【collection】5.Map关键子类源码剖析
Map源码剖析
HashMap&LinkedHashMap&Hashtable

hashMap默认的阈值是0.75
HashMap put操作
put操作涉及3种结构,普通node节点,链表节点,红黑树节点,针对第三种,红黑树节点,我们后续单独去学习,这里不多做扩散
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) {
// 初始化哈希数组,或者对哈希数组扩容,返回新的哈希数组
tab = resize();
n = tab.length;
}
// 相当于取余
i = (n - 1) & hash;
p = tab[i];
if (p == null) {
// 直接放普通元素
tab[i] = newNode(hash, key, value, null);
} else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {
// 存在同位元素,也就是出现了hash碰撞
e = p;
} else if (p instanceof TreeNode) {
// 如果当前位置已经是红黑树节点,那么就put红黑色
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
// 遍历哈希槽后面链接的其他元素(binCount统计的是插入新元素之前遍历过的元素数量)
// 这里就是链表类型
for (int binCount = 0; ; ++binCount) {
// 后继节点为空
if ((e = p.next) == null) {
// 拼接到后继节点上
p.next = newNode(hash, key, value, null);
/**
* 哈希槽(链)上的元素数量增加到TREEIFY_THRESHOLD后,这些元素进入波动期,即将从链表转换为红黑树
* 注意这个TREEIFY_THRESHOLD 是8,为什么是8??
* 每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。由于红黑树有自平衡的特点,可以防止不平衡情况的发生,
* 所以可以始终将查找的时间复杂度控制在 O(log(n))。
* 最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
* 链表查询的时候使用二分查询,平均查找长度为n/2,长度为8的时候,为4,而6/2 = 3
* 而如果是红黑树,那么就是log(n) ,长度为8时候,log(8) = 3, log(6) =
* 这个时候我们发现超过8这个阈值之后,链表的查询效率会越来越不如红黑树
*/
if (binCount >= TREEIFY_THRESHOLD - 1) {
// -1 for 1st
treeifyBin(tab, hash);
}
break;
}
// 判断链表中的后继原始是否hash碰撞,如果发生了hash碰撞break
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果存在同位元素(在HashMap中占据相同位置的元素)
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 判断是否需要进行覆盖取值,因为key相同,那么直接取代,否则什么也不操作
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
总结关键信息:
哈希槽(链)上的元素数量增加到TREEIFY_THRESHOLD后,这些元素进入波动期,即将从链表转换为红黑树
注意这个TREEIFY_THRESHOLD 是8,为什么是8??
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。由于红黑树有自平衡的特点,可以防止不平衡情况的发生,
所以可以始终将查找的时间复杂度控制在 O(log(n))。
最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
