
kafka笔记
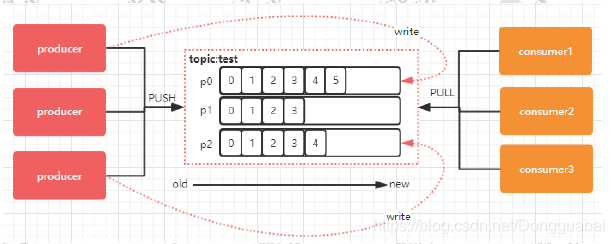
topic(主题)和partion(分区)
topic:是消息的某一个类别,对消息进行分类(是一个消息存储的逻辑概念,可以认为是一个消息的集合,每条发送到kafka集群的消息都有一个类别。在物理上,不同不同的topic的消息是分开存储的,每个Topic可以有多个生产者向其发送消息,多个消费者可以消费同一个topic中的消息)
partion:每个topic可以划分成多个分区,消息存储在分区的某个位置,使用offset(偏移量)进行标号,通过offset来保证分区中消息的顺序
场景->需求->解决方案->应用->原理
earliest,latest,none
当消费者之前消费过数据,提交过offset时
earliest,latest,none会从上一次提交的offset处消费消息
当消费者之前没消费过数据时
earliest会从该分区最开始offset消息开始消费(从头开始消费数据),如果最开始的消息offset是0,那么消费者的offset就会更新为0
latest 从生产者新添加的消息出开始消费,旧的消息不会被消费
none:启动消费者时,该消费者所消费的主题的分区没有被消费过,会抛出异常
kafka rebitmq,mq他们的不同,选择那个使用
kafka的leader选举
(zookeeper维护了一个ISR集合,该集合中存放分区副本,ISR集合中的副本必须和leader分区同步,当副本node宕机或者数据落后太多,该副本会从ISR中删除,当leader节点宕机,会从ISR集合中的follower选择一个作为leader.
ISR中follower成为leader的方式
follower会竞争在zk中注册目录文件(只有一个follower会注册成功),注册成功的follower成为leader)
zookeeper维护了一个ISR(in -sync replicas)集合,ISR是保存分区node的集合,如果node宕机了或数据落后太多,leader会将node节点从ISR集合中删除,只有ISR中的follower中的节点才能曾为leader节点,这样可以避免数据落后太多的follower成为leader,事实上,成为leader节点的follower节点必须和leader数据同步,
Leader节点的切换基于Zookeeper的watcher机制,当leader宕机的时候,在ISR中的follower节点会竞争在zk中创建文件目录(只会有一个创建成功),创建成功的follower会成为leader
https://blog.csdn.net/dcm19920115/article/details/93381346
https://kafka.apachecn.org/intro.html

