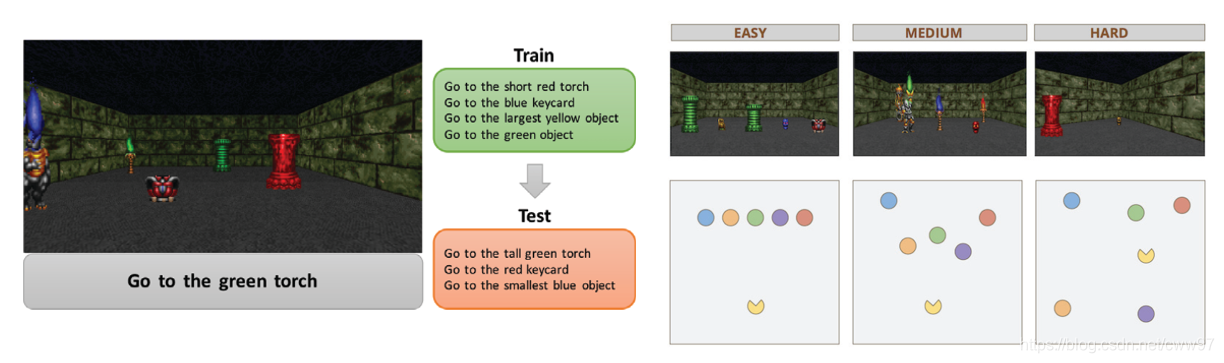
![左:仿真环境与任务;右:定义的easy,mid,hard三个等级的任务.图片来源[@Chaplot2018][]{label="Fig.gate"}](image/Gated-Attention.png) {#Fig.gate width=“100%”}
{#Fig.gate width=“100%”}
本文的问题定义
[@Chang2018]使用Matterport摄像机在九十多个建筑物中提供了10800个全景视角(包含194400张RGB-D图片),通过这些数据构建出了一个庞大的、基于真实场景的仿真环境,因为其所有的图片都是单独从真实环境中采样的,所以与之前的通过大量纹理贴图制作出来的仿真环境相比更加真实更加复杂,每一处纹理都不一样,这要求模型学习到更加高级的特征才能有效的在环境中学习。
在此基础上[@Anderson2018]制作了Room2Room数据集,该数据集首先将每个场景标出若干个停留的点,相邻的点直接建边,以此转化成一个图的结构,可以理解为是做了一共离散化的操作,在这张图上随机采样路径,对符合要求的路径(路径长度、复杂度等等)整理出来在AMT平台上让400个worker人工的撰写自然语言指令,大约耗费了1600小时。这些指令作为路径的人工标注的label,于是这个任务有了完整的数据集。机器学习的任务便是在自然语言指令的指挥下,完成对应路径的导航。该任务难点主要集中在:1)需要跨模态的数据的理解:需要理解图像与语言指令的共同的理解来输出下一步的动作(actio);2)环境给的反馈信息非常模糊:环境只会给一步动作之后的视角(view)而不会给其他反馈比如当前走到了哪里有没有走对等等;
3)
泛化性要求高:所有场景均为实拍使得所有物体的纹理都不一样导致模型需要学习到更高级别的特征信息(feature)。
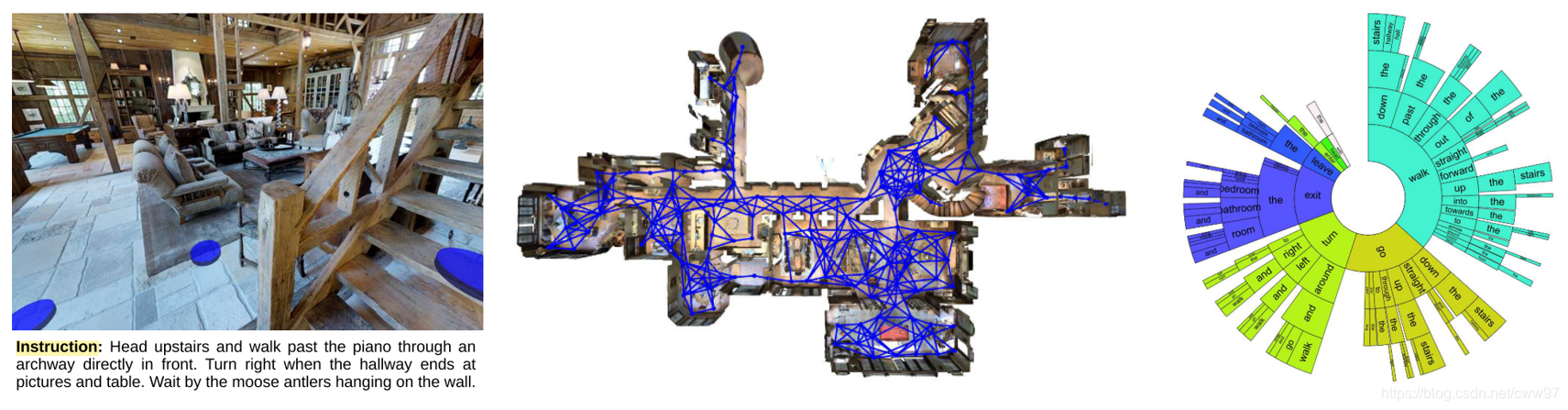
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FHXLkoVM-1578753807548)(image/VLN.png)]{#Fig.VLN
width=“100%”}
从模拟器的搭建到数据集的收集,明显感觉到比构建平面贴图与现在的自动生成标签(自然语言导航指令)达到的效果更加真实,因为其所有场景均为实拍且所有标签为人工生成。对应的,两个工作对人力的要求极高,成为了两个极其烧钱的工作。前人栽树,后人乘凉,下文提及的解决该问题的各种方法,利用其标准数据使用了很多自监督与半监督的方法,我们将在3{reference-type=“ref”
reference=“vln_algorithm”}种详细讲解。
视觉语言导航算法 {#vln_algorithm}
