【collection】6.collection源码剖析
collection源码剖析
List
ArrayList
ArrayList底层是数组
add
新增元素的时候其实就是在数组下一个位置进行元素赋值,重点是在扩容上

扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 新空间扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果扩容1.5倍,比设置的值还小,你那么使用入参,否则使用1.5倍
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
// 判断是否超出容量
if (newCapacity - MAX_ARRAY_SIZE > 0) {
// MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 判断是否超出这个范围,如果超了,就最大只能用Integer.MAX_VALUE,否则就Integer.MAX_VALUE - 8
newCapacity = hugeCapacity(minCapacity);
}
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
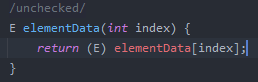
get
因为是数组,所以可以直接索引
LinkedList
节点数据结构
/**
* 泛型结构
* @param <E> node
*/
private static class Node<E> {
E item;
// 双向链表,向前和向后
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
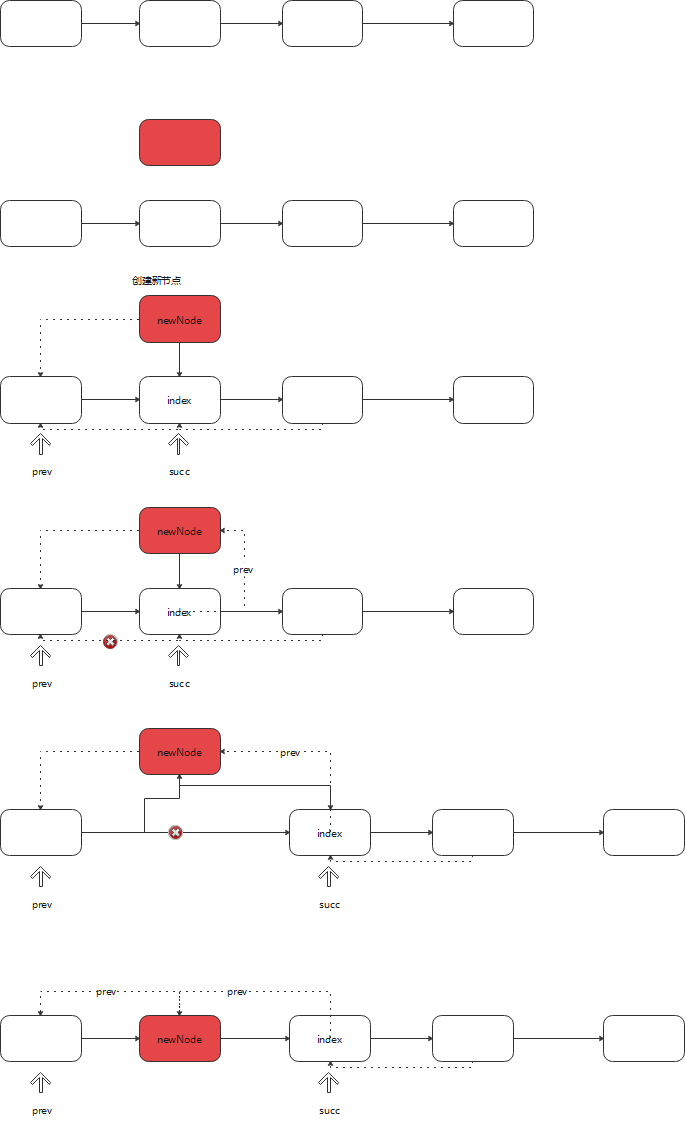
add
结论:新节点是插入到原来index的前面,原来index以及以后的节点,整体后移一位
/**
* Returns the (non-null) Node at the specified element index.
* 这里索引用了二分的思想,但是不是二分的算法
* 首先区分index是否小于一般,如果是,那么从前往后找
* 如果大于一般,那么从后往前找
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
// 从first往后
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 从last往前
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
// 断开原来的前置连接线,并修改为新的
succ.prev = newNode;
if (pred == null) {
first = newNode;
} else {
// 断开原来的后置,并更新
pred.next = newNode;
}
size++;
modCount++;
}
reomove,removeFirst,remove(index)
remove默认移除首节点,于removefirst作用相同
/**
* Unlinks non-null first node f.