链表查询的时候使用二分查询,平均查找长度为n/2,长度为8的时候,为4,而6/2 = 3
而如果是红黑树,那么就是log(n) ,长度为8时候,log(8) = 3, log(6) =
这个时候我们发现超过8这个阈值之后,链表的查询效率会越来越不如红黑树
HashMap get,remove操作
除了红黑树的查找比较特殊,其余的链表查找就是暴力搜索,只是平均下来找到一个元素的话是n/2
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab = table;
Node<K,V> p;
int n, index;
if (tab != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {
// 找到节点,并且是首节点
node = p;
} else if ((e = p.next) != null) {
if (p instanceof TreeNode) {
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
} else {
// 链表查询,暴力搜索
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 移除节点,可能只需要匹配hash和key就行,也可能还要匹配value,这取决于matchValue参数
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {
// 移除红黑树节点
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
} else if (node == p) {
// 移除首节点为后继节点
tab[index] = node.next;
} else {
// 链表断开
p.next = node.next;
}
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
HashMap扩容
链表拆分,进入新的容器
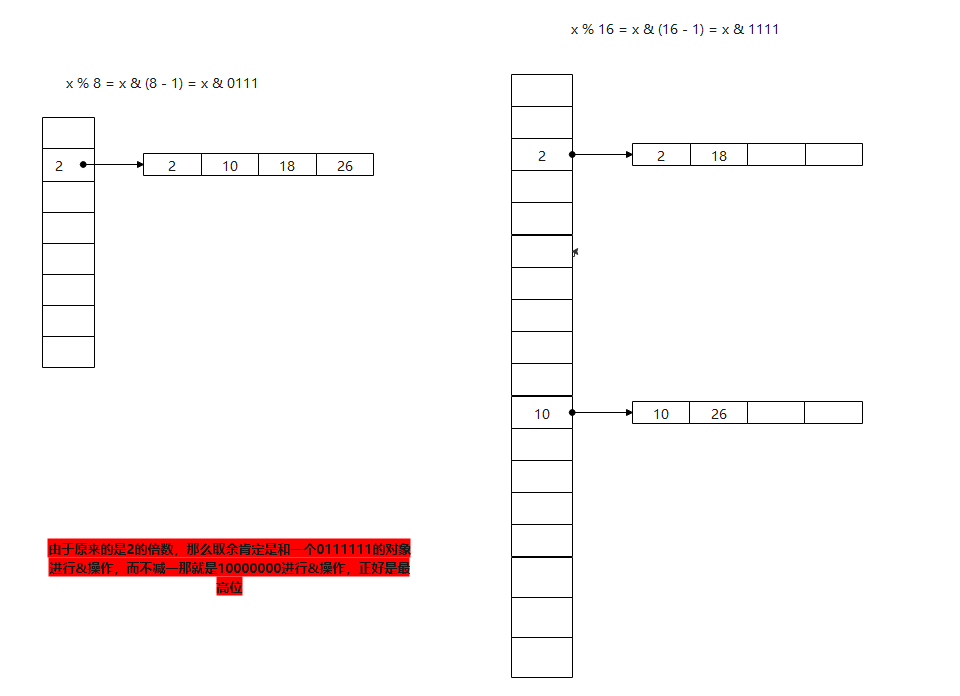
这里有个知识点:如何使用位运算进行取模
a % b == a & (b - 1)
我们拆分链表的思路也是这样:比如原来长度为8的链表,也就是 x % 8 = x & (8 - 1) = x & 0111 也就是取后三位,那么扩容之后重新排序的话,容量扩大一倍,也就是16,那么这个时候就是 x % 16 = x & (16 - 1) = x & 1111 这个时候我们发现和之前的区别就是最高位由原来的0变为1,如果还在后三位范围内,那么新容量中的位置是不会变的
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧阈值
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 判断旧容量是否已经超过最大值
if (oldCap >= MAXIMUM_CAPACITY) {
// 如果已经达到1 << 30;,那么直接设置为Integer.MAX_VALUE; 0x7fffffff
threshold = Integer.MAX_VALUE;
return oldTab;
} else {
// mod by xiaof 尝试将哈希表数组容量加倍,注意这里是左移,也就是说*2
newCap = oldCap << 1;
// 如果容量成功加倍(没有达到上限),则将阈值也加倍
if (newCap < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {
newThr = oldThr << 1;
}
}
// else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
// oldCap >= DEFAULT_INITIAL_CAPACITY) {
// newThr = oldThr << 1; // double threshold