本章主要表述在VLN任务上冲上榜且发出文章的方法,所有的方法都基于baseline的seq-to-seq的方法做出各种方面的改进。先说一些后文不会详细展开的内容,既然要对自然语言的指令进行理解,那么逃不掉LSTM[@hochreiter1997long]和Attention[@bahdanau2014neural; @NIPS2017_7181],对于图像信息的处理必然逃不开CNN[@NIPS2012_4824],另外导航问题本质上是一个机器人控制问题,涉及决策,逃不开的便是强化学习的框架[@francoislavet2018introduction]。这三者的结合构成了当前几乎所有视觉语言导航任务乃至模态融合任务的基本结构,下面将在3.1{reference-type=“ref”
reference=“seq-to-seq”}中介绍做为baseline的seq-to-seq模型,并在其后介绍其各种扩展与变形,在这个R2R数据集中[@Anderson2018]成绩越来越好。
baseline: seq-to-seq {#seq-to-seq}
[@Anderson2018]中提到了经典的seq-to-seq的模型,使用LSTM为自然语言指令编码,结合在ImageNet上预训练的ResNet为视觉信息编码,再用一个LSTM输出action序列。用attention机制在中间状态做对齐。最终该方法在R2R数据集上达到了20%的成功率和18%的SPL(成功路径长度,针对此类问题比成功率更加客观的评价标准)。原文并未详细描述该类问题的seq2seq模型,不过该类方法先前在[@Mei2016]中有更为详细的应用。
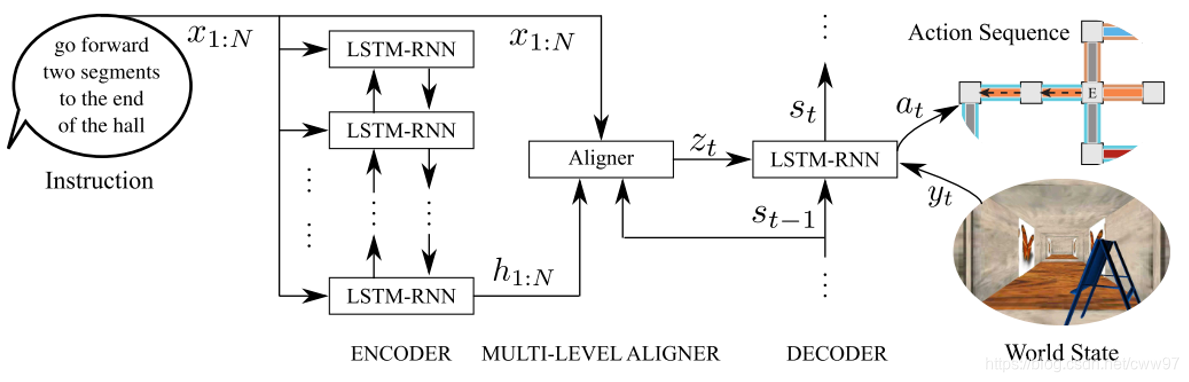
Look Before You Leap
在数据集发表之后,第一个成功冲榜的是[@Wang],该方法结合了强化学习中model-free与model-based两种方法协同做决策,提高了决策的科学性。如图5{reference-type=“ref”
reference=“Fig.RPA”}左图所示,左边绿色的框中为model-free方法,本质上就是baseline中的seq2seq方法,Language
Encoder是处理自然语言指令的LSTM,图像输入使用CNN提取feature,两个输入来源使用一个Recurrent
Policy
Model来输出aciton,整个model其实也没有什么特别新的地方,因为其输出是一个action的序列,故又是LSTM的一个变体。
具体优化形式如公式[equ_lbyl_lstm]{reference-type=“ref”
reference=“equ_lbyl_lstm”},其中是attention后的图像与语言输入。
KaTeX parse error: Undefined control sequence: \label at position 1: \̲l̲a̲b̲e̲l̲{equ_lbyl_lstm}…
