软工实践——结对作业2【wordCount进阶需求】
附录:
一、具体分工
- 我负责撰写爬虫爬取信息以及代码整合测试,队友子恒负责写词组词频统计功能的代码。
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 880 | 1170 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 120 |
| • Design Spec | • 生成设计文档 | 20 | 10 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 60 |
| • Design | • 具体设计 | 60 | 100 |
| • Coding | • 具体编码 | 400 | 510 |
| • Code Review | • 代码复审 | 60 | 90 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 100 | 180 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 45 |
| 合计 | 880 | 1170 |
三、解题思路与具体实现说明。
1、爬虫使用
- 因为之前从来没有接触过爬虫和python代码,所以自己上网搜索了网课。然后看网课一句一句写的代码,用谷歌浏览器的“检查”功能查看要爬取内容在网页中属于什么元素并进行相关爬取。(可能看上去写得"很丑"并且效率不太高)。大概爬取了10多分钟的信息,爬下来979篇论文标题和摘要存入result.txt文件中,下面是我的爬虫代码:
import requests from urllib.request import urlopen from bs4 import BeautifulSoup txt = open(r'C:\Users\Administrator\Desktop\result.txt','w',encoding='utf-8') #打开文件 i = 0 def getPaper(newsUrl): #获取相关信息的函数 res = requests.get(newsUrl) #打开链接 res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #把网页内容存进容器 Title = soup.select('#papertitle')[0].text.strip() #找到标题元素爬取 print("Title:",Title,file=txt) Abstract = soup.select('#abstract')[0].text.strip() #找到摘要元素爬取 print("Abstract:",Abstract,"\n\n",file=txt) return sUrl = 'http://openaccess.thecvf.com/CVPR2018.py' res1 = requests.get(sUrl) res1.encoding = 'utf-8' soup1 = BeautifulSoup(res1.text,'html.parser') for titles in soup1.select('.ptitle'): #返回每个超链接 t = 'http://openaccess.thecvf.com/'+ titles.select('a')[0]['href'] print(i,file=txt) getPaper(t) #循环打开每个子页面并进行爬取 i=i+1
