软工实践第二次作业—Wordcount
Git仓库地址:https://github.com/cwabc/PersonProject-C
一、问题描述
输入一个txt文件名,以命令行参数传入,程序能够统计txt文件中的以下几个指标:
统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
输出的格式为:
characters: number words: number lines: number <word1>: number <word2>: number ...
本次课程实践要求我们实现一个能够统计文本文档词频的控制台程序。需要用到c++中对于文件流的控制。由于自己对于c++的文件流控制不熟悉,并且也对c++的一部分语法有点遗忘,所以开始时花费了比较多的时间查找关于c++文件流控制的资料和方法。在成功导入文本之后,需要对文本进行单词分割,按照要求统计符合规定的单词出现频次,并且把他们按出现频率优先,字典序次之的顺序排列,输出频次最高的前十个单词,并把所有分割出的单词输入到“result.txt"文件中。
所以解决问题的关键要设计一个合理的单词分割算法,准确地分割出单词并存储到对应数据结构中。而后采用恰当的算法给分割出的单词统计频次并且按要求排序。
二、解决方案
1、PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 700 | 990 |
| Development | 开发 | 600 | 890 |
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 220 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 30 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| • Design | • 具体设计 | 30 | 60 |
| • Coding | • 具体编码 | 180 | 200 |
| • Code Review | • 代码复审 | 30 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 200 |
| Reporting | 报告 | 100 | 100 |
| • Test Repor | • 测试报告 | 10 | 10 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 70 |
| 合计 | 700 | 990 |
2、具体实现
(1)头文件和类的定义
c++对文件的控制要加入头文件<fstream>,后续要调用map函数进行排序需要头文件<map>;定义一个文件类,内含公有参数content(即文本文件内容),私有参数characters(字符数),lines(行数),words(单词数),以及若干成员函数。
class testfile { public: testfile countcha(char *, testfile);//计算字符数 testfile countword(char *, testfile);//计算单词数 testfile countline(char *, testfile);//计算行数 int getcharacters(); int getlines(); int getwords(); char *content;//存放文本文件数据 void init(); private: int characters; int words; int lines; }; void testfile::init() { characters = 0; words = 0; lines = 0; content = (char*)malloc(sizeof(char*)*MAXN); }