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OxOtQb4Y-1578753807548)(image/look_before_you_leap.png “fig:”)]{#Fig.RPA
width=“100%”}
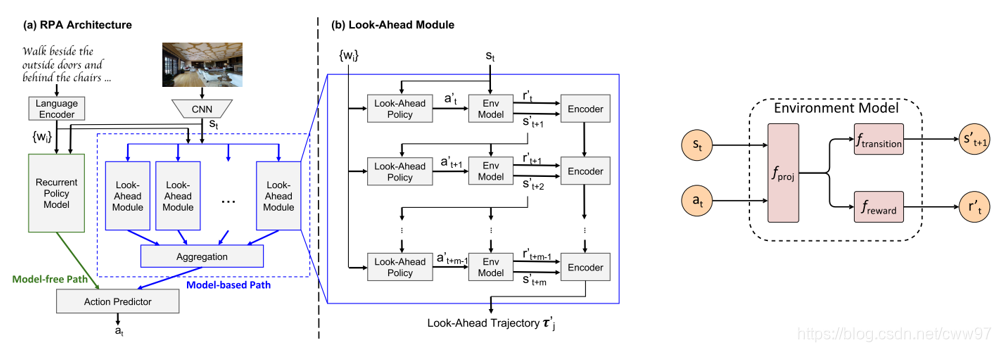
右边蓝色的是强化学习中的model-based方法,其基本原理如图5{reference-type=“ref”
reference=“Fig.RPA”}的右图所示,model-based本质是对智能体所处的环境进行建模,建模的理想结果如公式[equ_lbyl_env_model]{reference-type=“ref”
reference=“equ_lbyl_env_model”}:
KaTeX parse error: Undefined control sequence: \label at position 1: \̲l̲a̲b̲e̲l̲{equ_lbyl_env_m…
可以正确模拟出智能体做出一个动作之后环境对应的变化与即时reward,如果建模的效果非常好的话可以认为我们的环境是全知的,那么在这样一个环境模型中理论上是可以得到最优解的。对应的,model-free方法并不会对环境建模,只管一步一步的action,这是两类方法的本质区别,前些年一直流行model-free方法,因为其已经具有了很好的效果且对环境建模非常困难。
在得到了model-free与model-based方法预测出的action的分布,在action-predictor中对两个模型得到的path进行了融合,简单的说就是一个以softmax为结尾的小的网络。两个模型的决策过程是独立的,只在最后一步进行协同,这是一个典型的模型融合方法。该方法在数据集中达到了0.23的SPL,相对baseline提升了0.05。
Speaker-Follower {#sec_speaker_follower}
第二个冲榜成功的是[@Fried],该方法提出了Speaker-Follower模型。回忆一下原数据集中的数据来源,路径轨迹由环境中游走sample而来,自然语言数据由人工标注而来。那么seq2seq的模型便可以使用监督学习的方法分别训练出从路径到指令或者从指令到路径的模型,在该文章中这两个模型分别叫Speaker和Follower,Speaker根据路径输出对应的语言标签,Follower负责根据输入的文字指令输出路径,这是两个seq2seq模型。训练过程分为两步:首先使用数据集中数据训练Speaker(图[
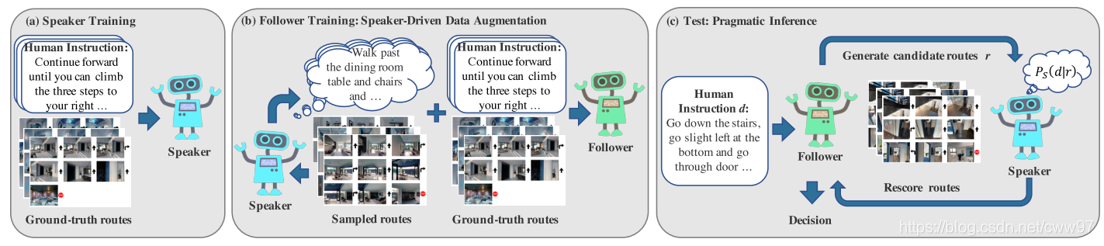
Fig.speaker_follower]{reference-type=“ref”
