《深入理解Java虚拟机》第三章读书笔记(三)——经典垃圾回收器
一丶概述
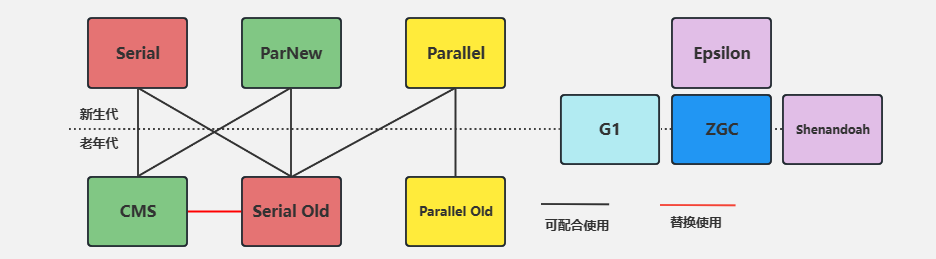
上图展示了 经典的垃圾回收器,其中Serial,ParNew,Parallel Scavenge(图中的Parallel) 作用在新生代Serial Old CMS,Parallel Old作用在老年代,这些垃圾回收器颜色相同表示通常搭配使用。G1,ZGC,Shenandoah垃圾收集器则抛弃了分代收集理论作用于整堆。下面将介绍这些垃圾回收器
二丶Serial 和 Serial Old
Serial 是作用在新生代的,使用标记复制算法且单线程进行垃圾收集的垃圾回收器(单线程意味着:回收垃圾的时候使用单个线程,并且回收垃圾的时候工作线程也停止)。它是客户端模式下默认的垃圾收集器,优点点在于简单高效,对于内存资源受限的环境,它是所有收集器里额外内存消耗最小的,并且没用线程切换的开销,因此在单核CPU下Serial表现甚至优于多核CPU。
Serial Old 是Serial的老年代版本,使用标记整理算法,除了和Serial搭配使用之外,它还是CMS老年代垃圾回收失败时的后备预案
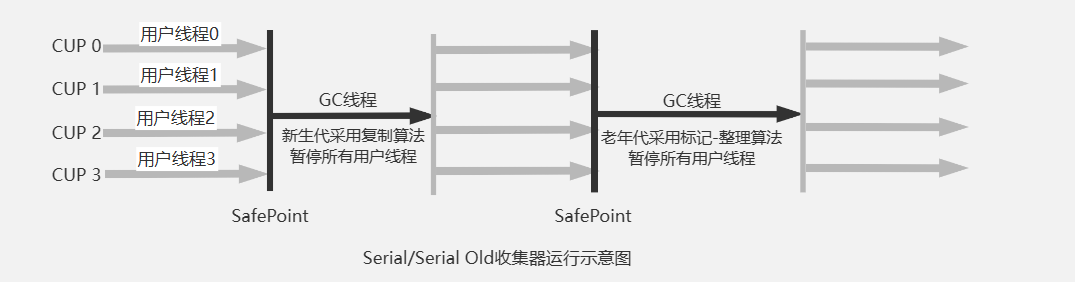
- -XX:+UseSerialGC :让虚拟机使用
Serial+Serial Old进行垃圾回收 - -XX:SurvivorRatio:控制Survivor 和 Eden的比值,如-XX:SurvivorRatio=8 表示Eden:Survivor=8:1
三丶ParNew
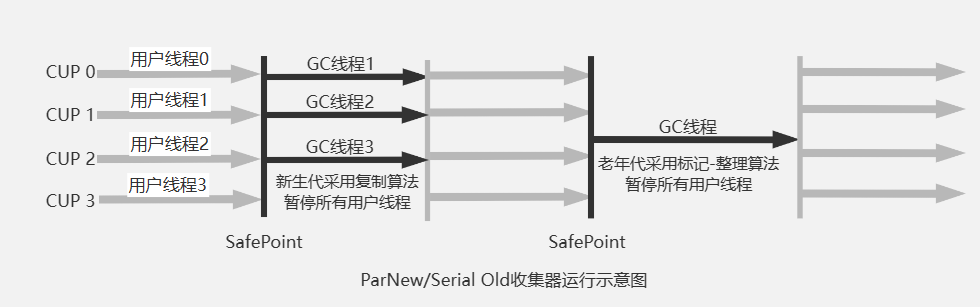
ParNew 可用认为是Serial的并行版本,作用于新生代,使用标记复制算法,它是激活CMS垃圾回收器之后默认的新生代垃圾回收器。
ParNew在单核CPU处理器环境中,不会比Serial更高效,因为它存在线程交互的开销。使用-XX:ParallelGCThreads=n限制垃圾收集的线程数
使用 -XX:+UseParNewGC 指定使用ParNew + Serial Old的组合,二者配合工作如下图。
四丶Parallel Scavenge
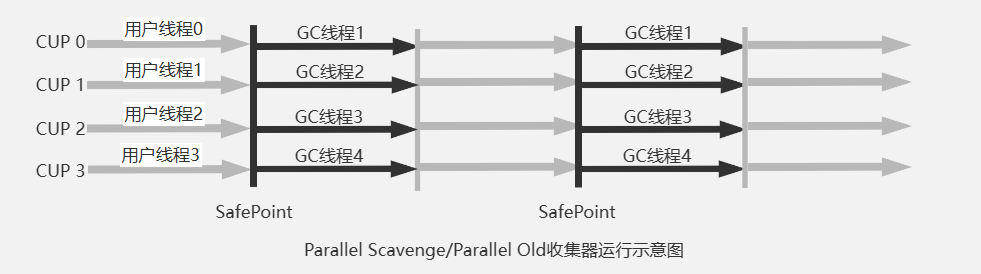
Parallel Scavenge 和ParNew 类似,作用于新生代,使用标记复制算法。但是它是专注于吞吐量的垃圾收集器。(吞吐量 = 用户代码运行时间 / 处理器总消耗时间(用户代码时间+GC时间))
-
-XX:+UseParallelGC虚拟机在Server模式下的默认值,开启后,使用 Parallel Scavenge + Serial Old的组合 -
-XX:MaxGCPauseMillis=n 收集器尽可能保证单次内存回收停顿的时间不超过这个值,但是并不保证不超过该值。(如果设置太小将导致Minor GC频繁) -
