Flink 源码之 KafkaSource
Flink 源码之 KafkaSource
https://www.jianshu.com/p/8d27f6ede484
https://blog.csdn.net/m0_55685698/article/details/129625141
https://blog.csdn.net/weixin_50835854/article/details/130753784
https://blog.csdn.net/sdut406/article/details/130563537
https://blog.csdn.net/m0_64640191/article/details/129859858
https://nightlies.apache.org/flink/flink-docs-master/docs/connectors/datastream/kafka/
https://www.nuomiphp.com/a/stackoverflow/zh/6375cec70468a652d95f1357.html
https://blog.csdn.net/feinifi/article/details/131268317
https://blog.csdn.net/wang6733284/article/details/125397627
https://blog.csdn.net/hongchenshijie/article/details/108861094
https://www.cnblogs.com/Springmoon-venn/p/15897673.html
https://www.freesion.com/article/44251550526/
https://blog.csdn.net/JinVijay/article/details/123217311
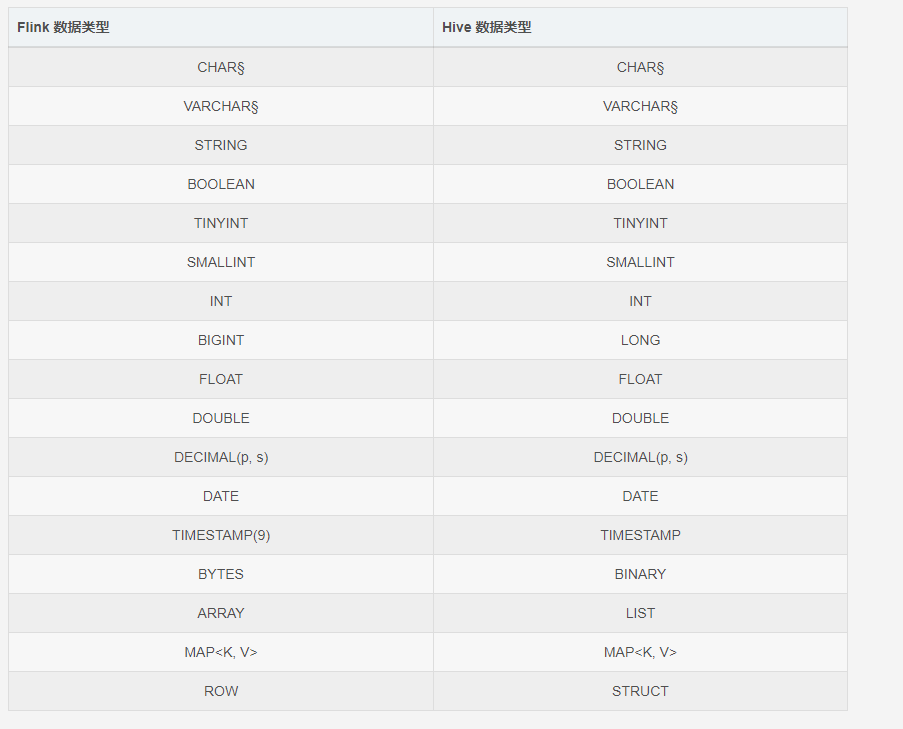

http://blog.itpub.net/70027827/viewspace-2946458/
https://www.cnblogs.com/EnzoDin/p/16743404.html
https://blog.csdn.net/xianpanjia4616/article/details/128310528
https://blog.csdn.net/cuiyaonan2000/article/details/123735223
https://cwiki.apache.org/confluence/display/FLINK/FLIP-265+Deprecate+and+remove+Scala+API+support
https://blog.csdn.net/weixin_45695430/article/details/124244679


https://blog.csdn.net/Yuan_CSDF/article/details/117486259
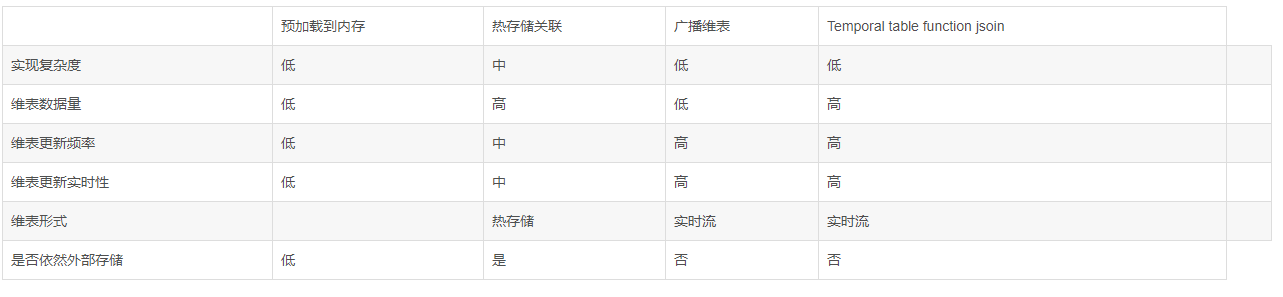
https://cloud.tencent.com/developer/article/1198336
https://www.cnblogs.com/ywjfx/p/14234907.html