// }
} else if (oldThr > 0) {
// initial capacity was placed in threshold
newCap = oldThr;
} else { // zero initial threshold signifies using defaults
// 如果实例化HashMap时没有指定初始容量,则使用默认的容量与阈值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
/*
* 至此,如果newThr==0,则可能有以下两种情形:
* 1.哈希数组已经初始化,且哈希数组的容量还未超出最大容量,
* 但是,在执行了加倍操作后,哈希数组的容量达到了上限
* 2.哈希数组还未初始化,但在实例化HashMap时指定了初始容量
*/
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
// 如果新容量小于最大允许容量,并且新容量*装载因子之后还是小于最大容量,那么说明不需要扩容,那么直接使用ft作为新的阈值容量
// 如果新容量已经超过最大容量了,那么就直接返回最大允许的容量
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新阈值
threshold = newThr;
// 新的容器对象,创建容量为新的newCap
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 遍历原来的数据,准备转移到新的容器上
for (int j = 0; j < oldCap; ++j) {
// 获取旧容器对象
Node<K,V> e = oldTab[j];
if (e != null) {
// 把原来的数组中的指针设置为空
oldTab[j] = null;
if (e.next == null) {
// 重新计算hash索引位置,计算hash位置的方式防止数组越界的话,那么就设置hashcode & 长度 - 1
newTab[e.hash & (newCap - 1)] = e;
} else if (e instanceof TreeNode) {
// 红黑树,这里是对红黑树进行拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
} else { // preserve order
// lo对应的链表是数据不会动的
Node<K,V> loHead = null, loTail = null;
// hi对应的链表标识是需要去新容器新的位置的
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 这个是链表的情况下进行拆分
// 因为num % 2^n == num & (2^n - 1),容量大小一定是2的N次方
do {
next = e.next;
// 注意:e.hash & oldCap,注意这里是对老的容量oldCap进行计算这一步就是前面说的判断多出的这一位是否为1
// 因为新的是老的2倍,新节点位置是否需要发生改变,取决于最高位是否为0
// 若与原容量做与运算,结果为0,表示将这个节点放入到新数组中,下标不变
// 由于原来的是2的倍数,那么取余肯定是和一个0111111的对象进行&操作,而不减一那就是10000000进行&操作,正好是最高位
if ((e.hash & oldCap) == 0) {
// 最高位为0,那么位置不需要改变,本身就在原来容量范围内的数据
// 直接加入lotail,并判断是否需要初始化lotail
if (loTail == null) {
loHead = e;
} else {
loTail.next = e;
}
loTail = e;
} else {
// 最高位是1,那么就需要进行切换位置
if (hiTail == null) {
hiHead = e;
} else {
hiTail.next = e;
}
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 最后返回最新的容器对象
