不止八股:阿里内部语雀一些有趣的并发编程笔试题2——手写限流器
0丶引入
笔者社招一年半经验跳槽加入阿里约1年时间,无意间发现一些阿里语雀上的一些面试题题库,出于学习目的在此进行记录。
- 这一篇主要写一些有趣的笔试题(非leetcode),这些有的考验并发编程,有的考验设计能力。
- 笔者不是什么技术大牛,此处笔试题充满主观思考,并不一定是满分答案,欢迎评论区一起探讨。
- 不止八股:面试题之外,笔者会更多的思考下底层原理,不只是简单的背诵。
下面这个题目也是笔者面试阿里笔试做过的一道笔试题,现在回想自己那时候写的也是一坨
1.题目-限流组件设计
网站或者API服务有可能被恶意访问导致不可用,为了防止流量过大,通常会有限流设计。
请实现一个 RateLimiter 类,包含 isAllow 方法。每个请求包含一个 resource 资源,如果resource 在 1 秒钟内有超过 N 次请求,就拒绝响应。
public interface IRateLimiter{
boolean isAllow(String resource);
}
2.笔者的题解
笔者在面试的时候,其实没看过,没使用过sentinel(《Sentinel基本使用与源码分析》),也没看过Guava的RateLimiter,笔者上一份工作是一个银行内部的工具,用户就是100-的银行经历,限流是不可能限流。
因此第一反应是使用一个变量记录当前是第几秒,另外一个变量记录当前当前通过了多少请求,这种算法也叫计数器算法。所以这里引入了两个问题:
- 需要根据resource映射到一个对象,对象具备两个字段——记录第几秒和通过请求数
- 如何保证 【两个字段——记录第几秒和通过请求数】更新的线程安全
2.1 使用锁实现计数器算法
2.1.1 回家等通知的写法
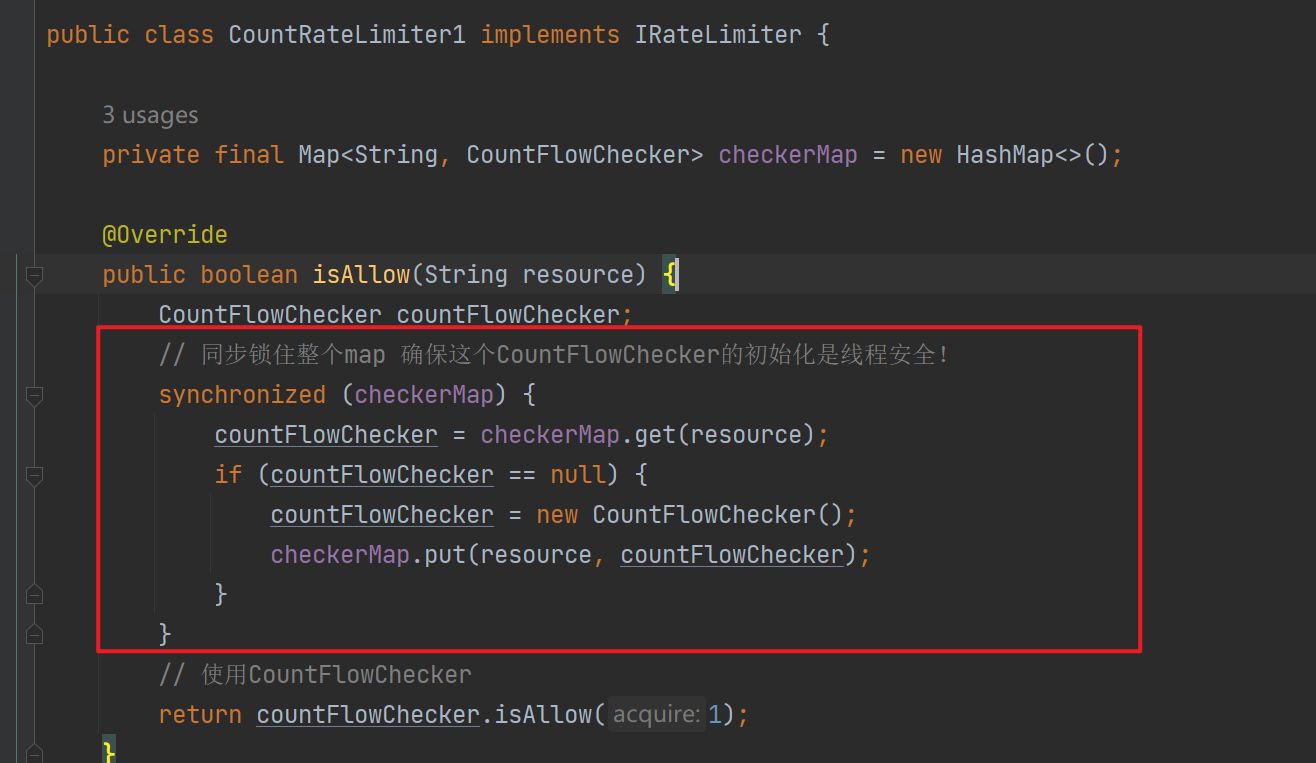
如上,我们抽象出CountFlowChecker负责这一个资源的限流控制,checkerMap中key是资源名称,value是CountFlowChecker。然后使用synchronized修饰checkerMap来实现checkerMap初始化的线程安全。这一段代码有哪些问题?