https://blog.csdn.net/AnameJL/article/details/131050890
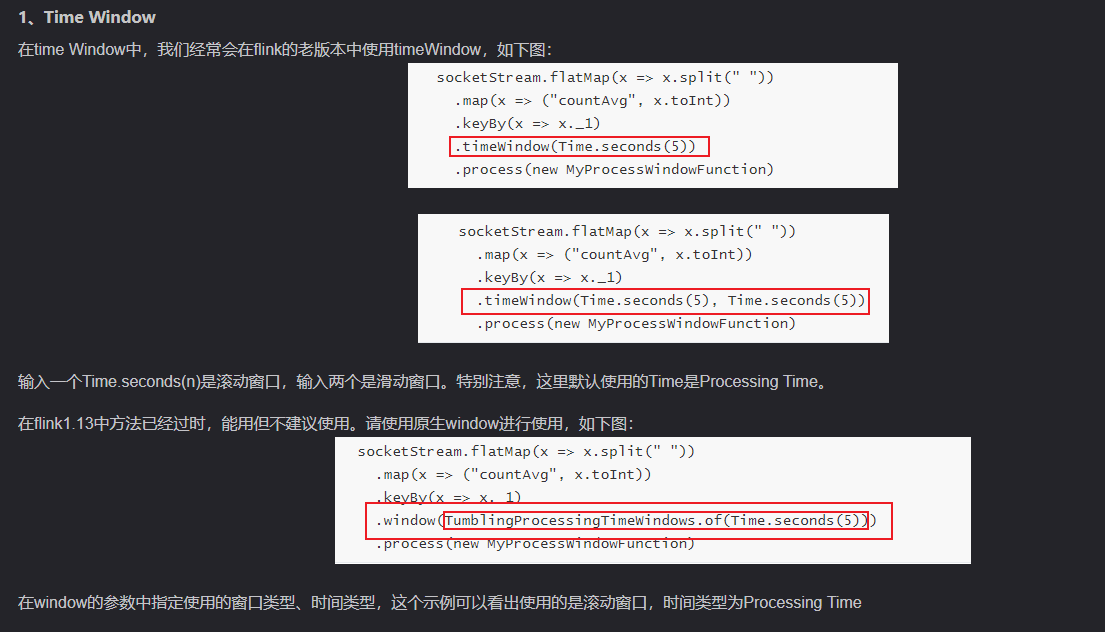
flink Time Window

https://blog.csdn.net/Chenftli/article/details/124164139
性能分析神器VisualVM
https://www.cnblogs.com/wade-xu/p/4369094.html
VisualVM 是一款免费的,集成了多个 JDK 命令行工具的可视化工具,它能为您提供强大的分析能力,对 Java 应用程序做性能分析和调优。这些功能包括生成和分析海量数据、跟踪内存泄漏、监控垃圾回收器、执行内存和 CPU 分析,同时它还支持在 MBeans 上进行浏览和操作。
12款Bean拷贝工具压测大比拼
实验代码 https://github.com/benym/benchmark-test (opens new window)
http://www.zlprogram.com/Show/63/355CEEBA.shtml
get/set: 原生get/set
RpasBeanUtils: 基于Cglib BeanCopier+ConcurrentReferenceHashMap封装、基于ASM字节码拷贝原理
MapStruct: 编译器生成get/set
BeanCopier: 原生Cglib BeanCopier、基于ASM字节码拷贝原理
JackSon: Spring官方JackSon序列化工具ObjectMapper
FastJson: Alibaba Json序列化工具
Hutool BeanUtil: Hutool提供的BeanUtil工具
Hutool CglibUtil: Hutool提供的Cglib工具、基于Cglib BeanCopier、ASM字节码拷贝
Spring BeanUtils: Spring官方提供的BeanUtils、基于反射
Apache BeanUtils: 基于反射
Orkia: 基于javassist类库生成Bean映射的字节码
Dozer: 基于反射、定制化属性映射、XML映射
https://www.cnblogs.com/luckyplj/p/15762273.html
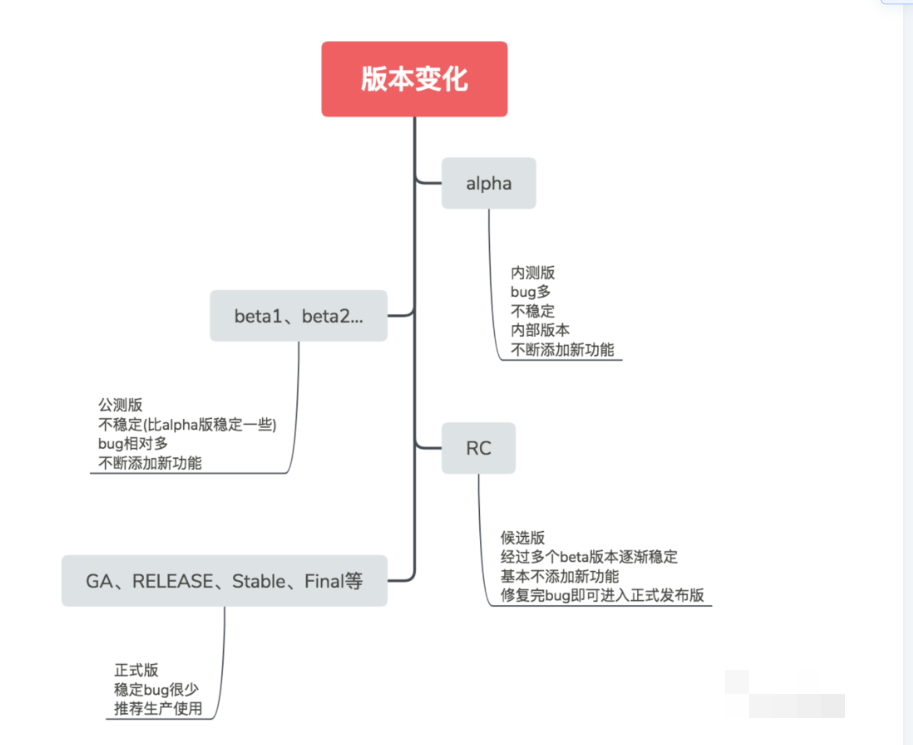
软件 alpha、beta、rc、stable 各个版本有什么区别
https://cloud.tencent.com/developer/article/1806334


Scala 中解析 json 工具对比
https://blog.csdn.net/Code_LT/article/details/129044881
1, 做少量文件解析,优先用json4s,因为json4s时基于Scala开发的,对scala使用场景支持更好
2. 做大量数据的解析,追求序列化、反序列化速度时,考虑用fastjson,但是fastjson是基于java开发的,对scala支持不好。所以,除非遇到性能提升场景或者只是简单的json处理,才考虑在scala中用fastjson。
可选工具:
fastjson
gson
json4s(jackson的scala版本)
lift-json
spray-json
