Netty源码学习6——netty编码解码器&粘包半包问题的解决
零丶引入
经过《Netty源码学习4——服务端是处理新连接的&netty的reactor模式和《Netty源码学习5——服务端是如何读取数据的》的学习,我们了解了服务端是如何处理新连接并读取客户端发送的数据的:
- netty的reactor:主reactor中的NioEventLoop监听accept事件,然后调用NioServerSocketChannel#Unsafe读取数据——依赖JDK ServerSockectChannel#accept,获取到新连接——SockectChannel后,会包装为NioSocketChannel然后调用channelRead,随后ServerBootstrapAcceptor 会负载均衡的选择一个子reactor 注册NioSocketChannel对read事件感兴趣
- read事件:子reactor中的NioEventLoop会监听read事件,调用NioSocketChannel读取客户端发送数据(依赖JDK SocketChannel#read(ByteBuffer)),netty会使用ByteBufAllocator优化ByteBuf的分配,使用AdaptiveRecvByteBufAllocator对ByteBuf进行扩容缩容,以及控制是否继续读取。

——至此数据以及读取到了ByteBuf中,服务端需要先解码ByteBuf中的数据,然后我们业务处理器才能根据发送的消息进行响应,业务执行结果还需要进行编码才能发送,so 这一篇和大家一起学习以下Netty中的编码解码。
一丶看看其他开源框架是如何使用Netty的编码解码的
1.Dubbo
Apache Dubbo 是一款 RPC 服务开发框架,用于解决微服务架构下的服务治理与通信问题,使用 Dubbo 开发的微服务原生具备相互之间的远程地址发现与通信能力, 利用 Dubbo 提供的丰富服务治理特性,可以实现诸如服务发现、负载均衡、流量调度等服务治理诉求。