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else {
// 更新完first之后,这里只需要把next.prev对象设置为null即可
next.prev = null;
}
size--;
modCount++;
return element;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 前置节点为空,那么直接把first移动到next
if (prev == null) {
first = next;
} else {
// 把前面节点的后置设置为下一个,跳过当前节点
prev.next = next;
x.prev = null;
}
// 如果next本来是空的,那么把last指针前移
if (next == null) {
last = prev;
} else {
// 不为空,那么把后面节点的前置指针跳过当前,设置前面一个节点
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove(index)和 remove(Object)类似
但是remove(object)的意思是判断空和非空,因为空的无法进行equals比较,循环查找
另外remove(index)也是先根据node方法定位关联节点
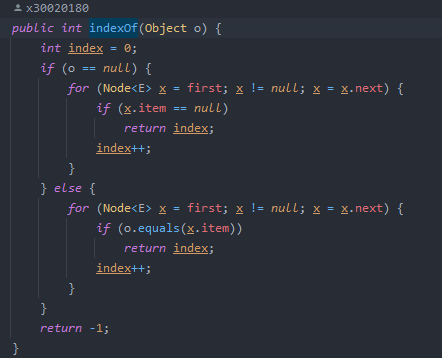
get,indexof查找
get方法也是用node(index)定位,indexof方法:判断空和非空,因为空的无法进行equals比较,循环查找
参考
https://pdai.tech/md/java/collection/java-collection-LinkedList.html#queue-方法
Stack
栈的实现主要依赖的是vector
这里主要是push和pop操作
扩容参考arraylist
push就是类似add,但是这里的操作都加了synchronized关键字,所以stack是线程安全的
CopyOnWriteArrayList
add操作
public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 先直接复制一个新的数组出来,并且直接把长度+1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 然后设置最后一个位置的节点
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
扩容
这个结构的扩容方式很简单暴力
直接复制出来一份满足要求大小的数组
newElements = Arrays.copyOf(elements, len + 1);
get
没有加锁
private E get(Object[] a, int index) {
return (E) a[index];
}
总结:
数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
这句话的意思是在循环操作的过程中,这个get结果是不可知的,只能保证在set的时候没问题,然后所有数据add完毕之后的结果符合预期
内存占用问题:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)
Set
HashSet
hashset本质其实就是hashmap
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
LinkedHashSet
与hashset相比就是构造函数不同

TreeSet
实现的是treemap
Queue
PriorityQueue
构造函数
/**
* 通过数组来存放堆的数据信息
*/
transient Object[] queue; // non-private to simplify nested class access
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
// 设置比较器,这个决定数据出入顺序
this.comparator = comparator;
}
add和offer
add和offer基本没差别,add也是调用的offer方法

我们重点看一下offer方法
public boolean offer(E e) {
if (e == null) {
throw new NullPointerException();
}
// 递增一波修改集合的次数
modCount++;
// 获取当前队列数量
int i = size;
// 如果达到上限,那么就对数组长度进行扩容
if (i >= queue.length) {
grow(i + 1);
}
// 数据个数++
size = i + 1;
// 如果队列是空的,那么直接赋值到0位置
if (i == 0) {
queue[0] = e;
} else {
// 如果不为空,那么就需要计算一下位置
siftUp(i, e);
}
return true;
}
/**
* Increases the capacity of the array.