(2)统计文本文件的字符数以及行数
调用c++语言中的文本文件输入功能,分别以按字符输入和按行输入统计字符数和行数。其中按字符输入按项目要求必须强制读入空格和换行符。并进行文本文件打开与否的差错判断。
testfile testfile::countcha(char *t, testfile f1) { int i = 0; ifstream myfile; myfile.open(t); if (!myfile.is_open()) { cout << "文件打开失败" << endl; } char c; myfile >> noskipws;//强制读入空格和换行符 while (!myfile.eof()) { myfile >> c; if (myfile.eof()) break;//防止最后一个字符输出两次 i++; } f1.characters = i; myfile.close(); return f1; } testfile testfile::countline(char *t, testfile f1) { ifstream myfile; myfile.open(t, ios::in); int i = 0; string temp;//作为getline参数使用 if (!myfile.is_open()) { cout << "文件打开失败" << endl; } while (getline(myfile, temp)) {
if(temp.empty()) continue; i++; } f1.lines = i; myfile.close(); return f1; }
(3)统计单词数并存储单词
统计单词数并逐个把单词存入map关联式容器,可以自动建立word-value的对应关系,查询的复杂度为O(log(n))。map内部自建一颗二叉树具有自动排序的功能。这样单词就能按照字典序排好。并可以返回单词出现的频次。单词分割算法把从文件读入的字符串存入testfile类的公有参数content里,大写转小写,并对content进行单词分割操作,以非字母数字的符号为分隔符,头四个字符为字母作为一个单词。
map<string, int> mapword1;
void loadword(char w[]) { string wr; wr = w; map<string, int>::iterator it1 = mapword1.find(wr);//在map红黑树中查找单词 if (it1 == mapword1.end()) mapword1.insert(pair<string, int>(wr, 1));//未找到单词,插入单词并设定频次为1 else ++it1->second;//找到单词,单词出现频次增加 } testfile testfile::countword(char *t, testfile f1) { int n = 0; ifstream myfile; myfile.open(t); if (!myfile.is_open()) { cout << "文件打开失败" << endl; } char c; myfile >> noskipws; while (!myfile.eof()) { myfile >> c; if (myfile.eof()) break;//防止最后一个字符输出两次 if (c >= 65 && c <= 90) c += 32;//大写字母转小写 f1.content[n++] = c;//把文本文件内的数据存入类的content字符数组中 } myfile.close(); char temp[4]; int i = 0, j = 0, flag = 0, words = 0, m = 0, k = 0; for (i = 0; i < n; i++) { if (!