return newTab;
}
LinkedHashMap
基本和hashmap差不多,唯一需要注意下的是
还有一个核心点就是linkedHashMap覆盖了newNode方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 这里创建了linkedhashmap对象
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 创建完成之后,就添加到链表中连接起来
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
插入覆盖afterNodeAccess
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
// 获取节点 b -> p -> a
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 断开尾部连接
p.after = null;
// 如果前置节点是空的,那么就吧A作为head节点
if (b == null) {
head = a;
} else {
// 如果前置节点不为空,那么就吧前置节点连接到后置节点,吧中间节点断开
b.after = a;
}
// 后置节点不为空,那么就吧后置节点连接到前置节点上
if (a != null) {
a.before = b;
} else {
// 如果后置节点为空,那么重新设置tail指向before节点
last = b;
}
// 重新连接当前这个节点到末尾
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeInsertion在linkedhashmap中作用不大
/**
*
* +----+ +----+ +----+
* | b | ---> | p | ---> | a |
* +----+ +----+ +----+
* @param e
*/
void afterNodeRemoval(Node<K,V> e) { // unlink
// 移除节点
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null) {
head = a;
} else {
b.after = a;
}
if (a == null) {
tail = b;
} else {
a.before = b;
}
}
综上:linkedhashmap相对hashmap其实就是多加了一个链表把所有的数据关联起来,只有在遍历的时候才能体现出来有序,其他的操作是没有差别的
关于hashtable
首先hashtable是线程安全的,因为它所有的函数都加上了synchronized
链表头插法,没有红黑树的转换
初始化容量的时候默认是11,是奇数,而hashmap全都是2的幂次方
hashtable允许key为null
rehash函数
常用的hash函数是选一个数m取模(余数),这个数在课本中推荐m是素数,但是经常见到选择m=2n,因为对2n求余数更快,并认为在key分布均匀的情况下,key%m也是在[0,m-1]区间均匀分布的。但实际上,key%m的分布同m是有关的。
证明如下: key%m = key - xm,即key减掉m的某个倍数x,剩下比m小的部分就是key除以m的余数。显然,x等于key/m的整数部分,以floor(key/m)表示。假设key和m有公约数g,即key=ag, m=bg, 则 key - xm = key - floor(key/m)m = key - floor(a/b)m。由于0 <= a/b <= a,所以floor(a/b)只有a+1中取值可能,从而推导出key%m也只有a+1中取值可能。a+1个球放在m个盒子里面,显然不可能做到均匀。
由此可知,一组均匀分布的key,其中同m公约数为1的那部分,余数后在[0,m-1]上还是均匀分布的,但同m公约数不为1的那部分,余数在[0, m-1]上就不是均匀分布的了。把m选为素数,正是为了让所有key同m的公约数都为1,从而保证余数的均匀分布,降低冲突率。