* 数据扩容
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// 获取旧数组容量大小
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
// 判断old是否小于64,如果是,那么扩大原来(长度+2),否则扩大原来的50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1));
// overflow-conscious code overflow检测
if (newCapacity - MAX_ARRAY_SIZE > 0) {
newCapacity = hugeCapacity(minCapacity);
}
// 拷贝数组,并创建新的数组长度
queue = Arrays.copyOf(queue, newCapacity);
}
private void siftUpComparable(int k, E x) {
// 要求元素本身具备comparable接口能力
Comparable<? super E> key = (Comparable<? super E>) x;
// 当当前k数量大于0
while (k > 0) {
// 寻找parent。 k是数据实际个数,而下标是从0开始的,那么就需要在原来的基础上-1
int parent = (k - 1) >>> 1;
// 获取父节点位置的值
Object e = queue[parent];
// 比较,如果key大于父节点,那么就放后面,java默认小的再前
if (key.compareTo((E) e) >= 0) {
break;
}
// 如果比parent值要小,那么就取代,吧父节点的值往后移
// k是当前位置,parent是父节点位置,e是父节点元素,key才是当前元素
queue[k] = e;
// 指针偏移到父节点从新遍历
k = parent;
}
queue[k] = key;
}
这是一个完全二叉树,可以采用数组的方式存储,那么每个父节点对应的子节点都是 (node * 2)和(node * 2)+1

element和peek
和add还有offer类似,element和peek也是相互调用的关系,区别是element会抛出异常,peek不会,会直接返回null


peek不会对原来的数组元素做出改变,只会取出头元素,也就是说peek只会一直取索引位置为0的元素
remove和poll
remove也是调用的poll函数

public E poll() {
if (size == 0) {
return null;
}
// 数组长度--
int s = --size;
modCount++;
// 获取0位置的节点
E result = (E) queue[0];
// 获取末尾节点数据
E x = (E) queue[s];
// 设置为空,然后重新调整数组
queue[s] = null;
if (s != 0) {
siftDown(0, x);
}
return result;
}
参考
Deque
这是一个双端队列, 具体实现可以参考LinkedList
ConcurrentLinkedQueue
offer操作
使用idea进行debug测试验证的时候,发现,queue对象的第一次的入队之后tail节点指向了自己
tail = tail.next 然后就是死循环遍历
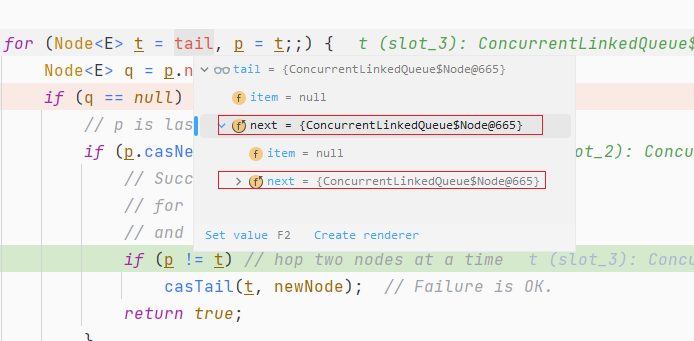
解决办法是关闭idea的debug的时候的toString方法,因为这个toString方法会对集合进行遍历
遍历的时候会调用这个方法
java.util.concurrent.ConcurrentLinkedQueue#first
而这个方法会更新head,并且会调用节点的lazySetNext
java.util.concurrent.ConcurrentLinkedQueue#updateHead
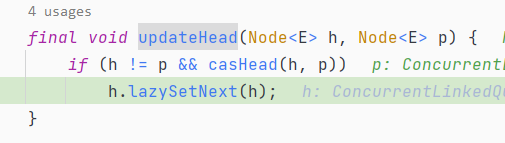
在这个lazySetNext会吧head指向自己,这里的head是第一个头节点,那就会出现循环情况,至于putOrderedObject方法是关于指令重排序的,不在本次讨论范围内
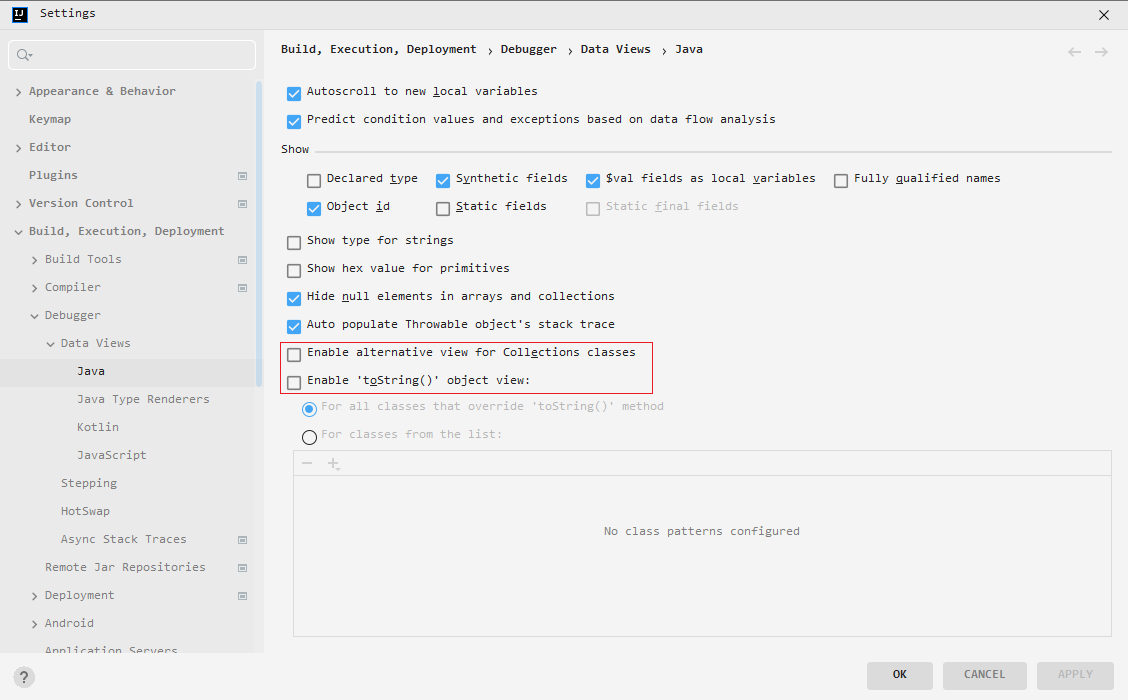
debug异常解决办法
关掉这2个选项即可
offer操作
/**
* Inserts the specified element at the tail of this queue.
* As the queue is unbounded, this method will never return {@code false}.
*
* 注意下这里更新tail位置的时候是延迟了一次的,也就是说tail指向的节点是在下次入队的时候更新
*
* @return {@code true} (as specified by {@link Queue#offer})
* @throws NullPointerException if the specified element is null
*/
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
// 无限循环,cas操作
// t 指向tail位置
// p 赋值为t
// q 为p的next
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node 找到正确的尾部节点,没有被外部线程更新
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
// 判定cas成功之后,第一次并不会更新tail对象因为这个时候p==t恒成立