reference=“Fig.speaker_follower”}左),使其具有根据路径输出指令的功能。第二步在环境中采样路径,并使用Speaker为其生成自然语言指令,然后用这生成出的数据与原数据集一起训练Follower,使用的思想与backtranslation非常接近,是一种数据增强的手段。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ioYolEu-1578753807548)(image/speaker_follower.png)]{width=“100%”}
[[Fig.speaker_follower]]{#Fig.speaker_follower
label=“Fig.speaker_follower”}
最终测试过程如图[Fig.speaker_follower]{reference-type=“ref”
reference=“Fig.speaker_follower”}的右边,首先Follower根据输入的语言指令生成一系列路径的候选项,由Speaker为这些路径在输出语言指令label,根据其对原label的还原度为每一个候选项重新打分然后选取得分最高的作为这一步骤的action输出。
该文章对环境的action空间做了一点改变,原本的左转右转只能僵硬的旋转90度,该文章将其改成了任意角度,加大了action空间的自由度,使得其可以做出更加精确的决策。Speaker-Follower模型达到了0.28的分数,相对前文提升了0.05。值得注意的是,该方法的模型耦合度非常低,是一个非end-to-end的方法。
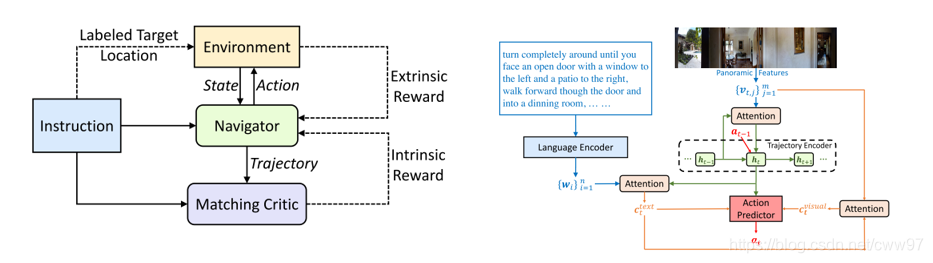
Reinforced Cross-Modal Matching(RCM) {#sec_rcm}
之前说过环境给的反馈机制非常的模糊,智能体很难知道当前已经执行的action与输入的语言指令是否匹配。针对这个问题[@Wang2019]提出了一个跨模态的匹配评价机制。其基本算法如图6{reference-type=“ref”
reference=“Fig.RCM”}左图,抛开下面的Matching
Critic不谈,这就是一个基础的seq2seq模型,不过该方法对其做了一个改进如图6{reference-type=“ref”
reference=“Fig.RCM”}右边所示,相对于先前的seq2seq模型,RCM方法率先在这个模态融合的任务中使用的3attention对其的机制,图像与先前的轨迹对齐,对其后再与语言指令对齐,对其后的信息再与图像feature对其,多次对齐后输入给Action
Predictor,多次对齐后模型可以更加精确的对跨模态的数据(图像、自然语言、轨迹)进行理解。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ro8JrokM-1578753807549)(image/RCM.png)]{#Fig.RCM