Dubbo 中的网络通信可以基于Netty,Dubbo 官方源码如下
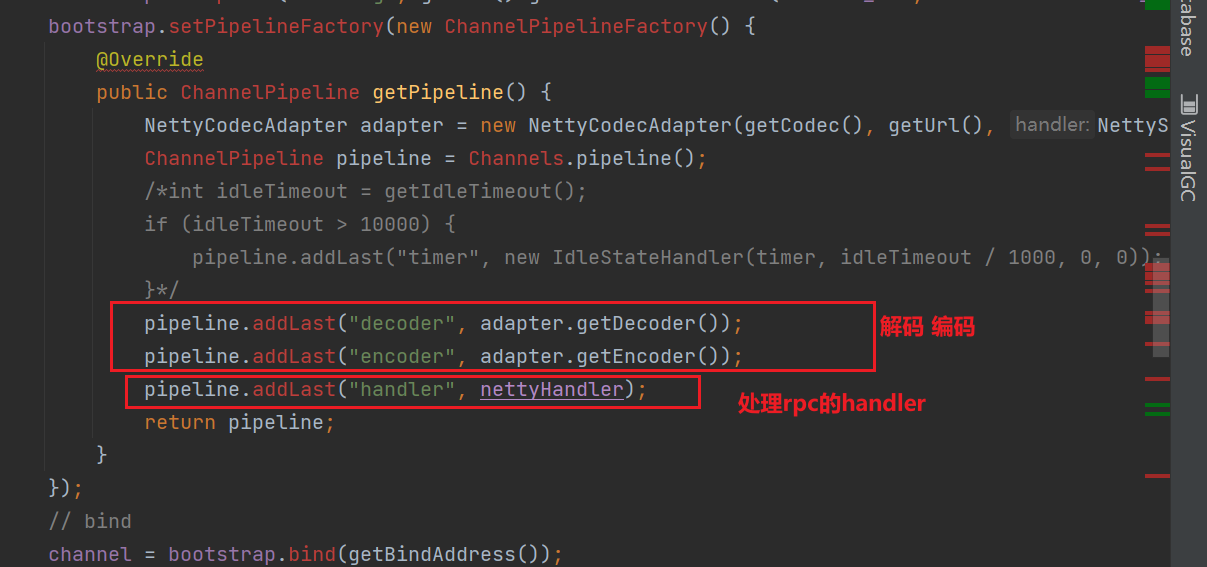
可以看到Dubbo会向ChannelPipeline中加入decoder和encoder,负责编码解码。
2.Sentinel
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。(详细学习:《Sentinel基本使用与源码分析》)
sentinel提供了集群限流的能力,本质是服务端控制令牌的下发,客户端通过网络通信申请令牌,如下是集群限流中,使用netty实现服务端的源码:
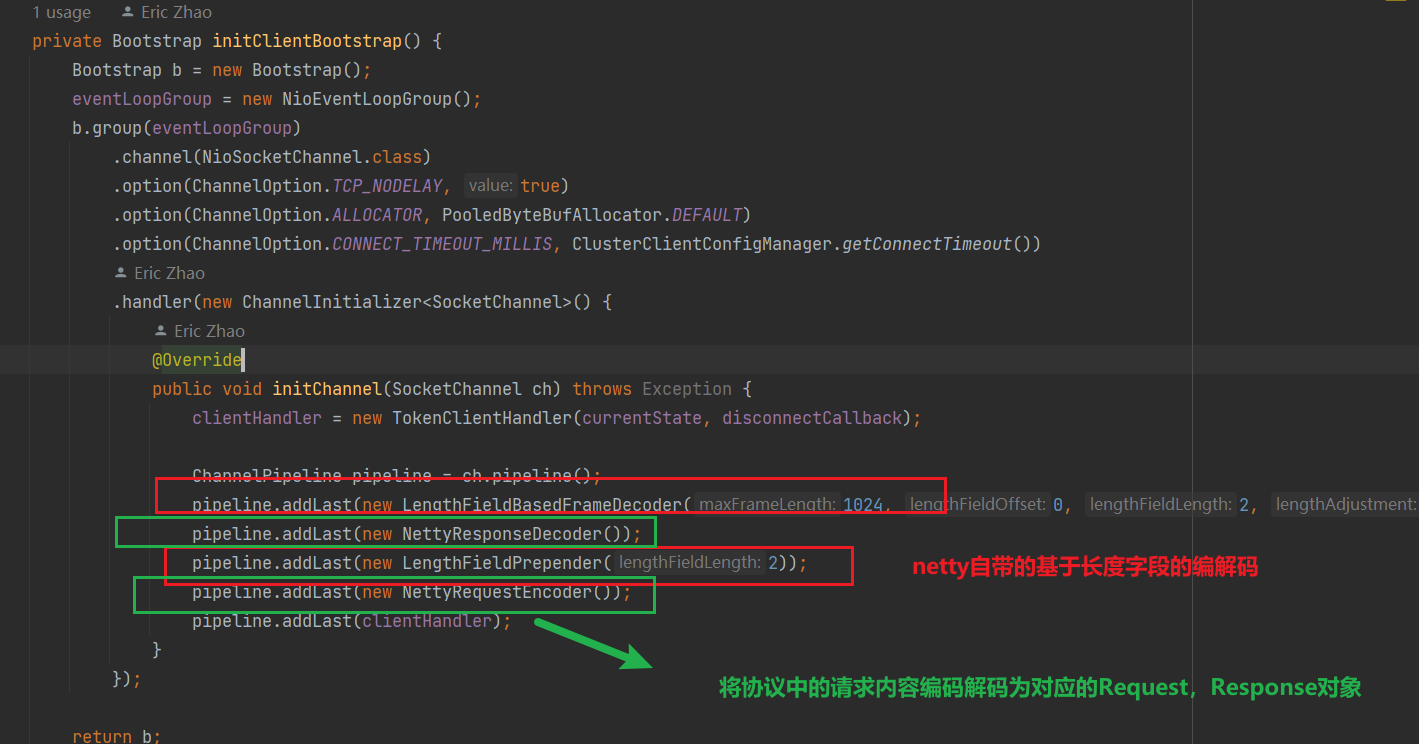
可以看到sentinel集群限流会向ChannelPipeline中增加
-
LengthFieldBasedFrameDecoder:基于长度字段的解码器——一级解码器,根据frame中的长度字段,解码出消息
-
NettyRequestDecoder:请求解码器——二次解码器,将一次解码器解码出的消息,反序列化为请求对象
-
LengthFieldPrepender:长度放在frame头部的编码器,将服务端响应的消息添加上长度信息
-
NettyResponseEncoder:将服务端处理返回的java对象,编码成ByteBuf
3.对比Dubbo和Sentinel对netty的使用
相比于Sentinel,Dubbo的使用更加简洁,直接将编码解码的逻辑封装到自己的adapter之中
Sentinel的使用也是非常标准,也利于我们理解netty的编解码运行机制——即编码解码其实是ChannelHandler的一种实现,通过将编码解码加入到ChannelPipline中实现数据的逐环处理。