- checkerMap读是没有竞争的,不需要加锁
- 锁的粒度太大了——锁定整个checkerMap,让所有调用CountRateLimiter1#isAllow都是串行的!
2.1.2 解决[checkerMap读是没有竞争的,不需要加锁]的问题
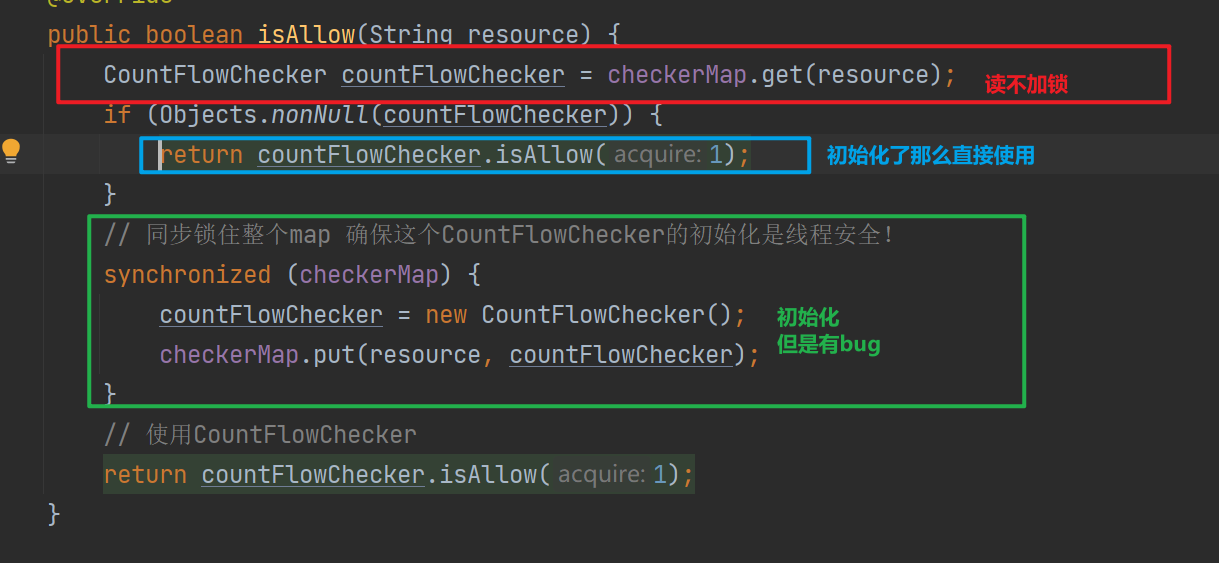
如上读不加锁,只有发现没有初始化,需要写的是才进入绿色部分代码进行初始化,但是绿色部分部分存在bug
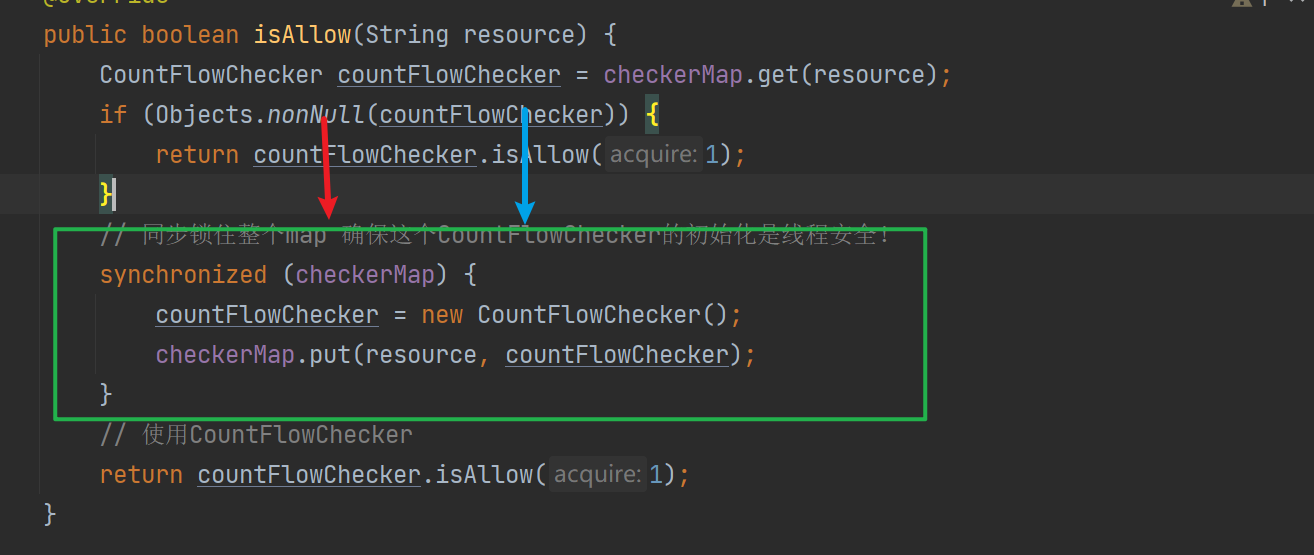
如图红色,蓝色代表两个并发的请求,二者访问的时候CountFlowChecker都没有初始化,so都来到绿色部分,假设红色请求先拿到锁并成功初始化了CountFlowChecker然后释放了锁,这时候蓝色请求处理线程被唤醒,将覆盖红色请求处理线程写入的CountFlowChecker。如何解决昵?