width=“100%”}
另外,为了解决刚刚所述的语言与指令的匹配问题,这篇文章引入了Matching
Critic机制,其基本框架与CV领域的自动编码器(autoencoder)非常接近,利用一个end-to-end的方法同时训练encoder(language
to trajectory)与decoder(trajectory to
language),其损失函数就是复原损失(reconstruction
loss)。并以此为一个新的评价reward与环境给的reward一起给agent去决策。加入更多的监督信息,这利用了actor-critic方法的基本思想。
除了加入更多的监督信息以外,RCM还结合了自监督模仿学习,这属于强化学习方向的一个优化:对于一个从未见过的全新的环境,智能体先在环境中预先探索一下然后做测试,可以极大的提高效果,不过这有些考前作弊的嫌疑,所以在作比较的时候去除了这个机制与前文的方法比较。在不加预探索的情况下RCM达到了0.38的分数,飞跃的提升;加了预探索之后达到了爆炸式的0.59,该文章获得了2019CVPR的最佳学生论文奖,成为新一代sota。
Self-Monitoring
R2R数据集给的自然语言指令的平均长度为30个词,如此长的一连串的指令往往让智能体很难判断当前总任务完成了多少。[@Ma2019]提出了一个SELF-MONITORING模型来解决这一问题:在智能体做下一步决策时候问自己三个问题:1)
指令的哪些部分是已完成的;2)那句话对应这下一步的action;3)哪个方向对应着这句话的方向?
模型如图7{reference-type=“ref”
reference=“Fig.self-monitoring”}所示,左边是处理语言输入的LSTM,与先前稍有不同的是这里使用了位置编码器(Positional
Encoder)使得语言信息自带注意力信息:
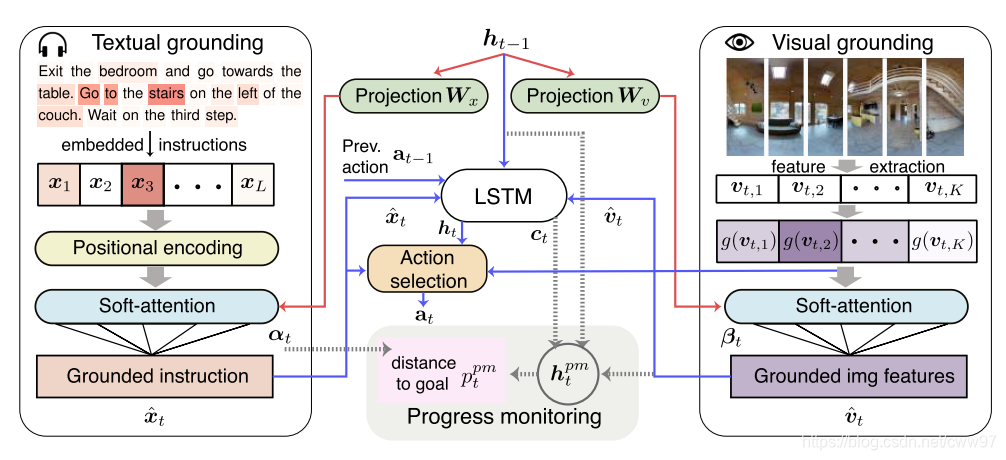
![Self-Monitoring算法结构。图片来源[@Ma2019][]{label="Fig.self-monitoring"}](image/self_monitoring.png) {#Fig.self-monitoring
{#Fig.self-monitoring
width=“100%”}
对应的图像模型也做了类似的处理:
结合两者的信息中间的LSTM输出的并不是aciton而是把hidden statt给action
predictor,再结合三者信息做出决策。本质上依然是seq2seq模型的一个变体。该文章的核心在图下面的一个很小的Progress
Monitoring,即进度监视器,通过计算在图中距离起点的最短路距离来评估距离终点的距离,以此回答本节前面提到的两个问题。本文发表与RCM模型后面且最终效果并没有比上RCM,但由于其优化的点没有前人没有提过且确实有效,故发表在了2019年的ICLR。