二丶什么是编码,解码器,为什么需要编码解码器
netty中的编码解码器是负责将应用程序的数据格式转换为可以在网络中传输的字节流,以及将接收到的字节流转换回为应用程序可以处理的数据格式的组件。编解码器是网络通信的关键组件,因为它们抽象掉了网络层和应用层之间的复杂转换细节。
主要作用有:
-
数据序列化与反序列化:
- 编码(序列化):将应用数据结构(如对象、消息)转换成字节流,以便能够通过网络发送。
- 解码(反序列化):将网络中接收到的字节流转换回应用数据结构。
-
协议实现:
编解码器实现了网络通信中所需遵守的特定协议规则,如 HTTP、WebSocket,SMTP。
它们确保数据符合协议格式,并能够正确地被发送和接收方理解。
处理流控制问题: -
对于面向流的协议(如 TCP),解决粘包和半包等问题,确保数据的完整性。
-
解耦应用与网络层&扩展性与灵活性:
编解码器允许开发者专注于业务逻辑,而无需关心底层的字节处理。应用逻辑可以与网络传输逻辑分离,使得代码更加清晰和可维护。
应用开发者也可以随机的切换不同的编码解码器,提升扩展性和灵活性。
三丶Netty解决tcp粘包,半包的编解码器
1.tcp是基于流的协议&为什么会出现粘包,半包
TCP 传输的数据被视为一个连续的、无边界的字节流。网络上的两个应用程序通过建立一个 TCP 连接来交换数据,而这个数据流就像是从一个地方倒水到另一个地方,水(数据)会连续不断地流动,而不是一杯一杯分开倒(即不像独立的消息或数据包)。
-
TCP 数据发送:
当应用程序要发送数据时,它会
将数据写入到 TCP 套接字的发送缓冲区。这个写入操作通常是通过像 write() 或 send() 这样的系统调用完成的。TCP 协议会从发送缓冲区中取出数据,