// 只有在第二次进来的时候,发现q!=null的情况下,进入第三个判断
// 这个时候p指向的是t的next的时候,也就是进入了第三个判断了,那么这个时候我们再更新tail
if (p != t) { // hop two nodes at a time
// 更新tail位置,这样做的好处是对tail的更新次数变少了,对tail的读取
casTail(t, newNode); // Failure is OK.
}
return true;
}
// Lost CAS race to another thread; re-read next
} else if (p == q) {
// 从新设置队列尾部,p节点是null的head节点刚好被出队,更新head节点时h.lazySetNext(h)把旧的head节点指向自己
// 也就是出现循环的场景,比如debug的时候执行一个toString也会有这个问题,迭代循环的时候会调用first方法,也会调用lazySetNext
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
} else {
// Check for tail updates after two hops.
// 重新设置p对象,因为这个时候q不为空,说明tail指向的不是真正的末尾节点
// 如果p!= t,那么就重新设置t=tail对象。如果发生t!=(t=tail)那么可能是多线程情况下,差距tail有点多,那么直接返回tail
// q为p的next,相当于是往下移动一位
// 然后把新的p作为条件重新循环
p = (p != t && t != (t = tail)) ? t : q;
}
}
}
poll
public E poll() {
restartFromHead:
for (;;) {
// p初始化为头节点
// q 为p的下一个节点
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 从头节点获取数据,cas操作设置为空
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// 这个地方和之前offer一样,也是在第二次的时候才进行更新head
if (p != h) {
// hop two nodes at a time3
// 把head设置为p,并lazySetNext
updateHead(h, ((q = p.next) != null) ? q : p);
}
return item;
} else if ((q = p.next) == null) {
// 如果后续节点为空,那么重新更新头节点,这里可能会发生自循环
// 把head设置为p,并lazySetNext
updateHead(h, p);
return null;
} else if (p == q) {
// 发生自循环,这种情况就重新获取数据
continue restartFromHead;
} else {
// 如果匹配不成功,往后续节点遍历
p = q;
}
}
}
}
remove&size
- 这里需要注意下的是,size方法返回的时候是直接循环遍历链表进行计算的
- remove也是循环链表比较,然后再cas删除的
HOPS(延迟更新的策略)的设计
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的
著作权归@pdai所有 原文链接:https://pdai.tech/md/java/thread/java-thread-x-juc-collection-ConcurrentLinkedQueue.html
参考
https://www.cnblogs.com/zaizhoumo/p/7726218.html
https://www.cnblogs.com/sunshine-2015/p/6067709.html
https://blog.csdn.net/AUBREY_CR7/article/details/106331490
https://tech.meituan.com/2014/09/23/java-memory-reordering.html
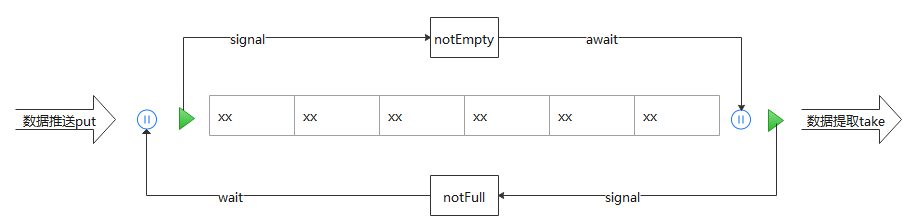
BlockingQueue
这个类是最常用来做生产消费队列的类,可实现offer或take的阻塞操作
这里我们用ArrayBlockingQueue做例子来看看这个类
对象的阻塞通过2个condition锁进行控制
private final Condition notEmpty;
private final Condition notFull;
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
put/offer
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 无限超时等待
while (count == items.length) {
// notFull 被阻塞,也就是现在队列是满的,等待被唤醒,那么就需要
// notFull.signal()!来进行唤醒,那么我们吧这个放到队列数据出库之后
notFull.await();
}
enqueue(e);
} finally {
lock.unlock();
}
}
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
checkNotNull(e);
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 队列满了
while (count == items.length) {
if (nanos <= 0) {