其实和单例模式中的双重if异曲同工之妙,这里获取到锁后再次读取,只有为null才进行初始化,解决了上面红蓝线程覆盖的情况!这种写法在Spring的Bean初始化中也有使用。
但是即使你这样写了,也是要回家等通知的!因为 锁的粒度太大了——锁定整个checkerMap,让所有调用CountRateLimiter1#isAllow都是串行的!
2.1.3 减小锁粒度

如上图,锁整个checkerMap相当于把checkerMap把checkerMap中每一个数组都锁了,但是不同的数组槽之间是没有线程安全问题的,比如数组下标0对应了资源A,数组下标2对应了资源B,A和B是可以并行做数据变更操作的!
这其实就对应了ConcurrentHashMap中减小锁粒度思想!因此可以这样优化:

这里我们使用了ConcurrentHashMap#computeIfAbsent,保证了假设resouce对应数组槽没有元素的时候,会串行的将new 出来的CountFlowChecker塞到checkerMap中。ConcurrentHashMap中是对每一个数组槽使用cas+synchronized进行初始化,原理可见:《JUC源码学习笔记8——ConcurrentHashMap源码分析》。
至此我们解决了resouce和CountFlowChecker的关联,接下来就是CountFlowChecker#isAllow的实现了,也是限流算法真正核心的部分!
下面是使用synchronized实现的方式:
@Data
static class CountFlowChecker {
// 当前是第几秒
private long seconds = TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis());
// 当前seconds这一秒请求了多少次
private int count = 0;
// qps = 10
private int max = 10;
public synchronized boolean isAllow(int acquire) {
if (acquire > max) {
return false;
}
long current = TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis());
if (current == seconds) {
boolean flag = count + acquire <= max;
count += acquire;
return flag;
}
count = acquire;
return true;
}
}
如上我们使用synchronized保证seconds和count更新的原子性和可见性。
虽然synchronized具备轻量级这种乐观锁的优化策略,但是在并发比较高的情况下会升级为重量锁,最后会导致更多的系统调用和线程上下文切换,所以这时候通常需要考虑使用cas进行优化。(guava的RateLimiter就是使用的synchronized,但是面试官大概率会想看你对cas的理解如何)
2.2 使用cas实现计数器算法
推荐阅读:《JUC源码学习笔记4——原子类源码分析,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法》
这里主要是怎么用cas完成seconds和count两个变量的更新
-
AtomicReference
我们自定义一个类,里面包含当前是第一秒和这一秒通过了多次请求
-
AtomicStampedReference
本质是解决cas中的ABA问题,但是在这里我们可以使用
stamp 表示当前是第几秒
如下是使用AtomicStampedReference的实现方式
public class CountFlowChecker1 {
/**
* Integer 表示这一秒内通过的请求,
* stamp 表示当前是第几秒
*/
private AtomicStampedReference<Integer> flowCountHelper;
private int max;
public CountFlowChecker1(int max) {
this.max = max;
flowCountHelper = new AtomicStampedReference<>(0, currentSeconds());
}
public boolean isAllow(int acquire) {
if (acquire > max) {
return false;
}
while (true) {
// 当前是第几秒
int currentSeconds = currentSeconds();
// 上一次统计是第几秒
int preSeconds = flowCountHelper.getStamp();
// 上一次的数量
Integer preCount = flowCountHelper.getReference();
// 是同一秒,超过了阈值,那么false
if (preSeconds == currentSeconds & preCount + acquire > max) {
return false;
}
// 不是同一秒,或者是同一秒没超过阈值,那么cas更新
if (flowCountHelper.compareAndSet(preCount, preSeconds == currentSeconds?preCount + acquire:acquire, preSeconds, currentSeconds)) {
return true;
}
// 更新失败 继续自旋
}
}
private static int currentSeconds() {
return (int) (TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis()) % Integer.MAX_VALUE);
}
}
主要是isAllow方法,如上我们可以看到核心思想是在一个自旋中使用cas保证第几秒和请求数量的更新原子性。
但是这里引入一个问题:为什么AtomicStampedReference#compareAndSet可以保证可见性?线程A cas成功,那么线程B cas会失败继续自旋,重新获取flowCountHelper.getStamp()和flowCountHelper.getReference(),为什么getStamp,getReference可以保证线程B立马可见?