2、代码组织与内部实现设计
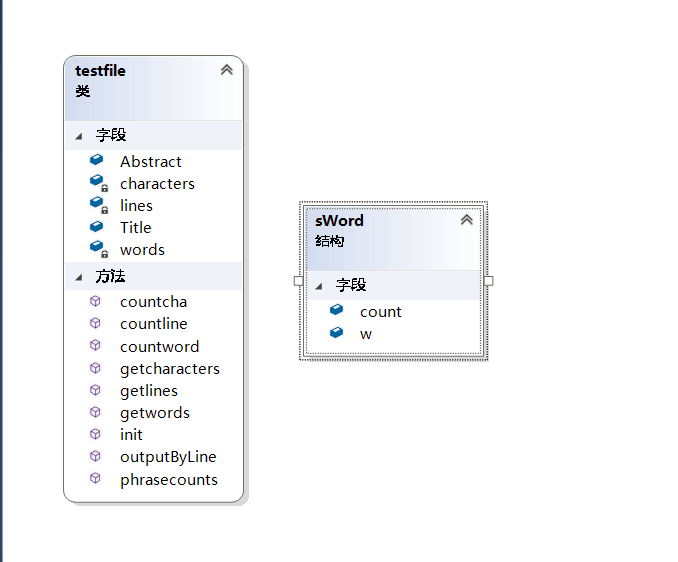
- 代码包含一个主要的类testfile以及实现功能的函数,类图如下所示。
- Abstract和Title是分别存放摘要和标题内容的字符串。
- outputByLine函数是在判断词组词频时能够按行返回文本内容并且剔除“Title: "和"Abstract: "。
- phrasecounts分割词组并且计算词组数目与词频。
- sWord结构体用作对词汇进行相关排序的容器。
3、关键算法的实现思路以及代码解释
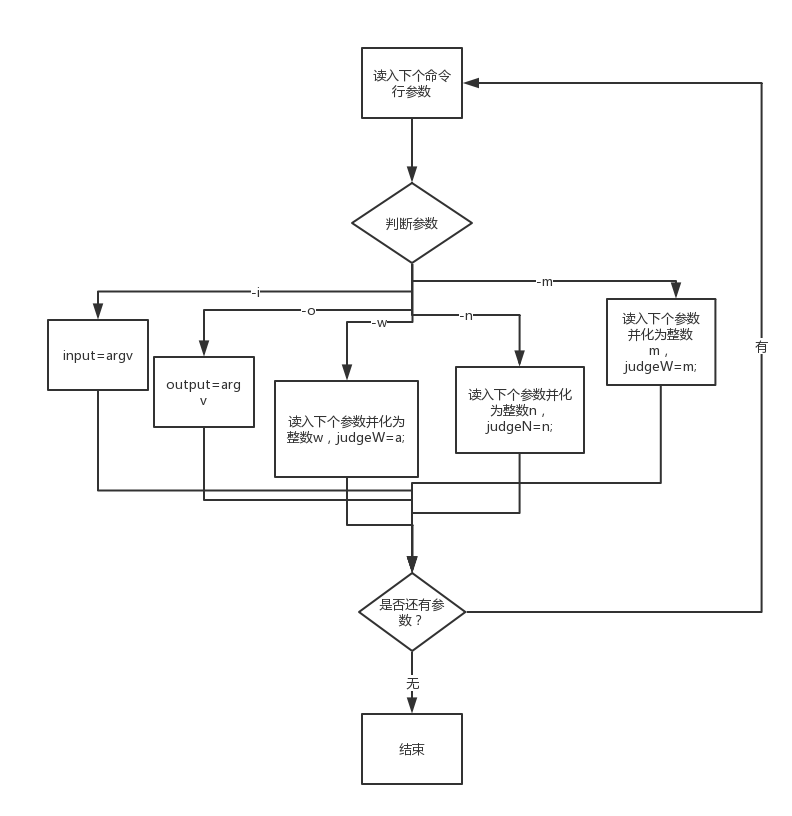
(1)命令行参数的判断
- 功能流程图如下:
- 功能设计代码以及具体思路注释:
while (1) //循环判断命令行参数 { i++; if (i == argc) break; if (argv[i][0] == '-') //判断当前参数首字符是否为'-' { switch (argv[i][1]) //判断当前参数第二个字符 { case 'i': { i++; input = argv[i];//第二个字符为i时输入下一个参数赋值给input break; } case 'o': { i++; output = argv[i];//第二个字符为o时输入下一个参数赋值给output break; } case 'w': { i++; judgeW = atoi(argv[i]);//第二个字符为w时judgeW为下一个参数的整数值留作输出判断 break; } case 'm': { i++; judgeM = atoi(argv[i]);//第二个字符为m时judgeM为下一个参数的整数值留作输出判断 break; } case 'n': { i++; judgeN = atoi(argv[i]);//第二个字符为n时judgeN为下一个参数的整数值留作输出判断 break; } default: cout << "输入参数有误" << endl; break; } } }
- 配合命令行参数判断的输出代码:
if (judgeW == 0) { if (judgeM == 0) //非权重词频统计 { f1 = f1.countline(input, f1); f1.Abstract = changeDx(f1.Abstract); f1.Title = changeDx(f1.Title);//大小写转换 f1 = f1.countword(f1, f1.Title, 1); f1 = f1.countword(f1, f1.Abstract, 1); } else //非权重词组词频统计 { f1 = f1.outputByLine(input, f1, 1, judgeM); } } else { if (judgeM == 0) //权重词频统计 { f1 = f1.countline(input, f1); f1.Abstract = changeDx(f1.Abstract); f1.Title = changeDx(f1.Title);//大小写转换 f1 = f1.countword(f1, f1.Title, 10); f1 = f1.countword(f1, f1.Abstract, 