circle
play-json
@JsonIgnoreProperties(ignoreUnknown = true) 是一个注解,通常用于在Java对象序列化和反序列化过程中,忽略未知的属性。在使用Jackson库进行JSON序列化和反序列化时,如果JSON数据中包含了Java对象中不存在的属性,那么默认情况下会抛出异常。通过在Java对象上添加 @JsonIgnoreProperties(ignoreUnknown = true) 注解,可以告诉Jackson库在反序列化时忽略JSON数据中存在但Java对象中未定义的属性,从而避免抛出异常。
举个例子,假设有一个Java类 User,其中定义了一些属性,如id、name、email等。如果从JSON数据中反序列化一个User对象,而JSON数据中包含了额外的属性,比如age、gender,那么如果没有添加 @JsonIgnoreProperties(ignoreUnknown = true) 注解,Jackson库会抛出异常。而添加了该注解后,Jackson库会忽略JSON数据中的额外属性,只将已知的属性映射到Java对象中。
总之,@JsonIgnoreProperties(ignoreUnknown = true) 注解可以帮助我们在处理JSON数据时更加灵活地处理未知属性,而不会因为属性不匹配而导致异常。
Kafka Manager
https://blog.csdn.net/qq_36306519/article/details/130477827
https://blog.51cto.com/u_16213440/7865373
https://zhuanlan.zhihu.com/p/586005021
https://www.cnblogs.com/zhangdapangzo/p/17211612.html
https://blog.csdn.net/xiaolin84250/article/details/132448894
https://blog.csdn.net/bestcxx/article/details/123637918
https://geek-docs.com/scala/scala-questions/895_scala_using_a_properties_file_with_a_custom_bean_parser.html
https://blog.csdn.net/weixin_42613131/article/details/129611532
https://blog.csdn.net/u012344939/article/details/132513417
DataStream方式 Flink 1.12+可使用,Flink SQL方式 1.13+版本可用
DataStream方式支持多库多表的监控,而Flink SQL只能单表监控

ds.assignAscendingTimestamps(_.timestamp) 是 Apache Flink 中用于指定事件时间的操作。在 Flink 中,事件时间是指事件实际发生的时间,而处理时间是指事件被处理的时间。在流处理中,我们通常需要根据事件时间进行窗口操作、水印生成等操作,以确保数据处理的准确性和完整性。