Environmental Dropout
在基础的神经网络中有一个dropout方法来防止模型过拟合,[@Tan2019]提供了一个对环境进行dropout的方法来做数据增强的方法。首先套用前文的seq2seq模型(包含优化部分)训练agent,然后删除/遮挡住环境中的一部分feature比如说椅子(如图[Fig.env_dropout]{reference-type=“ref”
reference=“Fig.env_dropout”}的左图),这相当于创造了一个新环境,然后在新环境中随机采样轨迹数据再利用3.3{reference-type=“ref”
reference=“sec_speaker_follower”}中提及的Speaker生成轨迹对应的语言标签。经过这么一个过程有了新的环境与新的数据,可以进一步加强对agent的训练。这是一种数据增强手段,不过由于其遮挡了一部分的feature,agent可能不得不通过其他feature来做出判读或者"猜"被遮挡的为何物,这迫使agent去学习更高级的feature,或许也起到了抗过拟合的效果。
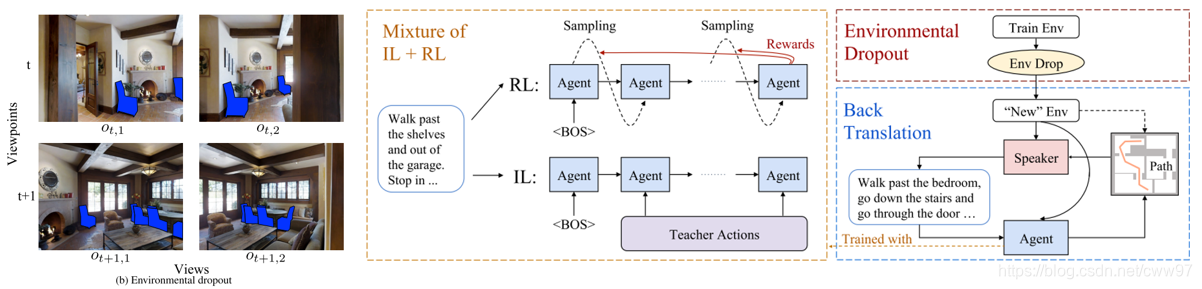
![左图:EnvironmentDrop示例;中:强化学习结合模仿学习;右:训练过程。图片来源[@Tan2019]](image/env_dropout.png) {width=“100%”}
{width=“100%”}
[[Fig.env_dropout]]{#Fig.env_dropout label=“Fig.env_dropout”}
另外,3.4{reference-type=“ref”
reference=“sec_rcm”}中提到了结合强化学习与自监督模仿学习,这篇文章结合了强化学习与模仿学习,将数据自带的轨迹作为专家信息给智能体让其学到专家信息的思考模式。最后简单加权合并reward。该方法突破性的取得了0.47的得分。
Auxiliary Reasoning Tasks
在2019年末,[@Zhu2020]将先前的所有方法做了一个集成,首先结合[@Wang2019]中对seq2seq的三对齐机制与[@Tan2019]中的结合强化学习与模仿学习,并将整个场景建成的图的结构加入,图8{reference-type=“ref”
reference=“Fig.auxRN”}中不看Auxiliary Reasoning中
的部分,成为目前该问题中的seq2seq的一个基本形态。
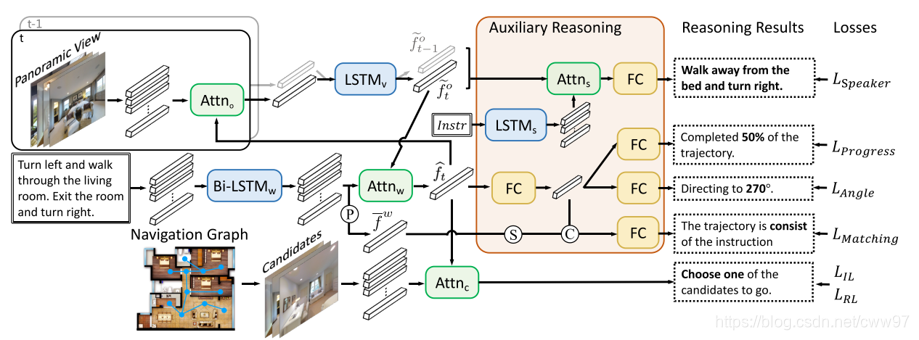
![结合有理由的辅助任务进行的视觉语言导航。图片来源[@Zhu2020][]{label="Fig.auxRN"}](image/AuxRN.png) {#Fig.auxRN width=“100%”}