-XX:GCTimeRatio=n设置吞吐量的大小,取值范围0-100,假设GCTimeRatio的值为 n,那么系统将花费不超过1/(1+n)的时间用于垃圾收集 -
-XX:+UseAdaptiveSizePolicy开启后,无需人工指定新生代的大小(-Xmn)、 Eden和Survivor的比例(-XX:SurvivorRatio)以及晋升老年代对象的年龄(-XX:PretenureSizeThreshold)等参数,收集器会根据当前系统的运行情况自动调整
五丶Parallel Old
Parallel Old 是Parallel Scavenge的老年代版本,多线程,使用标记整理算法.-XX:+UseParallelGC 使用 Parallel Scavenge + Serial Old的搭配方式,并不能重复发挥服务器的多处理器并行处理能力。Parallel Old 出现后注重吞吐量的场景可用使用-XX:+UseParallelOldGC选择Parallel Scavenge + Parallel Old进行搭配使用
六丶CMS
CMS是一种以获取最短回收停顿时间为目标收集器,使用标记清除算法回收老年代。适合在关注服务响应速度,系统停顿时间的场景中使用,如B/S 系统。CMS的优势在于它使用了三色标记算法,实现了垃圾回收和用户线程的并行执行(初始标记和并发重新标记还是需要Stop The World)
1.CMS回收流程
-
初始标记
指的是寻找所有被 GCRoots 引用的对象,该阶段需要Stop the World ,这个步骤仅仅只是标记一下 GC Roots 能直接关联到的对象,并不需要做整个引用的扫描,因此速度很快。
-
并发标记
指的是对「初始标记阶段」标记的对象进行整个引用链的扫描,该阶段不需要Stop the World。 对整个引用链做扫描需要花费非常多的时间,因此通过
垃圾回收线程与用户线程并发执行,可以降低垃圾回收的时间。这也是 CMS 垃圾回收器能极大降低 GC 停顿时间的核心原因,但这也带来了一些问题,即:并发标记的时候,引用可能发生变化,因此可能出现错杀(是垃圾的对象没用被标记为垃圾,产生浮动垃圾),和错标(不是垃圾的对象被标记为垃圾的问题 -
重新标记
指的是对并发标记阶段出现的问题进行校正,该阶段需要Stop the World。 这一阶段解决并发标记阶段发生错标的问题。
-
并发清除
指的是将标记为垃圾的对象进行清除,该阶段不需要Stop the World。垃圾回收线程和用户线程并发进行。(这一步使用标记清除算法,所有可以和用户线程并行,但是标记清除会产生较多的内存碎片)

2.CMS 优点
并发收集,低停顿
将原本的标记信息,分为了初始标记,并发标记,重新标记,其中最为耗时的并发标记可以和用户线程并行,从而提高了垃圾回收的效率。垃圾回收的阶段(并发清除)也可以和用户线程并行,实现了垃圾回收的低停顿。
3.CMS 缺点
-
对 CPU 资源消耗较大
虽然使用多线程进行垃圾收集提升效率,但是也真是由于多线程垃圾收集流程会占用一些处理器的计算能力而导致应用程序变慢,降低吞吐量。
默认情况下 CMS 启用的垃圾回收线程数是