ds 是一个 DataStream 对象,assignAscendingTimestamps 是一个方法,用于为数据流中的元素分配事件时间戳。_.timestamp 是一个函数,用于从数据流中的元素中提取时间戳信息。
具体来说,assignAscendingTimestamps 方法会根据提取的时间戳信息为数据流中的元素分配事件时间戳,并且会确保分配的时间戳是单调递增的。这对于后续的窗口操作和水印生成非常重要,因为 Flink 需要根据事件时间的顺序来进行正确的计算和处理。
总的来说,ds.assignAscendingTimestamps(_.timestamp) 的作用是为数据流中的元素分配事件时间戳,并确保分配的时间戳是单调递增的,以支持基于事件时间的流处理操作。
-
ds.keyBy(data=>true): 这一部分代码是对数据流进行分区操作,使用keyBy方法可以将数据流按照指定的键进行分区,相同键的数据会被分配到同一个分区中。在这里,使用data=>true作为键的提取逻辑,意味着所有的数据都会被分配到同一个分区中,即所有数据被视为同一个键。这样做的目的是为了将所有数据发送到同一个并行任务中,以便进行后续的窗口操作。 -
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(2))): 这一部分代码是对分区后的数据流进行窗口操作。使用window方法可以指定窗口类型和窗口参数。在这里,使用了SlidingEventTimeWindows,表示使用基于事件时间的滑动窗口。其中,Time.seconds(10)表示窗口的长度为10秒,Time.seconds(2)表示窗口的滑动步长为2秒。
综合起来,这段代码的作用是将数据流按照一个虚拟的键进行分区,然后对分区后的数据流进行基于事件时间的滑动窗口操作,窗口的长度为10秒,滑动步长为2秒。这样可以实现对数据流进行窗口化处理,以便进行基于窗口的聚合、计算等操作。
这段代码是 Apache Flink 中用于对数据流进行分区操作的一种方式。让我来解释一下这段代码的作用:
ds1.keyBy(data=>"key"):这一部分代码使用了 keyBy 方法,它的作用是将数据流按照指定的键进行分区。在这里,使用 data=>"key" 作为键的提取逻辑,意味着根据数据中的 "key" 字段的数值进行分区。这样做的目的是将具有相同 "key" 值的数据分配到同一个分区中,以便后续的并行操作。
总的来说,ds1.keyBy(data=>"key") 的作用是根据数据中的 "key" 字段的数值进行分区,以便对数据流进行并行处理。
Flink -- window(窗口)
https://blog.csdn.net/m0_62078954/article/details/134255401
https://blog.csdn.net/weixin_50835854/article/details/130753784
窗口时间 t3 10s
数据到达时间 t0 62s
ws 延迟时间 t1 2s
ws 水印时间 t2 60s=t0-t1
计算时间 t4 12s=t3+t1
窗口等待时间 t5 1min=60s
数据到达时间2 t6 72s ,此时水位线ws=70s,窗口1 销毁(关闭)
窗口1销毁时间 t7 72s=10s+60s+2s (t7=t3+t1+t5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号