原因就在AtomicStampedReference使用Pair保证stamp和reference,Pair是使用volatile修饰的,对于volatile变量的写操作,会在其后插入一个内存屏障。在Java中,volatile变量的写操作后通常会插入一个"store-store"屏障(Store Barrier),以及一个"store-load"屏障。这些内存屏障确保了以下几点:
- Store-Store Barrier:这个屏障防止volatile写与之前普通写的指令重排序。也就是说,对volatile变量的写操作之前的所有普通写操作都必须在volatile写之前完成,确保了volatile写之前的修改对于其他线程是可见的。
- Store-Load Barrier:这个屏障防止volatile写与之后的读写操作重排序。它确保了volatile变量写之后的读取操作不会在volatile写之前发生。这保证了volatile写操作的结果对后续操作是可见的。
ok,我们继续回到这种写法,由于其使用了cas保证原子性,如果一瞬间有1000线程过来,那么1个线程成功,那么999个线程就要继续自旋,导致浪费了很多cpu资源,有没有办法优化一下昵?
2.2.1 使用Thread#yield降低cpu资源浪费
既然太多线程自旋了,那么可以在自旋失败后使用Thread#yield降低这种cpu资源的竞争

但是这种方法也不是非常的优秀,因为它会导致请求处理的rt变高,但是是一种优化思路,咱没办法做到既要有要。
2.2.2 借鉴LongAdder的思想,减少热点数据竞争
如上面的写法,所有线程都在cas竞争修改flowCountHelper中记录数量,这个数量是一个热点数据,我们可以学习LongAdder的做法进行优化
LongAdder 内部有base用于在没有竞争的情况下,进行CAS更新,其中还有Cell数组在冲突的时候根据线程唯一标识对Cell数组长度进行取模,让线程去更新Cell数组中的内容。这样最后的值就是 base+Cell数组之和,LongAdder自然只能保证最终一致性,如果边更新边获取总和不能保证总和正确
如下是借鉴后写的代码
2.2.2.1 基本属性

可以看到我们改变了使用一个Integer记录这一秒请求总数的方式,转而使用一个AtomicIntegerArray数组记录,数组之和才是这一秒通过的总数。
而且还使用了ThreadLocal记录当前线程分配到的位置,一个线程对应AtomicIntegerArray数组中的一个位置,从而实现热点数据分离!!!
但是这也带来了一些弊端,后面代码会有所体现。
2.2.2.2 限流逻辑
public boolean isAllow(int acquire) {
if (acquire > max) {
return false;
}
while (true) {
// 当前是第几秒
int currentSeconds = currentSeconds();
// 上一次统计是第几秒
int preSeconds = flowCountHelper.getStamp();
int currentThreadRandomIndex = THREA_RAMDON_INDEX.get();
// 不是同一秒 尝试new 一个全新的数组!