1); } else //权重词组词频统计 { f1 = f1.outputByLine(input, f1, 10, judgeM); } } if (judgeN == 0)//如果没有定义n那么按默认输出 outCome1(ww, num, output, f1); else { if (judgeN > f1.getwords()) { cout << "输入的n值超过了文本的所有单词数,将为您按序输出文本的所有单词" << endl;//对于参数过大的错误判断 outCome2(ww, f1.getwords(), output, f1); } else { outCome2(ww, judgeN, output, f1);//如果定义了n那么输出前n个 } }
(2)词组词频统计和权重词频统计的实现
- 词组词频统计算法的设计流程图:

- 具体的代码实现和思路解析
testfile testfile::phrasecounts(string temp, int t, int quan, testfile f1) { int word = 0; int i = 0; int j = 0; long int n = 0; int m = 0; string sumwr = "";//初始化一个存放词组的字符串 n = temp.length(); char x[10]; for (j = 0; j < n; j++) { if (temp[j] >= 'A'&&temp[j] <= 'Z') { temp[j] += 32; } } string phrase; int flag = 0, k = 0; int mark = 0, al = 0;//mark用来记录存储的单词数,al用来记录成词组的第二个单词的首字母序号 for (i = 0; i < n; i++) { if (!((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122))) { if (mark > 0) { sumwr = sumwr + temp[i];//如果此时已记录一个及以上的单词,将此分隔符也录入词组字符串 } continue; } else { for (j = 0; j < 4 && i < n; j++) { if (!((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122))) { mark = 0; sumwr = "";//检测到非法单词,重新初始化mark和词组字符串 break; } else { if (j == 0 && mark == 1) { al = i; } x[j] = temp[i++];//temp中存入四个非空格字符 } } if (j == 4) { for (m = 0; m < 4; m++) { if (x[m] < 97 || x[m]>122) { flag = 1; mark = 0; sumwr = ""; break;//判断这四个字符是否都是字母,检测到非法单词,重新初始化mark和词组字符串 } } if (flag == 0)//判断为一个单词 { char *w = new char[100];//存放单词 for (m = 0; m < 4; m++) { w[k++] = x[m];//temp中字符存入w } while (((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122)) && i < n)//继续存入单词剩余字符 { w[k++] = temp[i++]; } w[k] = '\0'; sumwr = sumwr + w;//将单词存入词组字符串数组 mark++; delete[]w; k = 0; if (mark == t) { loadword(sumwr, quan);//如果此时单词存入达到所需数量,将此词组字符串存入map函数,并初始化mark和字符串 word++; mark = 0; i = al;//让i等于存入字符串的第二个单词的第一个字母序号,重新开始查询词组 sumwr = ""; } i--; } else { flag = 0; j = 0; mark = 0; sumwr = ""; } } } } i = 0; f1.words += word; return f1; }
四、性能分析以及改进思路
- 输入的命令行参数为:-i C:\Users\Administrator\Desktop\result.txt -m 2 -n 20 -w 1 -o C:\Users\Administrator\Desktop\output.txt 即对爬取的文件进行词组分割,2个单词一组而后执行权重词频统计并且输出频率最高的前20个词组。
- 性能探查器返回结果
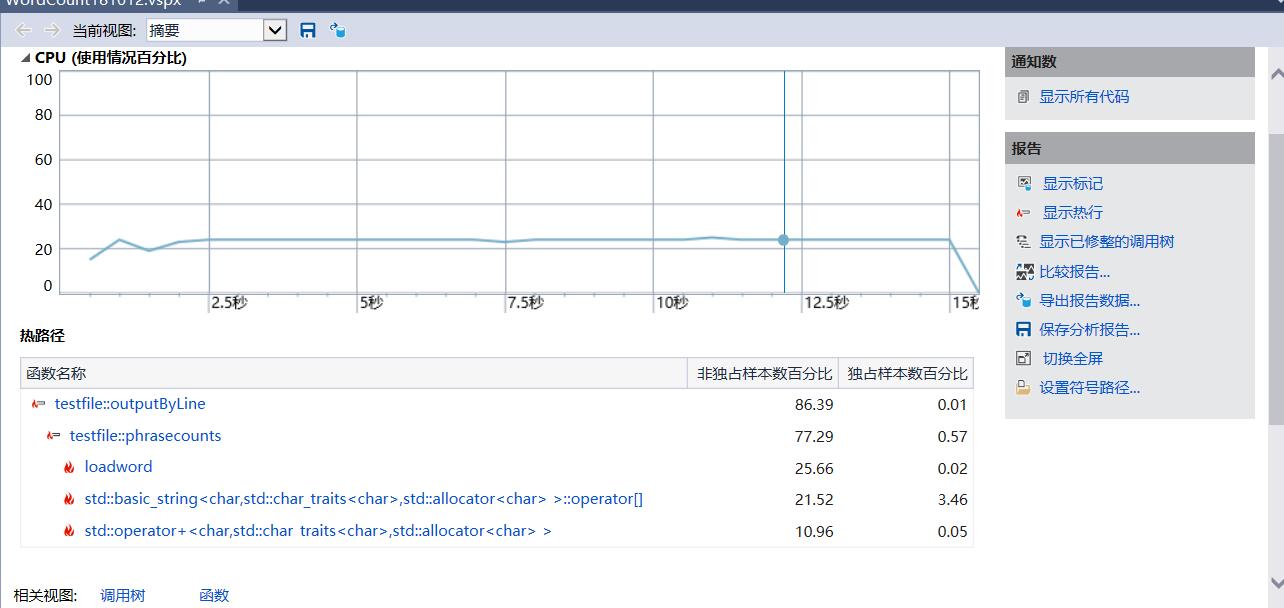
- 因为本次测试执行的是词组分割的词频统计,所以占比最高的函数就是词组分割函数phrasecount。其次本次程序执行时间在15秒到16秒左右,所以还有优化空间。loadword是把词组存入map,这是c++自带的一个统计词频并且按字典排序的容器,如果有能力的话希望自己能用哈希表写一个类似的排序也许能够提高运行效率。
五、单元测试
- 以下对字符数统计,行数统计,单词数统计以及词组分割和词组词频统计四个函数进行单元测试。
#include "stdafx.h" #include "CppUnitTest.h" #include "C:\Users\Administrator\Desktop\软工实践\结对作业2\单元测试\WordCount2\WordCount2\WordCount2\WordCount2.h" #include <iostream> using namespace Microsoft::VisualStudio::CppUnitTestFramework; namespace WordCountTest1 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(phraseCount) { testfile f1; f1=f1.outputByLine("C:\\Users\\Administrator\\Desktop\\result.txt", f1, 1, 3);//按行输出后进行词组词频统计 } TEST_METHOD(wordCount) { testfile f1; f1 = f1.countline("C:\\Users\\Administrator\\Desktop\\result.txt", f1); f1 = f1.countword(f1, f1.Abstract, 1); f1 = f1.countword(f1, f1.Title, 