(CPU数量 + 3)/4,当 CPU 数量越大时,启用的垃圾回收线程数占比就越小。但如果 CPU 数量不足四个的时候,垃圾回收线程占用就达到了 50%,也就是说需要拿 50% 的 CPU 时间来进行垃圾回收。这就会极大地降低系统的吞吐量,这是让人无法接受的情况。
-
无法处理浮动垃圾。 由于 CMS 并发标记阶段会发生错标的情况,因此会有一些本该回收的垃圾对象无法被回收。此外在 CMS 进行并发清理的时候,用户线程同时在运行,也会产生一些浮动垃圾。因此对于 CMS 回收器来说,其需要留出一些空间给这些浮动垃圾存储,等到下一次垃圾回收才能进行清理。
可以通过
-XX:CMSInitiatingOccupancyFraction参数调节老年代空间使用多少之后触发CMS进行老年代的回收。如果在 CMS 运行期间发现预留的内存无法满足程序需要,就会提示
Concurrent Mode Failure错误。此时虚拟机采用后备方案:临时启用 Serial Old 回收器来重新进行老年代的垃圾回收,这时候 Stop the World 的时间可能就会很长了。 -
产生空间碎片。 由于 CMS 是基于
标记-清除算法实现的回收器,因此其会产生很多空间碎片,这会导致给大对象分配的时候很麻烦,会提前触发 Full GC。可以使用-XX:+UseCMSCompactAtFullCollection(默认是打开的)参数来让无法分配连续内存给大对象的时候,让FullGC触发的时候进行老年代的整理工作。该参数通常和
-XX:CMSFullGCsBeforeCompaction一起使用,-XX:CMSFullGCsBeforeCompaction可以控制CMS发生多少次不整理的FullGC后,下一次FullGC进行老年代的整理。
七丶G1
Garbage First 简称G,它开创了收集器面向局部收集,和基于Region的内存布局。
1.停顿模型
停顿模型:支持在长度为M毫秒的时间内,消耗在垃圾回收上的时间大概不超过N毫秒的目标
G1如何实现这个目标:
摒弃了面向整个区域(整个新生代,老年代,堆)进行垃圾回收的樊笼。而是面向堆内任何部分来组成Collection Set(CSet)进行回收,而不是看它属于哪个分代,而是看哪块内存中存放的垃圾数量多,回收收益最大,这便是G1的Mixed GC。支撑整个目标实现的是G1基于Rigion的堆内存布局
2.基于Region的堆内存布局

可以看出G1也是遵循分代收集理论的,但是堆内存布局不在坚持固定大小以及固定数量的分代区域划分,而是把堆分为若干个Region,每一个Region可以是Eden,Survivor,Old中一种。其中还存在Humongous用于存储大对象,如果一个对象超过Region大小的一半,那么视为大对象,G1将这部分区域视作老年代。
Region的大小可以通过-XX:G1HeapRegionSize进行设置,必须是2的幂次方,且介于1MB~32MB。超过一个Region大小的大对象讲分配在N个连续的Humongous中。