if (currentSeconds != preSeconds) {
AtomicIntegerArray newCountArray = new AtomicIntegerArray(100);
newCountArray.set(currentThreadRandomIndex, acquire);
if (flowCountHelper.compareAndSet(flowCountHelper.getReference(), newCountArray, preSeconds, currentSeconds)) {
return true;
}
}
// 是同一秒 or cas 失败 如果是cas失败,那么说明存在另外一个线程new了一个权限数组
// 统计这一秒有多少请求量
// 细节1 重新使用flowCountHelper.getReference(),因为如果是上面cas失败,那么这里的flowCountHelper.getReference()对应的AtomicIntegerArray被替换成新的了
AtomicIntegerArray countArray = flowCountHelper.getReference();
int countArrayLength = countArray.length();
// 统计总数
long preCount = 0;
for (int i = 0; i < countArrayLength; i++) {
preCount = countArray.get(i);
}
// 理论上 上面的for不会消耗太多时间
// 不够需要的,那么false
if (preCount + acquire > max) {
return false;
}
// 在currentThreadRandomIndex的原值
int sourceValue = countArray.get(currentThreadRandomIndex);
// 细节2:使用的是【细节1】拿到的array 这时候不能重新flowCountHelper.getReference(),因为如果上面的for统计超过了一秒,那么这一次的请求会加到下一秒
if (countArray.compareAndSet(currentThreadRandomIndex, sourceValue, sourceValue + acquire)) {
// 弊端,这里true 不一定成功的限制了qps,因为上面的求和 与 这里的cas 不具备一致性,存在其他线程修改了的情况
return true;
}
// 理论冲突的概率降低了,不需要 yield 吧
}
}
可以看到大体思路差不多,其中有两处细节,大家可以品一品
-
细节1:

-
细节2:

这里使用的是统计前获取AtomicIntegerArray,为什么不
flowCountHelper.getReference()?因为存在另外线程发现不是同一秒然后更新了flowCountHelper中AtomicIntegerArray引用的指向,如果重新flowCountHelper.getReference()可能让上一秒的请求加到下一秒,当然这也不是不可以,这也相当于上一秒借用了下一秒-
弊端:求和和cas不具备一致性

-
问题:为什么AtomicIntegerArray可以保证数组元素的可见性?
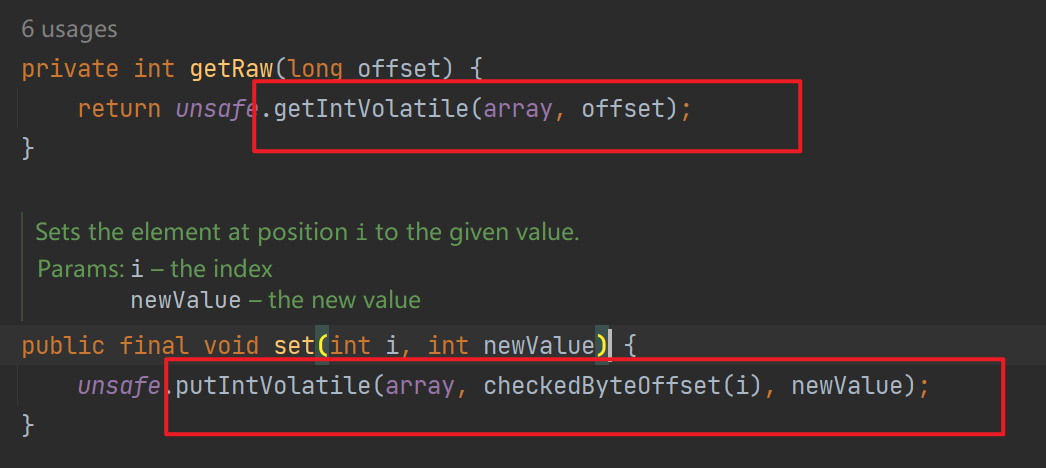
同样是因为使用了内存屏障!
另外笔者这里的AtomicIntegerArray是没法扩容的,默认100个。LongAdder的设计则更为巧妙,LongAdder中存在一个volatile long base值,LongAdder会优先case更新base,如果存在多线程导致case失败,才使用数组进行规避,而且还具备扩容的能力,感兴趣的话可以看看笔者写的:JUC源码学习笔记4——原子类源码分析,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 - Cuzzz - 博客园 (cnblogs.com)
2.3 计数器算法的不足
临界值问题:假设我们qps最大为10,如果在第一秒的前900ms没有请求,但是后100ms通过了10个请求,然后来到下一秒,下一秒的100ms也通过了100ms,那么在第一秒后100ms和下一秒的前100ms一共通过了20个请求,这一段时间内是超出了qps 10的!
