raft算法
raft 算法
raft是一种分布式一致性算法,公司项目中使用到了,个人不是很了解,记录一下学习到的相关知识。
分布式一致性算法要解决的问题
多台服务器组成的一个集群,统一对外部提供服务,由于是多个服务器,那么服务器之间肯定要保证提供出去的数据都是一致的,不能从A服务器读出来的数据是一种,从B服务器读出的数据又是另一个。所以,保证各服务器节点之间的数据同步是很重要的。
核心问题:
- 服务稳定性问题,server的状态可能不稳定,随时有可能宕机。
- 网络有问题,server之间的网络波动,同步请求丢失。
- 网速问题,数据在server之间的传输速度不一致,日志顺序难以保证。
分布式系统的CAP理论(不可能三角)
一致性(consistency)、可用性(availability)和分区容错性(partition tolerance)不能同时满足,常常需要根据需求做出取舍。
两阶段决议
在发起决议前,会先进行一次准备阶段,也就是确认下当前有哪些节点可以参与决议,将准备阶段的消息汇总后,再进行正式的决议,一般会使用大多数的方式来决定。
raft算法的基本组成
- 多个server共同选举产生一个leader,负责响应客户端的请求。
- leader通过一致性协议,将客户端的指令转发到集群的所有节点上。
- 每个节点将客户端的指令以entry的形式保存到自己的log日志中,此时entry是uncommited(未提交)的状态。
- 当多数的节点共同保存了entry后,就可以执行entry中的客户端执行,提交到状态机中,此时entry更新为commited状态。
状态机制
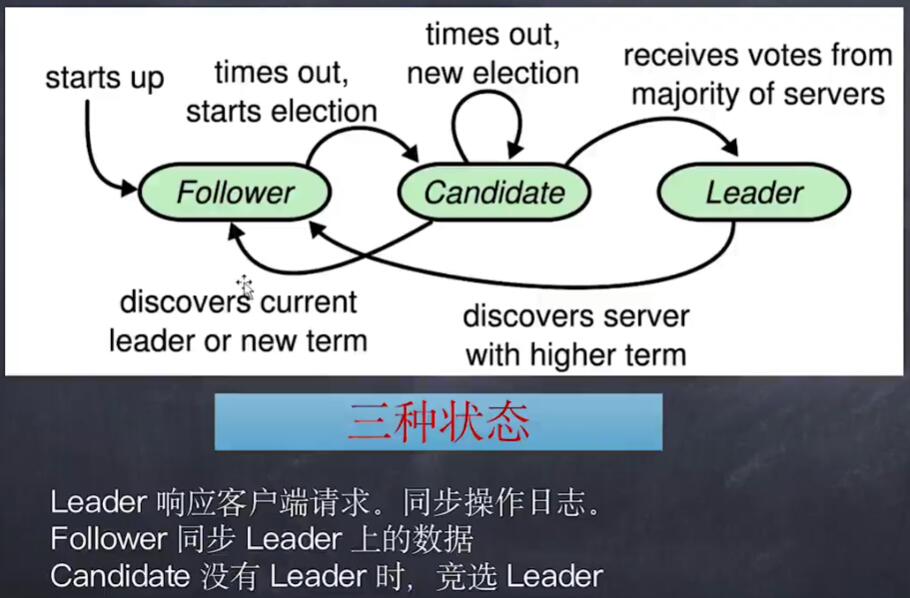
在最开始时,所有的节点都是follower状态,此时会等待接收leader发送的心跳请求,如果经过一段时间没有leader发来心跳请求,那么follower会开始发起选举,并将自己的状态设置为candidate,即在竞选的状态。
在竞选状态会有三种情况,
- 收到了大多数的投票,那么自然而然地成为了leader,并将自己的状态转换为leader。
- 收到了其他leader发送来的心跳或者新的任期又开始了,那么就知道了自己已经当不成leader了,重新退回follower状态。
- 如果直到超时都没有收到大多数的投票,也没有收到其他消息,那么就维持自己当前的竞选者状态。
当拿到大多数的投票后,自身状态就变成了leader,那么就需要行使leader的工作,向其他节点发送心跳,此时其他节点就会退回到了follower状态。
另外,当在任期间收到了其他节点发送来的心跳,那么就认为自己的任期结束了,或者已经有其他节点又当选了,那么自己就退回到follwer的状态。
可以看到,整个的流程就是一个有着三个状态的状态机。
具体的,每个节点会有两个计时器(选举计时器和竞选计时器),计时器会随机设定在150~300ms之间,一旦选举计时器超时,就会开启一个选举,将自己的状态置为竞选者,然后将任期加一,并投给自己一票,再向其他节点要求投自己一票。其他节点根据规则判断是否同意(比如比较任期是否比自己记录的大),如果同意,就将自己的term(任期)设置成和同意的节点任期一致,并且表明自己投给了某个节点。