{#Fig.auxRN width=“100%”}
然后加入四个辅助任务:1)[@Fried]中的Speaker
Loss,估计还原度;2)[@Ma2019]中的进度监控loss,来评估当前任务进度;3)[@Ma2019]中的角度loss,来判断下一步如何转向;4)[@Wang2019]中的Matching
Critic,判断当前轨迹与指令是否匹配;具体损失函数的形式与原文做了些改动来适应新的算法框架。相对于前文不同的是,该算法是end-to-end的,即刚刚所述的四个损失函数都能反向传播到起点。在seq2seq的基础上加入各种辅助任务来帮助智能体做出决策。最终该文章获得了0.51的分数,成功刷榜,于2019年11月18日第三次提交,感觉是预约了2020CVPR。上文讲的方法的得分如图9{reference-type=“ref”
reference=“Fig.results”}所示
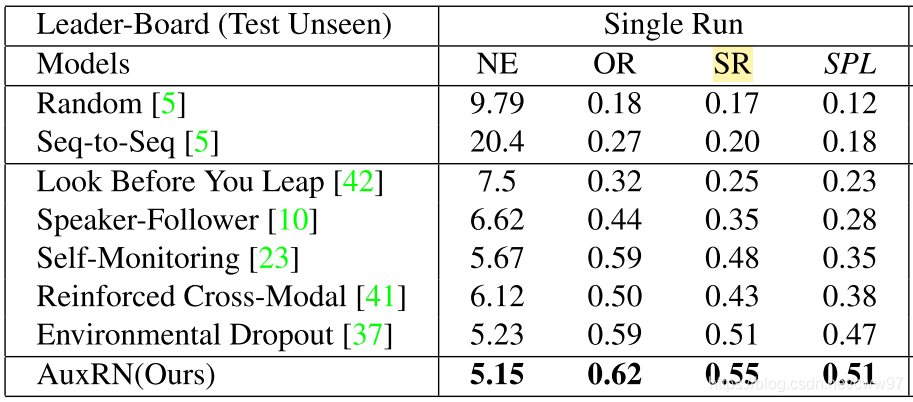
![方法评测结果。图片来源[@Zhu2020][]{label="Fig.results"}](image/results.png) {#Fig.results width=“60%”}
{#Fig.results width=“60%”}
总结
观察下来所有的方法都没有逃开seq-to-seq的基本架构,这是由该问题的输入输出决定的。但是在这个基本架构上针对这个问题还是可以做一些优化的。另外本文提及的所有方法对算法做的改进大致可以分为三类:
-
对齐:包括轨迹于指令对齐、任务进度的对齐
-
数据增强:使用自监督半监督发方法
-
强化学习:结合model-free与model-based、结合模仿学习
另外对于整个视觉语言导航任务数据集的发展而言,人工标注的自然语言永远是最自然的,模拟器在一步步的往逼真度越来越高的靠。这个工作变得越来越costly。那么我们如何生成接近自然语言的数据标签,成为这种问题的一个新的方向,能否用自监督的方法去生成,自监督学习在CV领域已经有了很多的工作,然而在NLP领域目前并不多,主要由于先前需求不够硬且效果没有监督学习的好,面对构造数据集的代价越来越大、且无标签数据的没有代价,自监督一定是一个未来。
任务数据集的发展而言,人工标注的自然语言永远是最自然的,模拟器在一步步的往逼真度越来越高的靠。这个工作变得越来越costly。那么我们如何生成接近自然语言的数据标签,成为这种问题的一个新的方向,能否用自监督的方法去生成,自监督学习在CV领域已经有了很多的工作,然而在NLP领域目前并不多,主要由于先前需求不够硬且效果没有监督学习的好,面对构造数据集的代价越来越大、且无标签数据的没有代价,自监督一定是一个未来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号