并将数据分割成合适大小的段,此大小受多个因素影响,包括最大传输单元(MTU)和网络拥塞窗口(congestion window)。然后,TCP 将每个段封装在一个 TCP 数据包中,并加上 TCP 头部,其中包含序列号等信息,再将数据包发送到网络中。这里的关键点是,
TCP 不关心应用程序传递给它的数据是一条消息还是多条消息,它只是简单地将这些数据作为字节序列处理。因此,即使应用程序以多个 write() 调用发送多条消息,TCP 仍可能将它们合并成一个数据包发送,这就可能导致粘包问题。 -
TCP 数据接收:
在接收端,
TCP 数据包到达后,TCP 协议会解析 TCP 头部信息,并根据序列号将数据放入接收缓冲区中的正确位置。接收端的应用程序通过 read() 或 recv() 等系统调用从 TCP 套接字的接收缓冲区中读取数据。这里也是不考虑消息边界的,应用程序可能一次读取任意大小的数据,这可能导致一次读取操作包含了多条消息(粘包),或只有部分消息(半包)。
2.netty是怎么解决粘包,半包问题的
解决粘包,半包问题的关系,是如何分辨那一部分是一条完整的消息。
Netty 通过提供一系列编解码器(Decoder 和 Encoder)来解决 TCP 粘包和半包问题。这些编解码器位于 Netty 的管道(ChannelPipeline)中,它们对进出的数据流进行处理,确保数据的完整性和边界的正确性。
-
FixedLengthFrameDecoder:
这个解码器按照固定的长度对接收到的数据进行分割。如果发送的数据小于固定长度,那么发送方需要进行填充。
-
LineBasedFrameDecoder:
这个解码器基于换行符(\n 或 \r\n)拆分数据流。它适用于文本协议,如 SMTP 或 POP3。 -
DelimiterBasedFrameDecoder:
这个解码器根据指定的分隔符来拆分数据流。分隔符可以是任意的字节序列,如特定的字符或者字符串。 -
LengthFieldBasedFrameDecoder:
这是一个更加通用和灵活的解码器,它基于消息头的长度字段来确定每个消息的长度。发送方在消息头中指定了消息体的长度,接收方通过解码器读取指定长度的数据,从而确保完整性。 -
LengthFieldPrepender:
这个编码器在发送消息的前面添加长度字段,与 LengthFieldBasedFrameDecoder 配合使用,可确保粘包和半包问题不会发生
3.源码学习
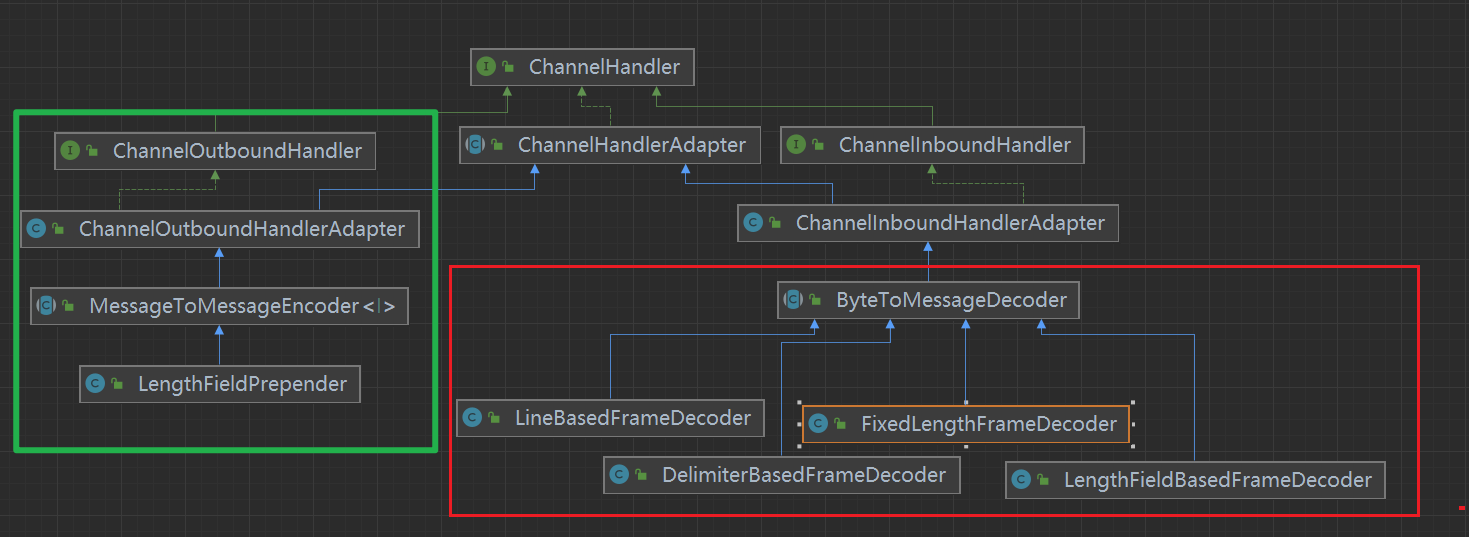
可以看到解码器都是ByteToMessageDecoder的子类,编码器只有LengthFieldPrepender是MessageToMessageEncoder的子类(和LengthFieldBasedFrameDecoder是一对)
3.1 ByteToMessageDecoder
以类似流的方式将字节从一个ByteBuf解码为另一个消息类型,是一个ChannelInboundHandler,意味着可以处理入站事件
其中最关键的是channelRead方法
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 只处理ByteBuf类型
if (msg instanceof ByteBuf) {
selfFiredChannelRead = true;
// List的一种实现 clear方法不会清空内容,recycle方法会清空
// newInstance方法使用FastThreadLocal缓存已有对象,避免重复构造
CodecOutputList out = CodecOutputList.newInstance();
try {
first = cumulation == null;
// cumulation累积器 ,第一次会把传入的byteBuf和空buf累计
// 后续会和原有的内容进行累计
cumulation = cumulator.cumulate(ctx.alloc(),