为此有了下面的滑动窗口算法
2.4 滑动窗口算法
为了避免计数器中的临界问题,让限制更加平滑,将固定窗口中分割出多个小时间窗口,分别在每个小的时间窗口中记录访问次数,然后根据时间将窗口往前滑动并删除过期的小时间窗口。
计数器算法,可以看做只有两个窗口,因此在两个窗口边界的时候会出现临界问题。而滑动窗口统计当前时间处于的1s内产生了多少次请求,避免了临界问题
- 优点:实现相对简单,且没有计数器算法的临界问题
- 缺点:无法应对短时间高并发(突刺现象),比如我在间歇性高流量请求,每一批次的请求,处于不同的窗口(图中的虚线窗口)
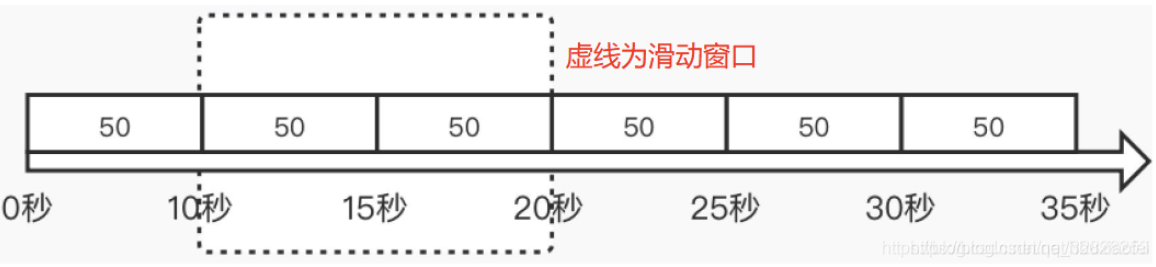
接下来我们将手写滑动窗口算法(sentinel也是使用的滑动窗口算法:Sentinel基本使用与源码分析)
import java.util.Objects;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReferenceArray;
import java.util.concurrent.atomic.AtomicStampedReference;
/**
* 假设 把一秒分割为 5 份
* |-----|-----|-----|-----|------|
* 0 200ms 400ms 600ms 800ms 1000ms
* 假设当前是10s余500ms 那么应该落到 400ms——600ms之间
* 算法就是 10s余500ms%1s = 500ms,500ms/(1s/5) = 2 ==> 对应400ms——600ms
* 这里需要注意 如果不是同一秒的值,那么不要统计进去,
* 比如9s的时候400ms——600ms值是10,现在时间到10s余500ms了
* 统计的时候不是10+1,而是1,因为都不同一秒了,因此滑动窗口的元素需要记下当前是第一秒的值
*/
public class CountFlowChecker3 {
// AtomicReferenceArray 就是上面的滑动窗口,本质是一个数组
// AtomicStampedReference中stamp记录是第几秒的值,Integer记录数量
private AtomicReferenceArray<AtomicStampedReference<Integer>> slideWindow;
// 最大qps
private int max;
// 把一秒分为多少份!
private int arrayLength;
// 一份是多少ms
private int intervalDuration;
public CountFlowChecker3(int max, int arrayLength) {
this.max = max;
this.arrayLength = arrayLength;
this.slideWindow = new AtomicReferenceArray<>(arrayLength);
// 这里可能存在没办法整除的情况,不是本文的主题,暂不做考虑
this.intervalDuration = 1000 / arrayLength;
}
public boolean isAllow(int acquire) {
if (acquire > max) {
return false;
}
while (true) {
// 当前时间
long currentMilliSeconds = currentMilliSeconds();
int currentSeconds = (int) (TimeUnit.MILLISECONDS.toSeconds(currentMilliSeconds) % Integer.MAX_VALUE);
// 对应在滑动窗口的位置
int index = (int) (currentMilliSeconds%1000 / this.intervalDuration);
// 求和
long preSum = sum(currentSeconds);
// 超出限流
if (preSum + acquire >= max) {
return false;
}
// 获取当前位置的引用
AtomicStampedReference<Integer> element = slideWindow.get(index);
// 如果没有初始化
if (Objects.isNull(element)) {
if (slideWindow.compareAndSet(index, null, new AtomicStampedReference<>(acquire, currentSeconds))) {
return true;
}
}
// 刷新一下,因为这时候maybe被其他线程初始化了
element = slideWindow.get(index);
// 是同一秒,那么+,如果不是那么覆盖
int sourceSeconds = element.getStamp();
int updateValue = sourceSeconds == currentSeconds ? element.getReference() + acquire : acquire;
if (element.compareAndSet(element.getReference(),updateValue,sourceSeconds,currentSeconds)) {
return true;
}
}
}
private long sum(int currentSeconds) {
int sum = 0;
for (int i = 0; i < slideWindow.length(); i++) {
AtomicStampedReference<Integer> element = slideWindow.get(i);
// 是同一秒的值才统计!