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
// 这里重新计算容量的办法是容量扩大一倍,然后+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE) {
// Keep running with MAX_ARRAY_SIZE buckets
return;
}
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 重新把旧的原始转移到新数组上
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 这里因为容量是奇数,那么就需要使用%取余,而不是位运算 -》 a & (b - 1)
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
参考
https://www.cnblogs.com/tuyang1129/p/12368842.html -- 链表拆分
https://www.cnblogs.com/lyhc/p/10743550.html - linkedhashmap
ConcurrentHashMap
put操作
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 本质上和hashmap没有什么差别,都是把hashcode进行对半异或,这样就可以用一半的位数,集合了32位长度的信息
int hash = spread(key.hashCode());
int binCount = 0;
Node<K,V>[] tab = table;
// 这里循环的目的是cas的重试操作
for (;;) {
// 指向待插入元素应当插入的位置
Node<K,V> f;
// 元素f对应的哈希值
int fh;
// 当前hash表数组的长度容量
int n;
int i;
// 如果哈希数组还未初始化,或者容量无效,则需要初始化一个哈希数组
if (tab == null || (n = tab.length) == 0) {
tab = initTable();
// 这里n -1 & hash 是经典取余操作,参考之前hashmap
} else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果当前位置是空的,那么就可以通过cas设置对应的值
Node<K, V> newNode = new Node<K,V>(hash, key, value, null);
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null, newNode)) {
// 插入完成,跳出循环,如果更新失败,重新循环进入
break; // no lock when adding to empty bin
}
} else if ((fh = f.hash) == MOVED) {
/*
* 如果待插入元素所在的哈希槽上已经有别的结点存在,且该结点类型为MOVED
* 说明当前哈希数组正在扩容中,此时,可以尝试加速扩容过程
*/
tab = helpTransfer(tab, f);
} else {
V oldVal = null;
// 这里避免并发,对f节点的引用进行上锁
synchronized (f) {
// 如果tab[i]==f,则代表当前待插入状态仍然可信
if (tabAt(tab, i) == f) {
// fh > 0 标识不是在扩容,是正常节点
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到对应的值
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
// 记录同位元素旧值
oldVal = e.val;
// 如果允许覆盖,则存入新值
if (!onlyIfAbsent) {
e.val = value;