G1每次回收都是回收若干个Region大小的空间,这也可以避免整堆收集,并且会使用一个优先级列表来记录和跟踪每个Region中垃圾堆积的价值,价值即回收获得的空间大小,和回收所需的时间的经验值。每次垃圾回收都根据-XX:MaxGCPauseMillis(默认200ms)指定的停顿时间,选择回收价值最大的Region。
3. G1 如何解决跨代引用垃圾回收的问题
Region里面存在跨Region引用的问题依据是使用记忆集的思路去解决的。但是G1的记忆集更为复杂,每一个Region存在一个记忆集,这些记忆集会记录其他Region指向自己的指针,并标记这些指针位于哪些卡页的范围内。
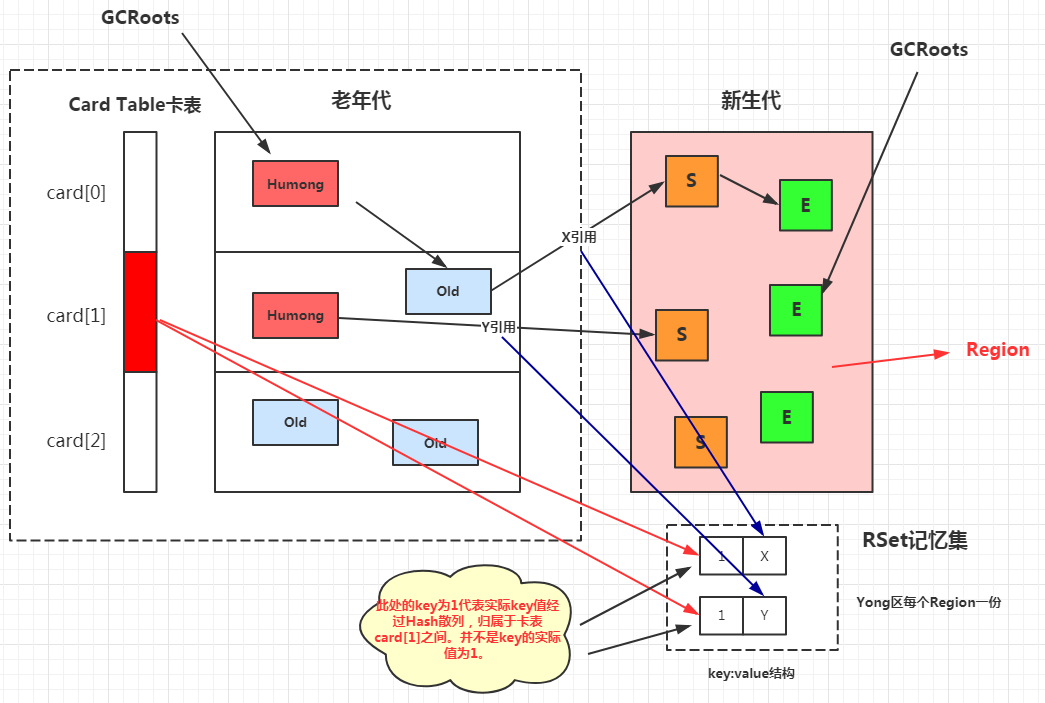
这种结构占用更大的内存,因为如果堆内存太小不太适合使用G1垃圾收集器。
4.G1 如何解决并发标记阶段,用户线程更改引用关系造成的问题
G1使用原始快照的方式解决此问题
当灰色对象要删除指向白色对象的引用关系时,就将删除的引用记录下来,并发扫描结束后,再将这些记录过引用关系的灰色对象为根,重新扫描一次。
此外G1还设计了两个指针称为TAMS(Top at mark start)用于在并发回收阶段,让用户线程在此区域分配内存给新对象。G1默认认为这个区域的对象是存活的。
5. G1 垃圾回收流程
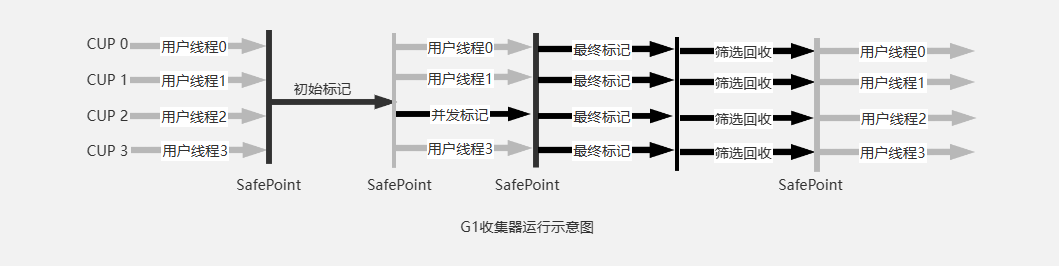
-
初始标记
标记了从GC Roots可以直接关联可达的对象。需要Stop the world
-
并发标记
和用户线程并发执行,从GC Roots开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象、
-
最终标记
需要Stop the world,处理并发标记阶段,使用原始快照SATB记录的对象。
-
筛选回收
更新Region统计信息,对各个Region的对象回收价值和成本进行排序,然后根据用户期望的停止时间来指定回收计划,然后选择多个Region组成
Collection Set(CSet)来进行回收,将回收这部分Region中存活的对象复制到空Region中,再清理整个旧Region的全部空间,这部分需要移动对象,依旧需要Stop the world,由多个线程并行完成。
6.G1 和CMS对比
6.1 G1优于CMS的点
- 可以指定最大停顿时间
- 可以按收益动态确定回收集
- 筛选回收使用标记复制算法,不会产生内存碎片,可以避免无法分配连续内存而进行下一次收集的情况的发生
6.2 CMS 由于G1的点
-
CMS的记忆集只有一份,占用内存小,但是G1每一个Region都有记忆集,所有G1占用更多内存
因此小内存机器上CMS更适合,堆内存足够大的适合使用G1也是不错的选择。
-
CMS使用写后屏障维护记忆集,并且是直接同步操作(更改引用的同时进行更新卡表)
而G1为了实现原始快照,还需要使用写前屏障,因此G1使用消息队列进行异步处理 记忆集的更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号