first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);
// 调用子类进行解码
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
try {
// 省略资源释放部分
int size = out.size();
firedChannelRead |= out.insertSinceRecycled();
// 编码后内容触发channelRead
fireChannelRead(ctx, out, size);
} finally {
// 释放资源
out.recycle();
}
}
} else {
// 只处理ByteBuf类型
ctx.fireChannelRead(msg);
}
}
-
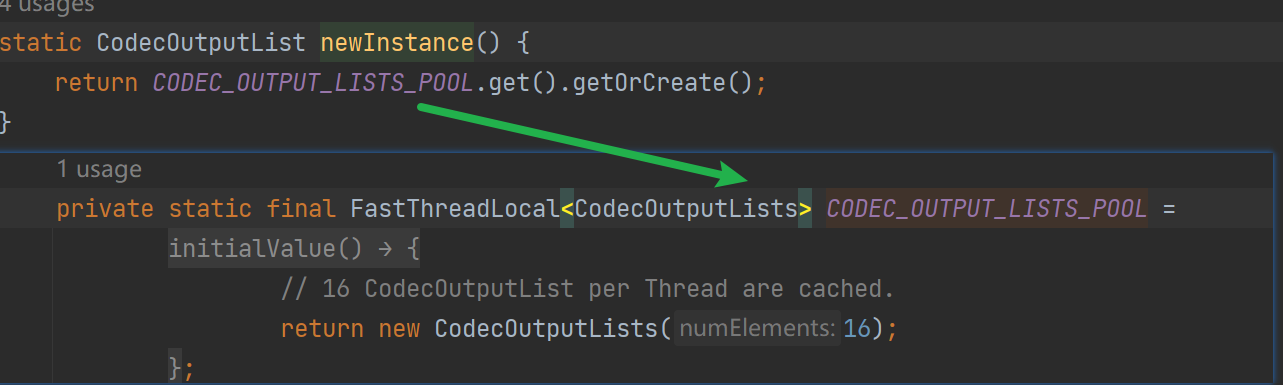
netty使用了CodecOutputList来记录解码生成的内容,也就是说子类实现decode方法时,如果得到了完整的消息,需要将消息加入到CodecOutputList中,CodecOutputList#newInstance是从FastThreadLocal中获取的,线程安全,每一个线程进行复用
-
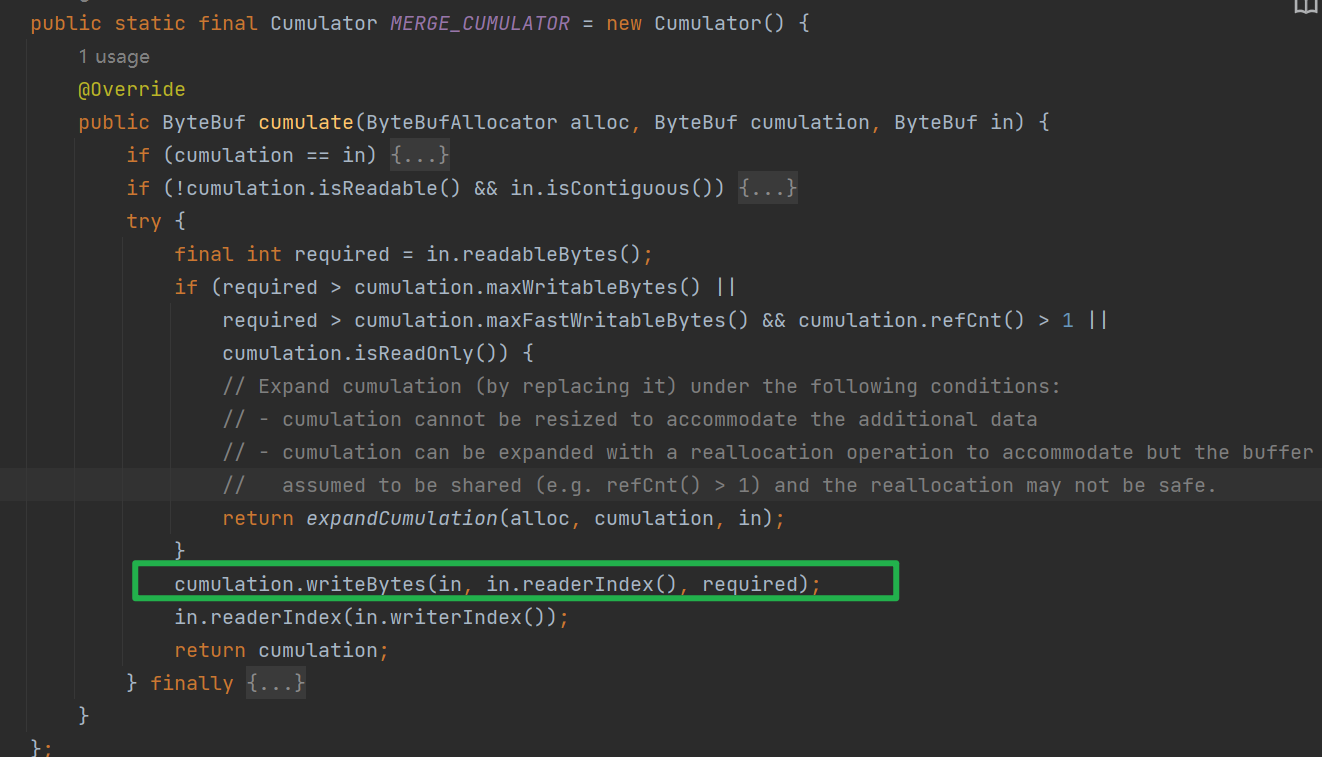
Cumulator:累积器,由于TCP存在粘包,半包的情况,NioSockectChannel在读取的时候不一定可以读取到一个完整的消息,所有需要使用Cumulator进行累计,netty提供了两种累积器的实现
-
合并:顾名思义,会将已经积攒的ByteBuf和当前需要累计的ByteBuf进行合并,是真真切切发生内存拷贝的
-
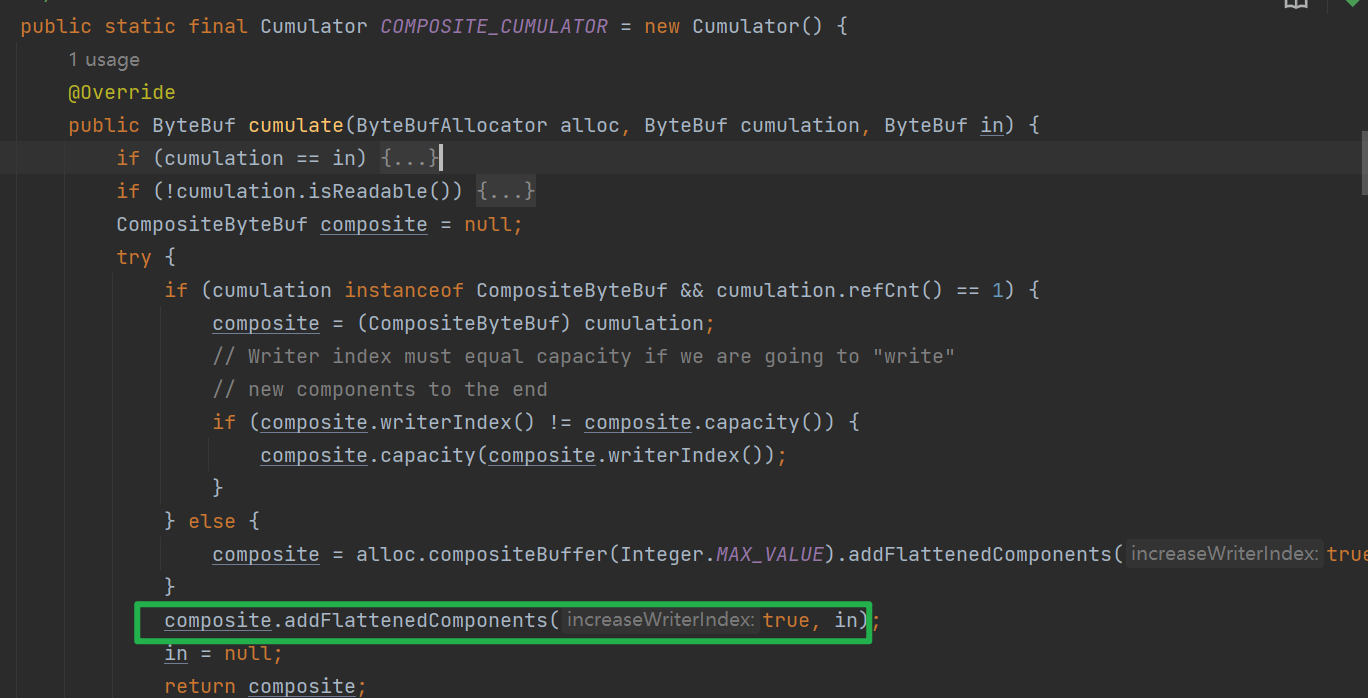