((f1.content[i] >= 48 && f1.content[i] <= 57) || (f1.content[i] >= 97 && f1.content[i] <= 122)))//跳过非字母和非数字字符 continue; else { for (j = 0; j < 4 && i < n; j++) { if (!((f1.content[i] >= 48 && f1.content[i] <= 57) || (f1.content[i] >= 97 && f1.content[i] <= 122))) break; temp[j] = f1.content[i++];//temp中存入四个非空格字符 } if (j == 4) { for (m = 0; m < 4; m++) { if (temp[m] < 97 || temp[m]>122) { flag = 1; break;//判断这四个字符是否都是字母 } } if (flag == 0)//四个字符都是字母的情况,判断为一个单词 { char *w = new char[100];//存放单词 for (m = 0; m < 4; m++) { w[k++] = temp[m];//temp中字符存入w } while (((f1.content[i] >= 48 && f1.content[i] <= 57) || (f1.content[i] >= 97 && f1.content[i] <= 122)) && i < n)//继续存入单词剩余字符 { w[k++] = f1.content[i++]; } w[k] = '\0'; loadword(w);//可以在此处插入一个外部函数返回一个单词存入map红黑树 delete[]w; words++; k = 0; } else { flag = 0; j = 0; } } } } f1.words = words; return f1; }
(4)对map中的单词按出现频次进行排序,输出指定内容,在主函数中实现
定义一个单词结构体sWord,包含单词w和出现频次count。把map中依次返回的单词和对应频次存入sWord中,对sWord按count从大到小排序。在控制台输出指定内容后把单词输出到"result.txt"文件中。释放内存。
struct sWord { string w; int count; };//定义一个用于存放单词及频次的结构体 void merge(sWord *a, sWord *c, int l, int mid, int r) { int i = l, j = mid + 1, m = 1; while (i <= mid && j <= r) { if (a[i].count < a[j].count) c[m++] = a[j++]; else c[m++] = a[i++]; } while (i <= mid) c[m++] = a[i++]; while (j <= r) c[m++] = a[j++]; for (int k = 1; k <= r - l + 1; k++) a[l + k - 1] = c[k]; } void sort(sWord *a, sWord *c, int l, int r) { if (l < r) { int mid = (l + r) / 2; sort(a, c, l, mid); sort(a, c, mid + 1, r); merge(a, c, l, mid, r); } } int main(int argc, char *argv[]) { clock_t start = clock(); int i, num = 0, j; testfile f1; f1.init(); if (!argv[1]) { cout << "未输入文件名或文件不存在" << endl; return 0; } f1 = f1.countcha(argv[1], f1); f1 = f1.countline(argv[1], f1); f1 = f1.countword(argv[1], f1); sWord *ww = new sWord[f1.getwords()];//给结构体分配一个大小为单词数目的动态空间 sWord *temp = new sWord[f1.getwords()]; map<string, int>::iterator it; it = mapword1.begin(); for (it; it != mapword1.end(); it++) { ww[num].w = it->first; ww[num].count = it->second; num++; } sort(ww, temp, 0, num - 1);//把已经按字典序排号按出现频率进行从大到小的归并排序 //输出 ofstream fout; fout.open("result.txt"); if (!fout) cout << "文件打开失败" << endl; cout << "characters: " << f1.getcharacters() << endl; fout << "characters: " << f1.getcharacters() << endl; cout << "words: " << f1.getwords() << endl; fout << "words: " << f1.getwords() << endl; cout << "lines: " << f1.getlines() << endl; fout << "lines: " << f1.getlines() << endl; if (num < 10) { for (i = 0; i < num; i++) { cout << "<" << ww[i].w << ">" << ": " << ww[i].count << endl; fout << "<" << ww[i].w << ">" << ": " << ww[i].count << endl; } } else { for (i = 0; i < 10; i++) { cout << "<" << ww[i].w << ">" << ": " << ww[i].count << endl; fout << "<" << ww[i].w << ">" << ": " << ww[i].count << endl; } } delete[]ww; free(f1.content);//动态空间释放 clock_t ends = clock(); cout << "运行时间 : " << (double)(ends - start) / CLOCKS_PER_SEC << "秒" << endl; return 0; }
(5)代码优化
关于map函数的使用,通过后续的学习知道它也能按频次从大到小输出,这样就节省了开辟单词结构体的空间并节省了给结构体排序的时间,但自己掌握得不好,所以没有使用。对于结构体按从大到小排序,开始时的想法是构建一个最大化堆,但堆排序不是一个稳定的排序算法,会破坏原有的字典序。因此考虑了稳定排序算法中的归并排序,途中出了个bug没有查出原因,这里先采用冒泡排序。后续会加强这方面的学习并改进代码。