}
// 跳出循环
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
} else if (f instanceof TreeBin) {
// 如果当前哈希槽首个元素是红黑树(头结点)
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果对已有元素搜索过,则计数会发生变动,这里需要进一步观察
if (binCount != 0) {
// 哈希槽(链)上的元素数量增加到TREEIFY_THRESHOLD后,这些元素进入波动期,即将从链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD) {
// 注意,这里也只是锁了这一个节点,注意,这里不一定一定是转换为红黑树
// 如果整个tab长度是小于64的话,这里会选择自动扩容,如果已经超过64了,才考虑转换红黑树
treeifyBin(tab, i);
}
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
get和remove操作
略,就是根据索引找节点
扩容
核心方法就是transfer
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length;
// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
int stride = (NCPU > 1) ? (n >>> 3) / NCPU : n;
if (stride < MIN_TRANSFER_STRIDE) {
stride = MIN_TRANSFER_STRIDE; // subdivide range
}
if (nextTab == null) { // initiating
try {
// 直接扩大一倍
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。, 这个在put的时候会判断节点hash值,用来判断是否需要协助扩容
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// 循环所有的节点位置,判断是否需要进行迁移
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing) {
advance = false;
} else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
} else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 真正的开始数据迁移,先对f节点上锁,f是tab中的一个位置
synchronized (f) {
// 保证数据正确性没有发生变化
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 头节点的 hash 大于 0,说明是链表的 Node 节点
if (fh >= 0) {
// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,
// 需要将链表一分为二,
// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的
// lastRun 之前的节点需要进行克隆,然后分到两个链表中
int runBit = fh & n;
Node<K,V> lastRun = f;
// 循环链表,获取到尾节点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
} else {
hn = lastRun;
ln = null;
}
// 从头循环到尾部
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash;
K pk = p.key;
V pv = p.val;