组合:这种策略下,会将已经积攒的ByteBuf和当前需要累计的ByteBuf进行组合——生成一个逻辑视图:CompositeByteBuf
-
-
模板模式:ByteToMessageDecoder将累积的过程进行了抽象,子类只需要实现decode将解码生成的消息写入到CodecOutputList中即可

3.1 FixedLengthFrameDecoder 定长消息
使用子类进行解码,需要保证发送来的消息长度是一致的!其使用字段frameLength记录完整消息的长度
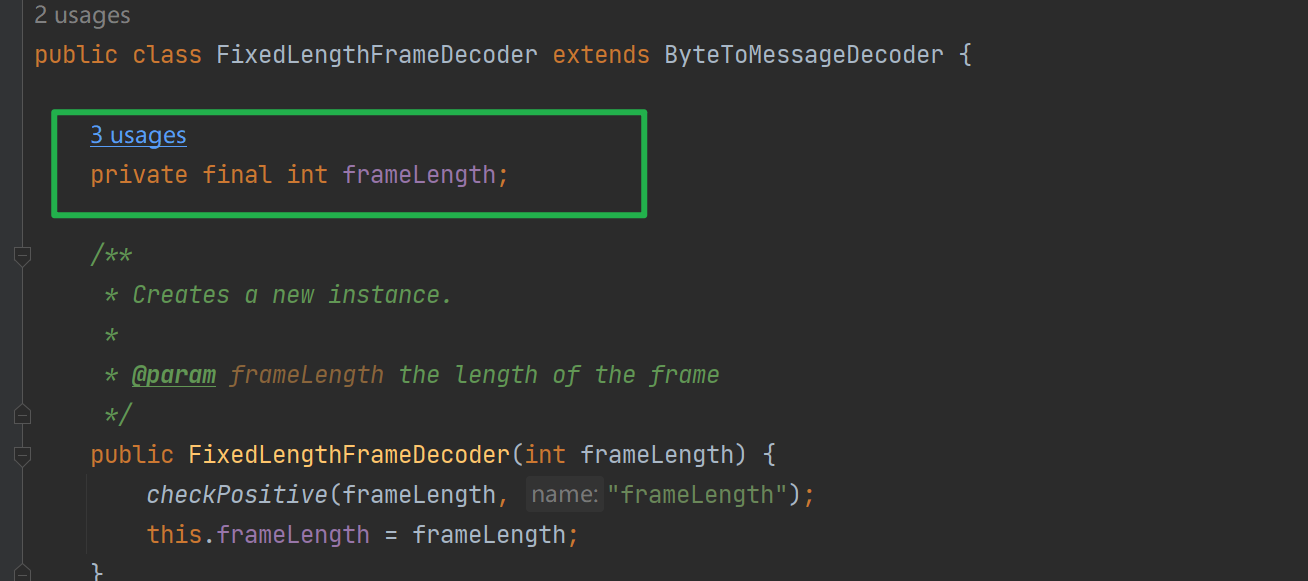
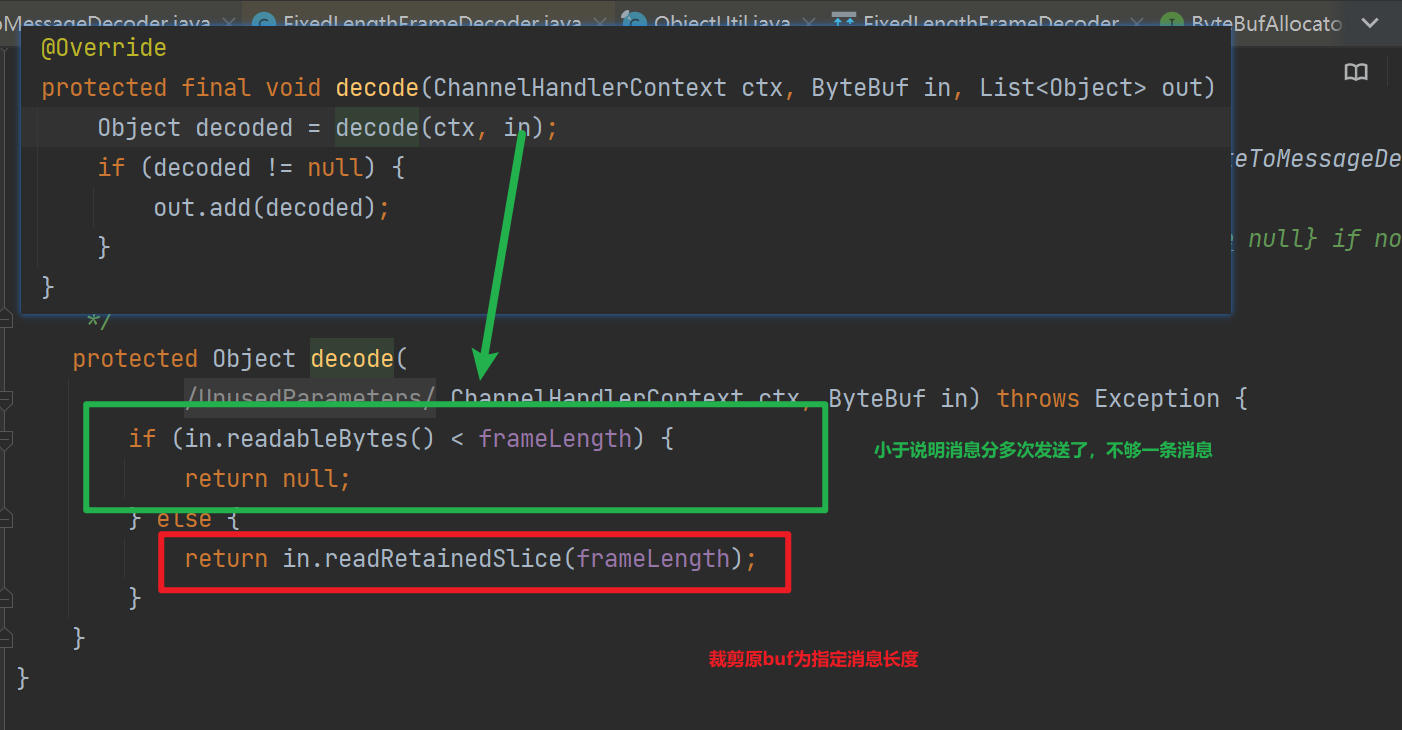
如下是解码源码:
3.2 LineBasedFrameDecoder 换行符解码器
顾名思义就是找到换行符所在的位置,分割出一条消息
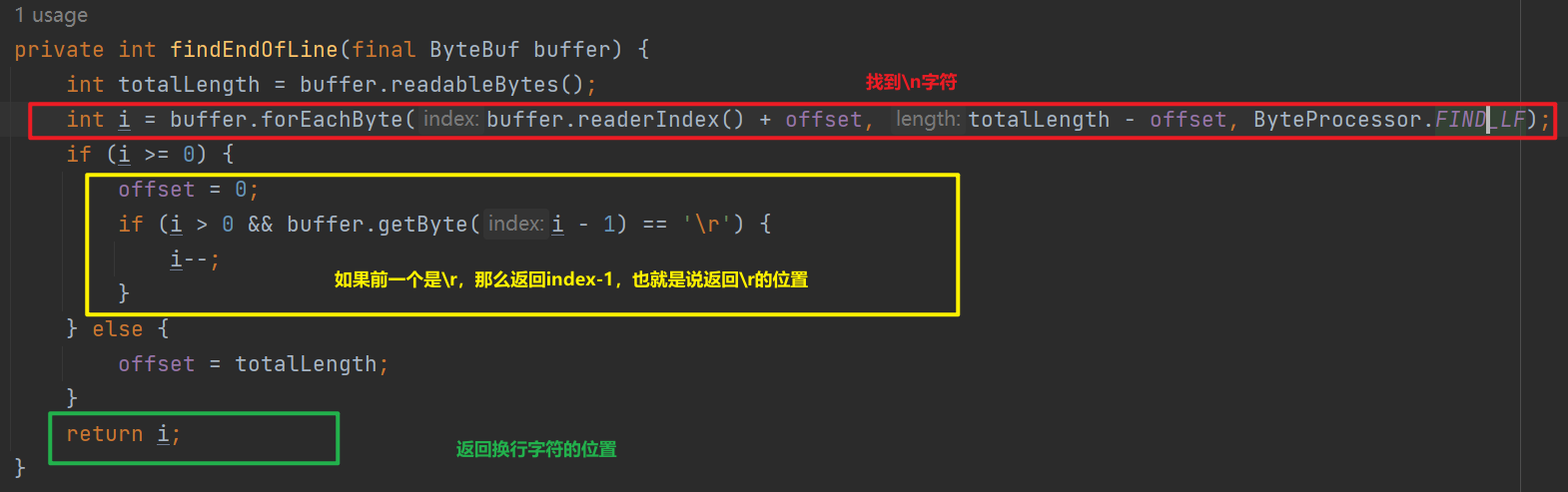
这个累有点鸡肋,因为不支持自定义换行符,如果换行符需要支持指定可以使用DelimiterBasedFrameDecoder
3.3 DelimiterBasedFrameDecoder 支持自定义分割符的解码器
原理和LineBasedFrameDecoder 类似,内部使用delimiters数组记录分割符是什么

3.4 LengthFieldBasedFrameDecoder
基于消息头的长度字段来确定每个消息的长度来解码出消息,相比于上面几种,它使用更加广泛的解码器(消息定长如果消息太短需要补齐,浪费网络资源,换行和分割符解码同样会浪费一些网络资源)
此类源码上的注释详细解释了如何使用,它有如下几个重要的参数:
- maxFrameLength : 发送的数据包最大长度;
- lengthFieldOffset :长度域偏移量,指的是长度域位于整个数据包字节数组中的下标;