1); } TEST_METHOD(countCharacters) { testfile f1; string a; f1 = f1.countcha("C:\\Users\\Administrator\\Desktop\\result.txt", f1); Assert::AreEqual(f1.getcharacters(), (int)1220332); } TEST_METHOD(countLine) { testfile f1; f1 = f1.countline("C:\\Users\\Administrator\\Desktop\\result.txt", f1); Assert::AreEqual(f1.getlines(), (int)2937); } }; }
- 单元测试通过
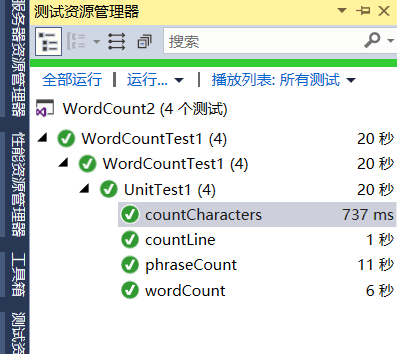
- 观察单元测试图可以看到,在对一百万字符数的文本文档进行统计时,总执行时间要20秒,其中词组分割花费11秒最多,再者就是单词分割,需要6秒。还有很大的优化空间啊。
六、Github签入记录
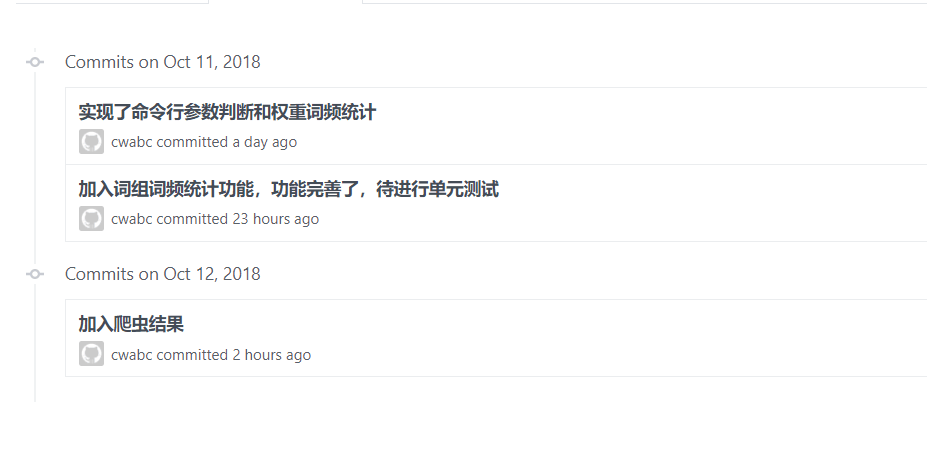
- 共签入了三次。第一次是自己做的那块功能做完后签入。而后队友做的功能完善后,整理合并到代码里再次签入。第三次签入时进行完单元测试并加入爬虫结果。
七、遇到的困难
- 因为我和队友都对于爬虫不熟悉,所以我们一开始决定使用c++来写爬虫,但是在写的过程中遇到较多问题没法解决,决定改用python写爬虫,所以我就去看网课写了一个爬虫。
- 在决定分工写功能模块的时候,队友是在他自己之前个人项目的代码基础上添加的词组词频统计功能,而他的代码和我的代码在函数传递的参数上有很多不同,所以在代码合并的时候出现了很多bug,为此我们讨论了挺久终于把bug解决了。
- 在对问题做需求分析的时候,我们对词组词频统计的要求理解错了,队友在某天晚上肝到了3点(超级拼,点赞,但要注意身体)写了一个各种判断的词组词频统计函数,第二天测试时发现和样例有较大出入。(这时内心是绝望的)所以第二天在重新理解需求之后再次写了一个词组词频统计函数。
八、对于队友的评价
- 我的队友子恒是我的舍友,我觉得他的脑筋很灵活,并且坚持不懈从不抱怨。其实分工上感觉我做得多一些,但是他做的那部分比较难。说实话如果是我写了很久的一个函数,发现需求理解错误要重写,我可能会崩溃哈。所以给舍友及队友子恒赞一个!虽然我们的工作效率都不高,都是代码小渣渣,不过遇到问题时能交换思维也可以成功解决的。
九、学习进度条
| 第N周 | 新增代码行 | 累计代码行 | 本周学习(时) | 重要成长 |
|---|---|---|---|---|
| 2 | 255 | 255 | 11 | 熟悉了c++的一些函数使用以及c++输入输出流 |
| 3 | 105 | 350 | 13 | 初步接触了代码性能分析以及一些调试方法。学习了RP制作原型的方法。 |
| 4 | 0 | 350 | 6 | 本周主要是看邹欣老师的《构建之法》,第一章到第三章。以及组队讨论项目。 |
| 5 | 60 | 410 | 8 | 看网课学习写爬虫。 |
| 6 | 176 | 586 | 12 | 熟悉了命令行参数的传递。初步了解代码单元测试。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号