

一个简单的基于内容的文本文件搜索引擎
才来博客园不久,不知道这里的气氛如何。
先发一个学生作业,当作是第一篇文章吧。
这个项目一共费时4天时间,主要是实现如下需求。
- 实现几个独立的搜索引擎,期中包括对文本文件中文本的扫描,计算文件和关键词组的接近程度。每个搜索引擎采用不同的做法,属于独立线程。
- 有图形界面,form。
- 有一个投票模块,根据不同搜索引擎得到的结果进行投票,返回多数支持的结果,要求总能得到多数支持的结果。
- 最后打开结果文件。
本项目主要采用了如下的一个架构方案
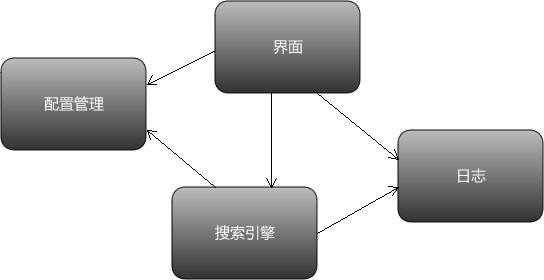
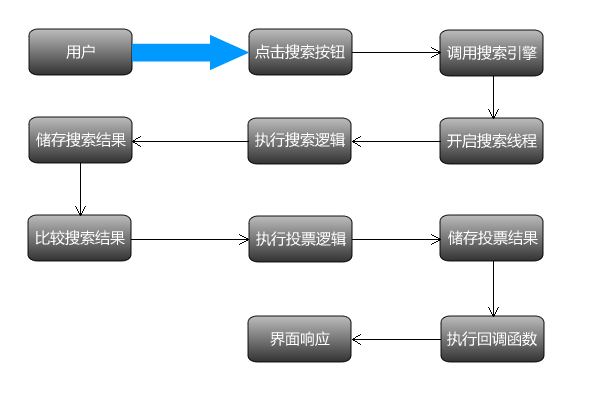
如果用户使用本软件,会产生如下的一系列逻辑
搜索引擎模块一共有4个搜索类,他们拥有一个共同的父类

投票类的主要逻辑:
1.将引擎的搜索结果按照引擎类型进行分类
2.得出每种分类的排序结果
3.将每种结果的最优值进行统计,得出多数支持的最优值
4.返回最优文件的路径
运行效果
所要搜索的文件夹

文件内容

启动程序

点击浏览按钮

选择要搜索的文件夹

查找范围显示出路径

输入关键字

点击搜索按钮,弹出最优结果的路径

附上程序(.net framework3.5 required)
/*2009.6.15编辑****************************************/
/****************************************************/
-------------
VVii: When It Comes To Be