- lengthFieldLength :长度域的自己的字节数长度。
- lengthAdjustment :长度域的偏移量矫正。 如果长度域的值,除了包含有效数据域的长度外,还包含了其他域(如长度域自身)长度,那么,就需要进行矫正。矫正的值为:包长 - 长度域的值 – 长度域偏移 – 长度域长。
- initialBytesToStrip :丢弃的起始字节数。丢弃处于有效数据前面的字节数量。比如前面有4个节点的长度域,则它的值为4。
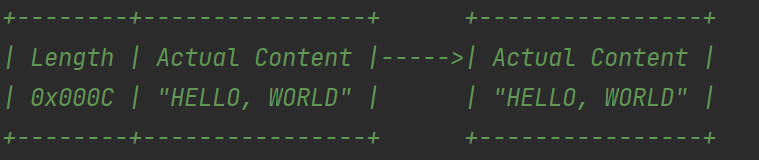
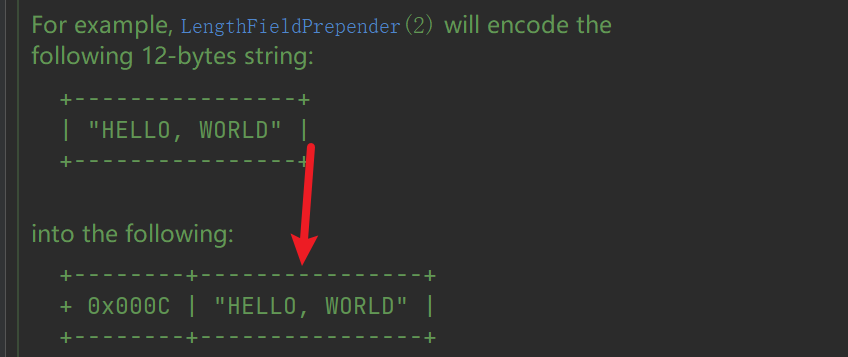
例子:

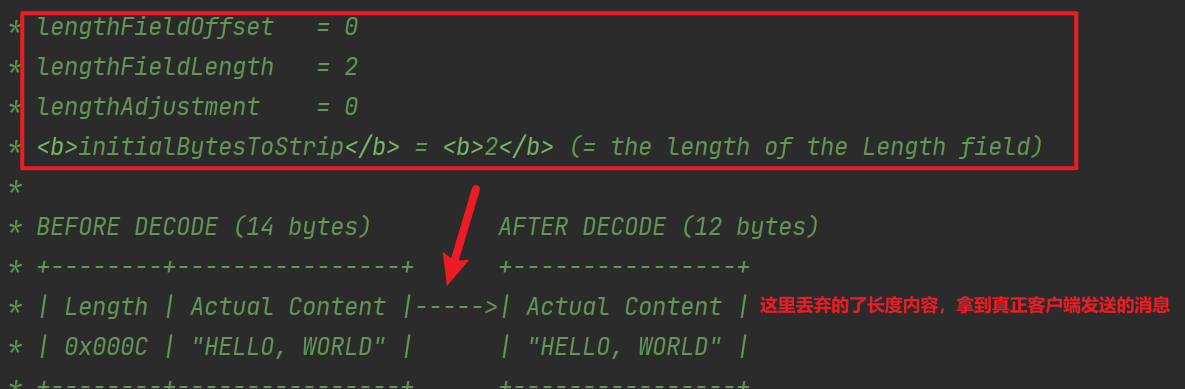
3.5 LengthFieldPrepender
在发送消息的前面添加长度字段,与 LengthFieldBasedFrameDecoder 配合使用,可确保粘包和半包问题不会发生。
因此它是一个ChannelOutboundHandler,其原理也比较简单,在发送消息前加上长度信息

四丶总结&启下
这一篇我们学习了netty是如何解决TCP协议中粘包半包的问题,以及粘包半包问题为何会出现,并学习netty中常用的编码解码器源码
其实netty对于其他协议,如:udp,websockect,http,smtp都有对应的实现,这也是为啥开发者喜欢使用netty的原因——不需要重复造轮子
另外netty还支持多种序列化反序列化方式:json,xml,Protobuf等
后续应该会更新netty追求卓越性能打造的一些轮子,如FastThreadLocal,对象池,内存池,时间轮。以及和学习交流群的小伙伴们一起基于netty写一个简陋的rpc框架,巩固一下netty的使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号