if (Objects.nonNull(element) && element.getStamp() == currentSeconds
&& Objects.nonNull(element.getReference())) {
sum = element.getReference();
}
}
return sum;
}
private static long currentMilliSeconds() {
return System.currentTimeMillis();
}
}
可以看到滑动窗口统计完多个窗口值后,如果判断可以继续通过那么也是进行cas更新,统计sum和后面的cas也不具备一致性
并且同样可以使用LongAdder优化热点数据竞争的问题,比如下优化,代码类似于2.2.2
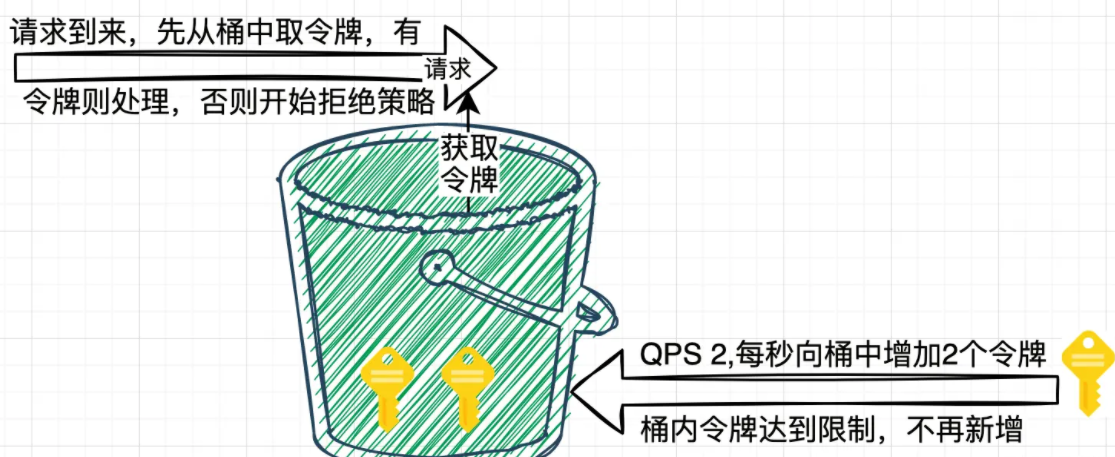
2.5 令牌桶算法
请求执行作为消费者,每个请求都需要去桶中拿取一个令牌,取到令牌则继续执行;如果桶中无令牌可取,就触发拒绝策略,可以是超时等待,也可以是直接拒绝本次请求,由此达到限流目的。当桶中令牌数大于最大数量的时候,将不再添加。它可以适应流量突发,N 个请求到来只需要从桶中获取 N 个令牌就可以继续处理。
import com.google.common.util.concurrent.AtomicDouble;
public class CountFlowChecker4 {
// 最大qps
private final double maxTokens;
// 上一次可用的tokens
// com.google.common.util.concurrent.AtomicDouble;
// 使用doubleToRawLongBits和longBitsToDouble进行double的转换
private final AtomicDouble availableTokens;
// 上一次填充的间隔
private volatile long lastRefillTimeStamp;
public CountFlowChecker4(double maxTokens) {
this.maxTokens = maxTokens;
this.availableTokens = new AtomicDouble(maxTokens);
this.lastRefillTimeStamp = System.currentTimeMillis();
}
public boolean isAllow(int acquire) {
if (acquire > maxTokens) {
return false;
}
long now = System.currentTimeMillis();
// 尝试根据时间重新填充令牌
refill(now);
double currentTokens = availableTokens.get();
// 如果没有足够的令牌,则立即返回false,不阻塞
if (currentTokens < acquire) {
return false;
}
// 如果令牌数量足够,则使用CAS减少一个令牌
return availableTokens.compareAndSet(currentTokens, currentTokens - acquire);
}
private void refill(long now) {
double tokensToAdd = (((double) (now - lastRefillTimeStamp)) / 1000 * maxTokens);
double preCount = availableTokens.get();
double newTokenCount = Math.min(maxTokens, preCount + tokensToAdd);
// 使用CAS更新令牌数量,如果失败则忽略(其他线程可能已经更新了)
if (tokensToAdd > 0) {
if (availableTokens.compareAndSet(preCount, newTokenCount)) {
// 这里不需要纠结lastRefillTimeStamp 和 availableTokens更新的原子性
// 因为lastRefillTimeStamp 记录的是上一次更新时间
// 如果当前线程成功,那么就更新吧
lastRefillTimeStamp = now;
}
}
}