三、差错检测
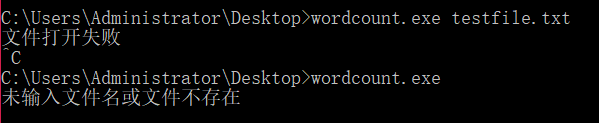
如果从命令行输入的文件名错误,或者当前文件夹下没有对应的txt文件,输出对应的错误信息,并结束程序。
if (!argv[1]) { cout << "未输入文件名或文件不存在" << endl; return 0; }
ifstream myfile; myfile.open(t); if (!myfile.is_open()) { cout << "文件打开失败" << endl; }
四、实例测试
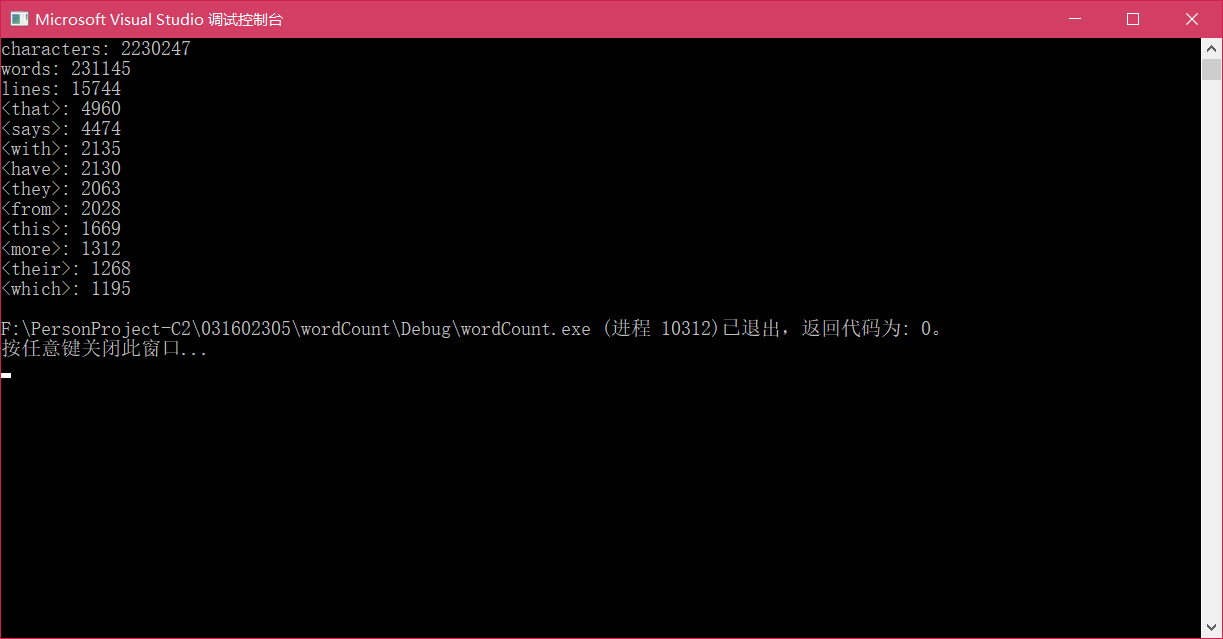
1、测试文件input6.txt
字符数两百万以上的较大文本测试。

2、测试结果
五、类的封装
1、封装testfile类
#ifndef wordcount_h #define wordcount_h class testfile { public: testfile countcha(char *, testfile);//计算字符数 testfile countword(char *, testfile);//计算单词数 testfile countline(char *, testfile);//计算行数 int getcharacters(); int getlines(); int getwords(); char *content;//存放文本文件数据 void init(); private: int characters; int words; int lines; }; #endif
2、功能测试
#include"wordcount.h" #include<iostream> #include<locale> using namespace std; int main() { char filename[10]; testfile f1; cin >> filename; f1.init(); f1 = f1.countcha(filename, f1); cout << f1.getcharacters()<< endl; return 0; }
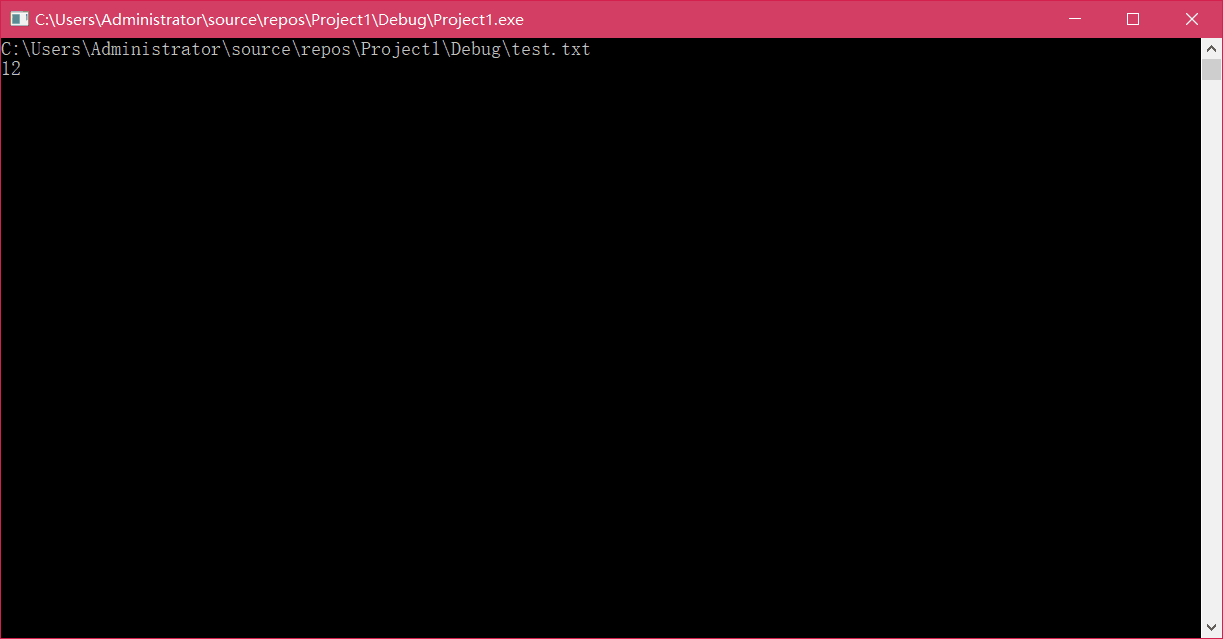
计算字符数功能正常实现。
六、性能分析
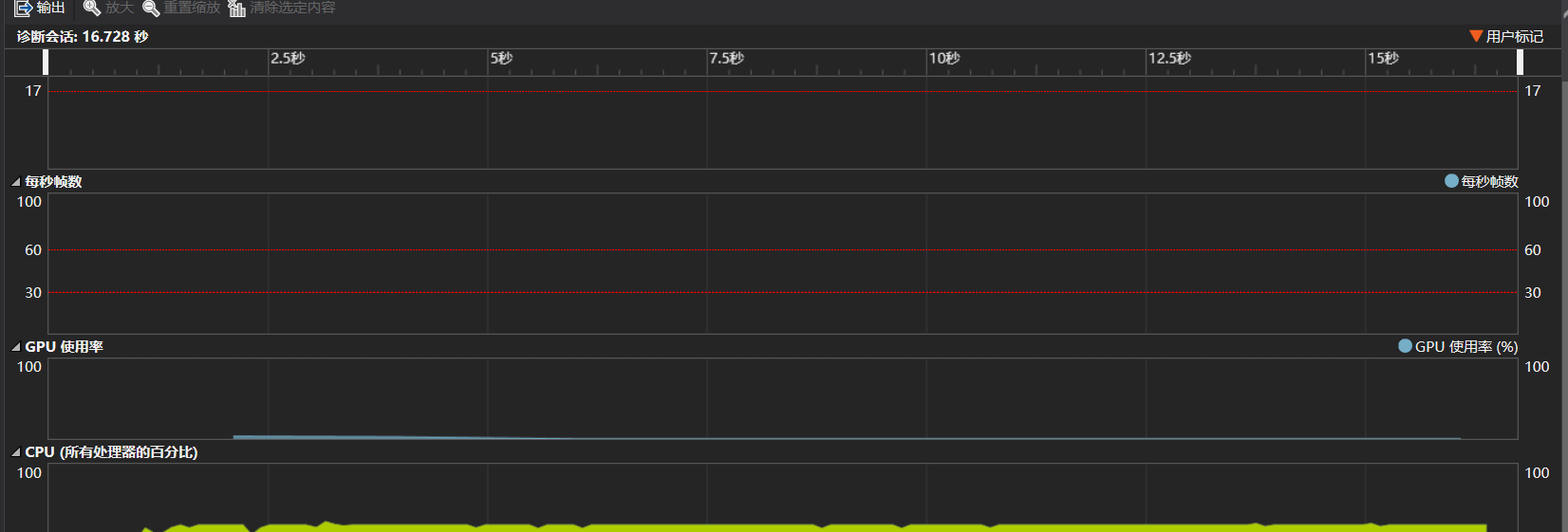
两百万的数据量执行时间为16秒多,已经尽力优化了。。。但是把exe放在桌面上执行时执行时间在5秒内,不知道什么原因。
七、分析总结
通过这次的实践项目,我又复习了一遍c++中的一些语法,并且学会了c++语言中对于文本文件的输入输出控制。但是学习的过程中也意识到自己的算法练习得太少,很多算法道理能明白一些但是就是写不出来,要么就是编译不通过,要么就是未知错误导致程序中止。这是不熟练的体现,今后要加强这方面的学习!
2018-09-18:
增加了博客中关于简单差错检测的描述,把原先的冒泡排序改为归并排序并修改了代码的一些细节。为了实现功能的独立性在各个函数中有对于文本文件的重复读入降低了程序运行的效率。一步步纠错和改进可以认识到自己的不足,也让自己从周围厉害的同学那里学到了不少,我感觉这是选择这门课最重大的意义之一了。我觉得写完作业也确实不能立刻就把它放下了,尤其是敲代码这种,毕竟很多错误我们在一开始执行时自己也不能清楚地知道,但是随着时间流逝会暴露出很多的问题。想着万一以后的学弟学妹们看到我自己漏洞百出的代码恐怕要贻笑大方,我感觉有点慌啊。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号