return false;
}
// 在这里进行阻塞等待,返回剩余等待时间
nanos = notFull.awaitNanos(nanos);
}
// 数据入库
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
take/poll
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 无限超时等待
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
if (nanos <= 0)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
return dequeue();
} finally {
lock.unlock();
}
}
实战样例
import lombok.Data;
import lombok.ToString;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.stream.IntStream;
/**
* 功能描述
*
* @since 2022-11-25
*/
public class Code008ConsumerAndProduct {
@Data
@ToString
static class ThreadEleObject {
private String serviceName;
private String methodName;
private Map args;
}
static class ProviderService implements Runnable {
private BlockingQueue<ThreadEleObject> blockingQueue;
private static boolean stopFlag = false;
public ProviderService(BlockingQueue blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
// 定时生产数据
while (!stopFlag) {
try {
ThreadEleObject threadEleObject = new ThreadEleObject();
threadEleObject.setServiceName("threadDemoService");
threadEleObject.setMethodName("test1");
Random random = new Random();
threadEleObject.setArgs(new HashMap() {
{
put(random.nextInt(), random.nextLong());
put(random.nextInt(), random.nextLong());
put(random.nextInt(), random.nextLong());
put(random.nextInt(), random.nextLong());
}
});
blockingQueue.put(threadEleObject);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class ConsumeService implements Runnable {
private BlockingQueue<ThreadEleObject> blockingQueue;
private static boolean stopFlag = false;
public ConsumeService(BlockingQueue blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
while (!stopFlag) {
try {
// 获取元素bean对象
ThreadEleObject ele = blockingQueue.poll();
if (ele != null) {
System.out.println(ele.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
private static void testConcrrent() {
BlockingQueue threadServicequeue = new ArrayBlockingQueue(1024);
BlockingQueue<Object> executorServiceQueue = new ArrayBlockingQueue(1024);
// 启动生产/消费
ProviderService providerService = new ProviderService(threadServicequeue);
ConsumeService consumeService = new ConsumeService(threadServicequeue);
ExecutorService executorService = Executors.newCachedThreadPool();
IntStream.range(0, 1).forEach(i -> {
executorService.submit(providerService);
});
IntStream.range(0, 30).forEach(i -> {
executorService.submit(consumeService);
});
}
public static void main(String[] args) {
try {
testConcrrent();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号