}
令牌桶算法实现也并没有太复杂,而且这里使用的是动态计算令牌数据,可以看出适应流量突发,一瞬间可用给出全部的令牌,甚至还可以积攒令牌应对并发,但是这种允许突发流量对于下游是不是不太友好。
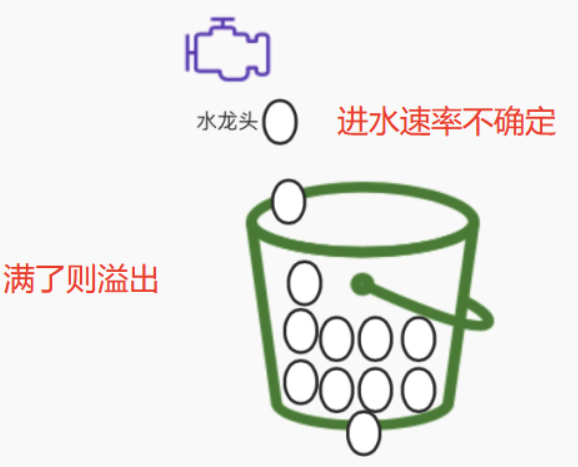
2.6 漏桶算法
漏桶限流算法的核心就是, 不管上面的水流速度有多块, 漏桶水滴的流出速度始终保持不变,不论进入的流量有多么不规则,流量的离开速率却始终保持恒定
在漏桶算法中,有一个固定容量的桶,请求(类似水)以任意速率流入桶内,而桶以恒定速率往外“漏”出请求。如果桶满了,进来的新请求会丢弃或排队等待。
通常实际应用是通过定时器任务实现漏桶的“漏水”操作,即定时任务线程定时从桶中获取任务进行执行,理论上使用一个阻塞队列+调度线程池可进行实现。
漏桶算法在需要及时响应的场景下不是很友好,任务如果被提交到桶,调用方却超时了那么任务处理也没啥意义了,和本地场景不是很符合。
3.笔者的思考
3.1 限流器算法比较
-
计数器(Fixed Window Counter)
最简单的限流算法,基于一个固定的时间窗口(比如每秒),统计请求的数量,当请求数量超出阈值时,新的请求将被拒绝或者排队。
- 优点:实现简单,容易理解。
- 缺点:在时间窗口边界处存在突发请求量的问题,即窗口重置时可能会突然允许大量请求通过,从而导致短时间的高流量。
-
滑动窗口(Sliding Window Log)
滑动窗口算法是对计数器算法的一种改进,它考虑了时间窗口中的每个小间隔。这些间隔可以是过去几秒、几分的N个桶,算法根据请求到达的时间进行统计,使得限流更加平滑。
- 优点:相比固定窗口算法,滑动窗口可以减少时间窗口边缘的突发流量问题。
- 缺点:比固定窗口算法复杂,实现和维护成本更高。
-
漏桶(Leaky Bucket)
漏桶算法使用一个固定容量的桶来表示令牌或请求。请求按照固定的速率进入桶内,而桶按照固定的速率向外漏水(处理请求),当桶满时,多余的水(请求)会溢出(被拒绝或排队)。
- 优点:能够以恒定的速率处理请求,避免了突发流量影响。
- 缺点:即使网络状况良好,桶的出水速率也是恒定的,这可能会导致一定程度上的资源浪费。
-
令牌桶(Token Bucket)
令牌桶算法维护一个令牌桶,桶内有一个固定容量的令牌。系统以恒定速率生成令牌到桶中,当请求到来时,如果桶内有令牌,则允许该请求通过,并消耗一个令牌;如果没有令牌,则请求被拒绝或排队。
- 优点:能够允许一定程度的突发流量,因为可以累积令牌;处理请求的速率可以动态调整。
- 缺点:实现比固定窗口计数器和漏桶算法复杂。
3.2 上述编码中的思想
-
【2.1.2解决
[checkerMap读是没有竞争的,不需要加锁]的问题】读写分离的思想,如mysql中读取一般是不加锁的,我们在实际业务开发中读取数据也一般是不会加锁的!
-
【2.1.3 减小锁粒度】
如mysql中的行锁和表锁,行锁提高了更高的并发度,这也是innodb优于其myisam的点
-
【2.2.2 借鉴LongAdder的思想,减少热点数据竞争】
热点数据分离,比如redis中的热key释放可拆分为key1,key2进行热点数据分离。
比如大卖的商家,其订单流水分在多个表,分散热点避免单表性能瓶颈
-
【2.6 漏桶算法】
类似消息的队列的削峰填谷,将请求放到消息队列,让消费者以合适的速率进行消费
3.3 分布式限流
如果机器有500台,限流100qps怎么办?
- Sentinel提供了一种分布式限流,核心是选取一台机器作为leader,其他机器调用的时候需要发送请求申请令牌,leader负责进行统计。但是一般建议使用,因为具备单点故障的问题,而且也不够去中心化。
- redis实现,每一台机器都需要访问redis进行读写操作,热key问题,并且徒增rt,不太划算
我们在双11大促的时候,会进行流量评估,一般不建议单机qps不能小于5,小于5的限流容易出现误杀,不太具备现实意义。
因此如果流量负载均衡,那么建议优化为单机限流,使用sentinel or guava的RateLimiter
但是笔者有一个项目,算法提供AIGC服务,机器只有100台,且每一台并发度为1,服务端有500台,但是笔者是离线定时任务调用AIGC服务,所以我使用了分布式调度map-reduce,使用调度机器分配任务到100台服务端机器上,服务端机器单机串行从而控制qps!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号