// ph是这个节点的hash值&n如果为0,说明再n-1部分,位置没变,还是放入之前的位置
if ((ph & n) == 0) {
ln = new Node<K,V>(ph, pk, pv, ln);
} else {
// 不为0,说明再n-1上面的位置,位置变了,那么就重新设置位置
hn = new Node<K,V>(ph, pk, pv, hn);
}
}
// 其中的一个链表放在新数组的位置 i
setTabAt(nextTab, i, ln);
// 把head放到数组i+n的位置
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
advance = true;
} else if (f instanceof TreeBin) {
// 红黑树的迁移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
TreeMap
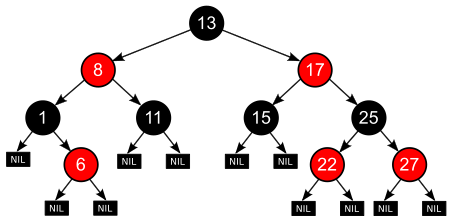
事先说明,这个集合对象实现是基于红黑树实现的
红黑树是一种近似平衡的二叉查找树,它能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍
复习一下红黑树的定义:
性质1. 结点是红色或黑色。
性质2. 根结点是黑色。
性质3. 所有叶子都是黑色。(叶子是NIL结点)
性质4. 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
性质5. 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长
put操作
public V put(K key, V value) {
Entry<K, V> t = root;
if (t == null) {
// 如果根节点为空,然后这个比较其实是起一个类型检查作用,判斷key能否進行Comparable操作
compare(key, key); // type (and possibly null) check
// 创建root节点
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
// 如果根节点存在
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
// 判断是否设置了比较器
Comparator<? super K> cpr = comparator;
if (cpr != null) {
// 从根节点循环比对,直到相等
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0) {
// 比目标小,那么就遍历进入左节点
t = t.left;
} else if (cmp > 0) {
t = t.right;
} else {
// 如果存在相同key,直接设置值,并返回旧值,并结束后续操作,这里就不需要进行修复操作了
return t.setValue(value);
}
} while (t != null);
} else {
if (key == null) {
throw new NullPointerException();
}
@SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0) {
t = t.left;
} else if (cmp > 0) {
t = t.right;
} else {
return t.setValue(value);
}
} while (t != null);
}
// 如果最终找到叶子节点了,我们就得新增一个节点设置
Entry<K, V> e = new Entry<>(key, value, parent);
if (cmp < 0) {
parent.left = e;
} else {
parent.right = e;
}
// 红黑树再平衡***
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
红黑树再平衡