如果恰好有两个节点同时开始竞选,或者说节点都没有获取到大多数的投票,那么这一个任期就没有leader产生,此时的服务是不可用的。在自身状态是竞选者身份时,竞选计时器就会开始计时,当计时结束时,会重新再开始下一轮竞选,因为计时器的时间是随机设置的,那么就大概率能避免再次出现同时竞选的情况了。
数据存储
在选举出一个leader后,整个集群进入了可用状态(在选举阶段是不可用的,无法响应客户端的数据请求),此时客户端向leader发送了一个数据请求,比如写入了一个整型值42,leader节点在收到这个请求后,并不会立即执行,而是将这个请求写入到了log日志中,也就是上面提到的entry,然后在向其他节点发送心跳时,带上这个请求,于是其他节点也获得了这个请求,其他节点在处理了这个请求后,会主动发送消息给leader,意思是告诉leader我收到了这个请求了,leader节点在等待收到多数节点的回复后,知道这个数据已经被多数节点收到了,那么就可以确认这个请求已经可以正式执行了。其他非主节点在发送消息给leader后也不会真正执行这个请求,而是等到leader在下一次心跳过来时,携带了信息“我已经执行完了,你们也执行吧”,非主节点才会各自真正执行这个请求。
脑裂
因为网络或其他问题,导致同一个集群中分成了两部分,两者无法互相通讯,那么leader所在的一部分在正常工作,而另外一部分在长时间收不到leader的心跳后选举计时器超时,于是按照上面的流程各自选出来一个leader,这就在一个统一的集群服务中产生了两个主节点,数据的一致性无法保证了,是不可接受的。
raft的数据存储方式可以某种程度解决这一问题,请求真正被执行的前提是必须获得大多数节点的接收到了的消息,那么数量较少的一方的请求因为无法获得多数节点的回复,就始终无法真正被执行。
在集群修复之后,此时两部分重新可以互相通讯了,两个leader自然都会向对方发送心跳,在收到对方的心跳后,常用方式是将自己的任期和其进行对比,如果对方的任期更大,那么认为对方是最新产生的leader,那么旧的leader就乖乖地退回到follower的状态,并开始同步新leader的数据。
这种方式优先保证了数据的一致性,而可能无法保证数据的绝对安全(旧的leader产生的数据被丢弃了)。
raft的五条公理
- 一个任期只能选举出一个leader
- leader不会覆盖日志,而只会追加日志。
- log matching。通过任期和索引,可以确定所有的相同日志在不同节点是都在相同位置(entry)。
- 如果entry在某个任期被leader提交到状态机一次,那么后续的leader的任期中,这个entry也一定是提交的。历史不可篡改。
- 如果entry被leader提交到了状态机中,那么后续不可以再有提交到相同位置的不同内容的entry。
基础数据结构

基础RPC请求



 浙公网安备 33010602011771号
浙公网安备 33010602011771号