我们做如下规定
当前正在处理的节点为X,父节点P,爷爷节点G,叔叔节点Y,A3标识黑高位3的红黑树
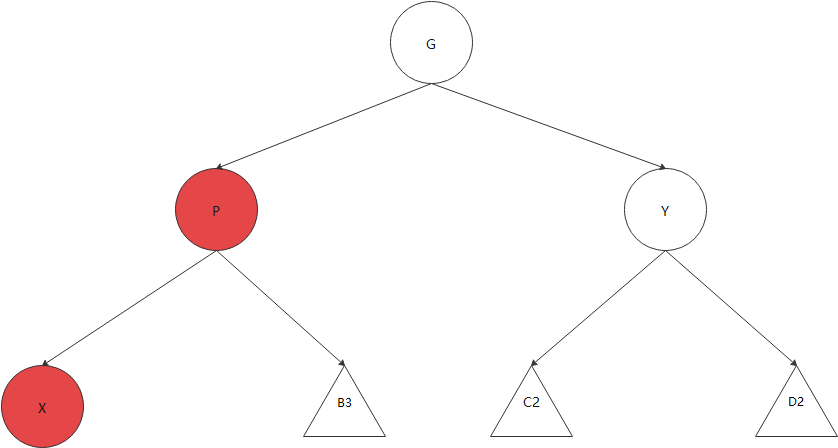
1.无需调整
2.仅仅需要考虑父节点为红色的情况
case1:Y为红色,X可左可右=》P,Y染黑,G染红,X回溯到G
case2:Y为黑色,X为右孩子=》右旋P,X指向P,转为case3
case3:Y为黑色,X为左孩子=》P染黑,G染红,右旋G
场景1:
1.父节点为红,父节点为左孩子,叔叔节点为红
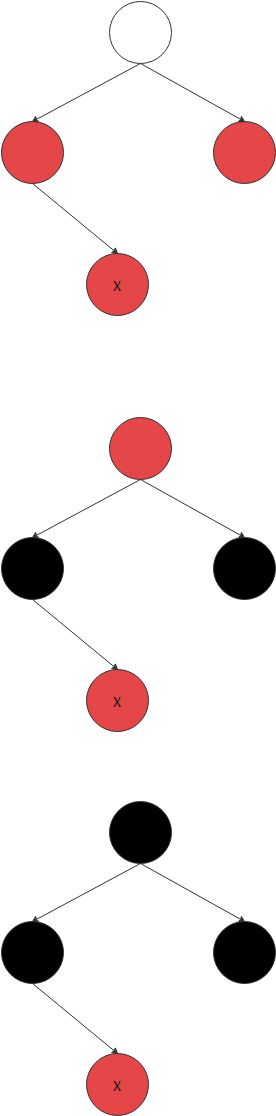
场景2:
- 父节点为红,并且父节点为左孩,叔叔节点为黑,当前节点为右孩子
场景3:
3.父节点为红,并且父节点为左孩,叔叔节点为黑,当前节点为左孩子
场景4
4.父节点为红,父节点为右孩子,叔叔节点为红
场景5:
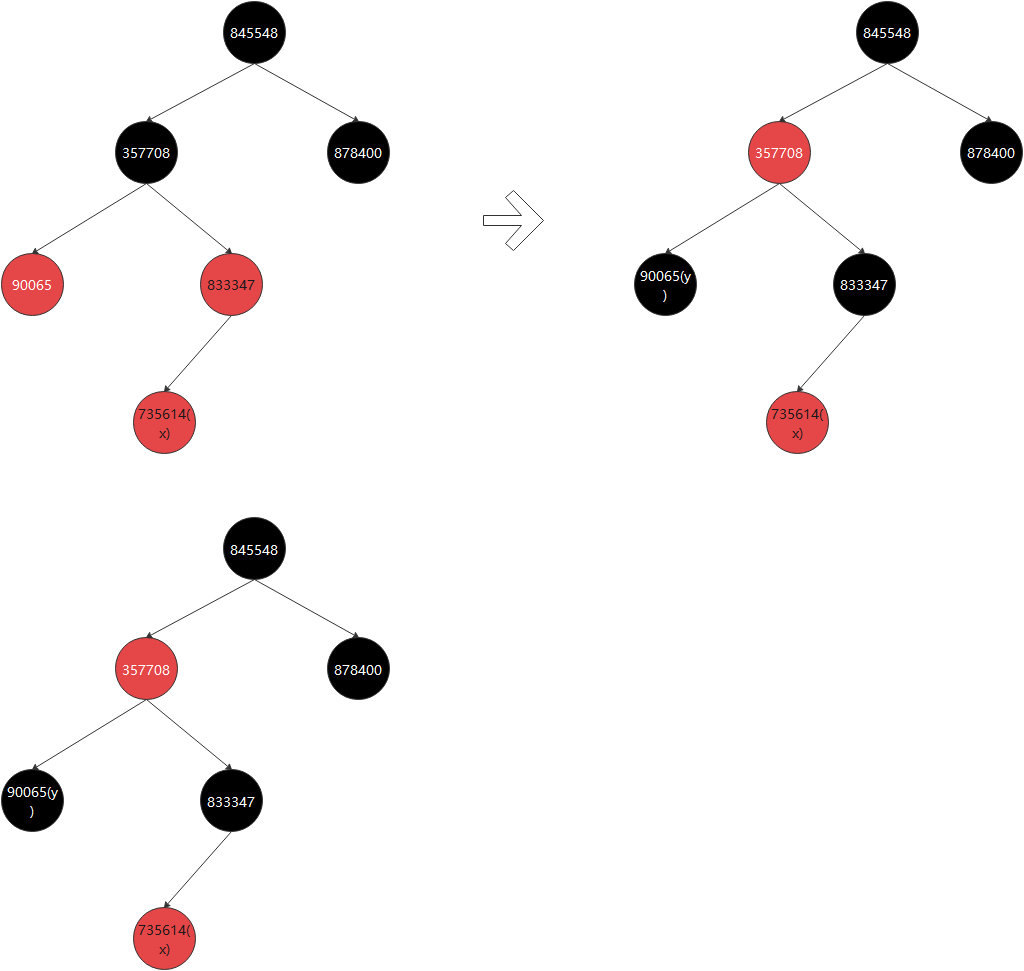
5.父节点为红,父节点为右孩子,叔叔节点为黑,当前节点为左孩子
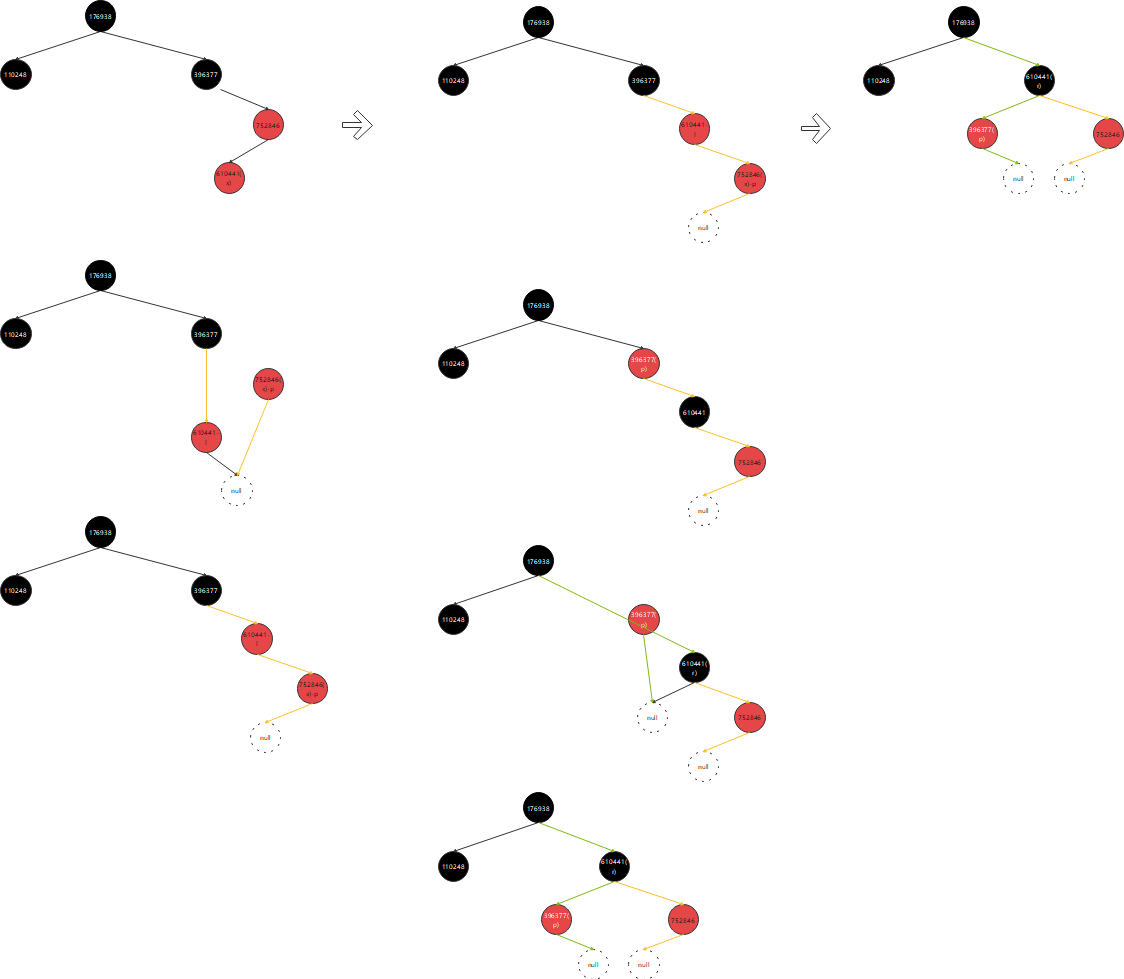
场景6:
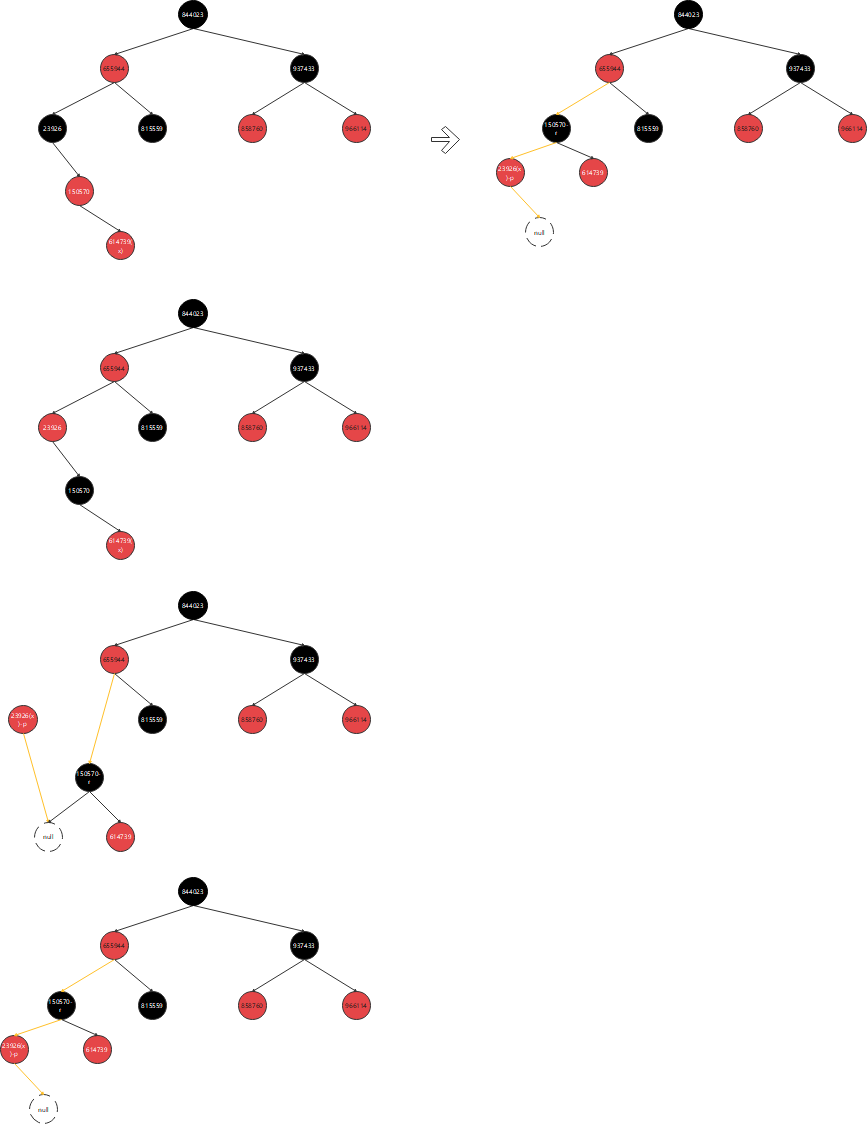
6.父节点为红,父节点为右孩子,叔叔节点为黑,当前节点为右孩子
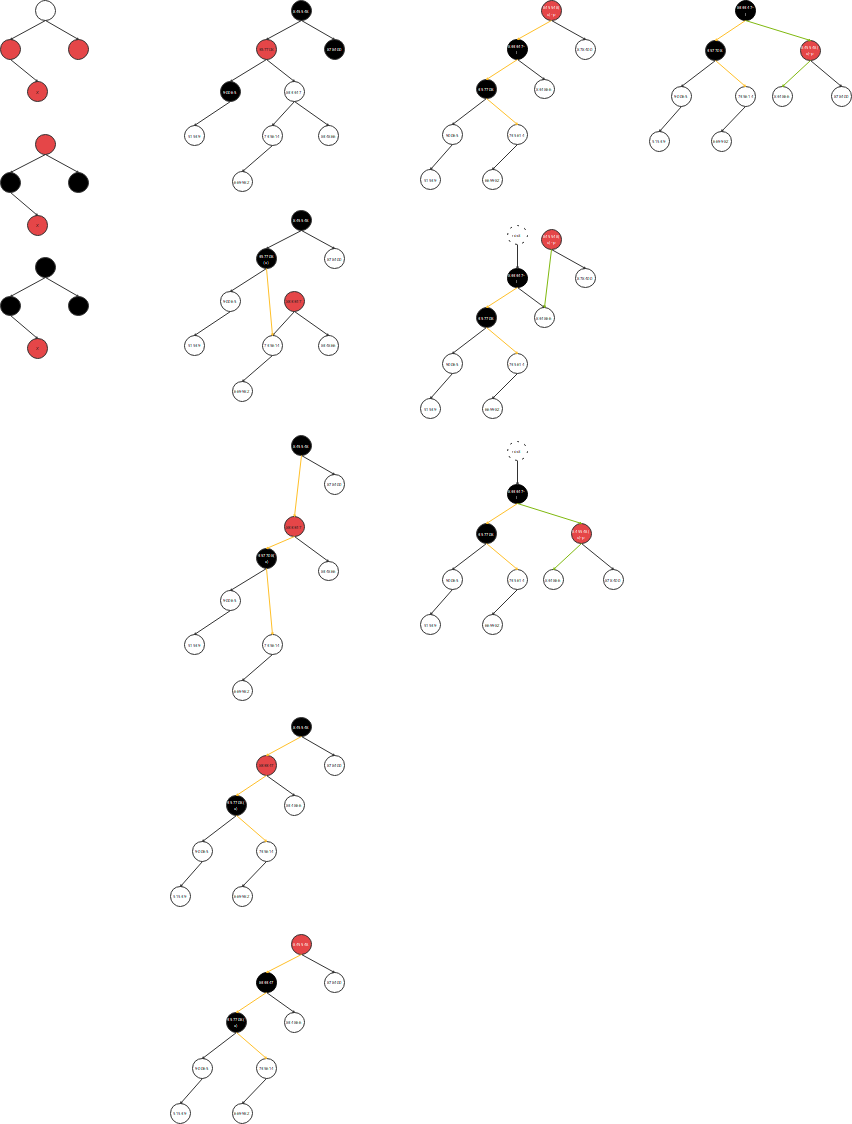
总结插入后:
1.父节点为红,父节点为左孩子,叔叔节点为红 --------------------------------------------------------- (只需要调整颜色)
2.父节点为红,父节点为左孩,叔叔节点为黑,当前节点为右孩子-------------------------- (需要左旋,然后右旋)
3.父节点为红,父节点为左孩,叔叔节点为黑,当前节点为左孩子-------------------------- (需要直接右旋)
4.父节点为红,父节点为右孩子,叔叔节点为红 --------------------------------------------------------- (只需要调整颜色)
5.父节点为红,父节点为右孩,叔叔节点为黑,当前节点为左孩子-------------------------- (需要右旋,然后左旋)
6.父节点为红,父节点为右孩,叔叔节点为黑,当前节点为右孩子-------------------------- (需要直接左旋)
package com.cutter.collection.study.m12;
import java.util.TreeMap;
/**
* 功能描述
*
* @since 2022-11-25
*/
public class Code009RedBlackTreeTest1 {
private static void test1() {
TreeMap treeMap = new TreeMap();
// 1. 父节点为左孩子
// 2. 叔叔节点为红
treeMap.put("5", "root-BLACK");
treeMap.put("2", "PARENT-RED");
treeMap.put("6", "UNCLE-RED");
treeMap.put("3", "SUB-RED");
}
private static void test2() {
TreeMap treeMap = new TreeMap();
// 1. 父节点为红,并且父节点为左孩子
// 2. 叔叔节点为黑
treeMap.put(357708, 357708);
treeMap.put(878400, 878400);
treeMap.put(845548, 845548);
treeMap.put(833347, 833347);
treeMap.put(90065, 90065);
treeMap.put(735614, 735614);
treeMap.put(51539, 51539);
treeMap.put(834866, 834866);
treeMap.put(669982, 669982);
}
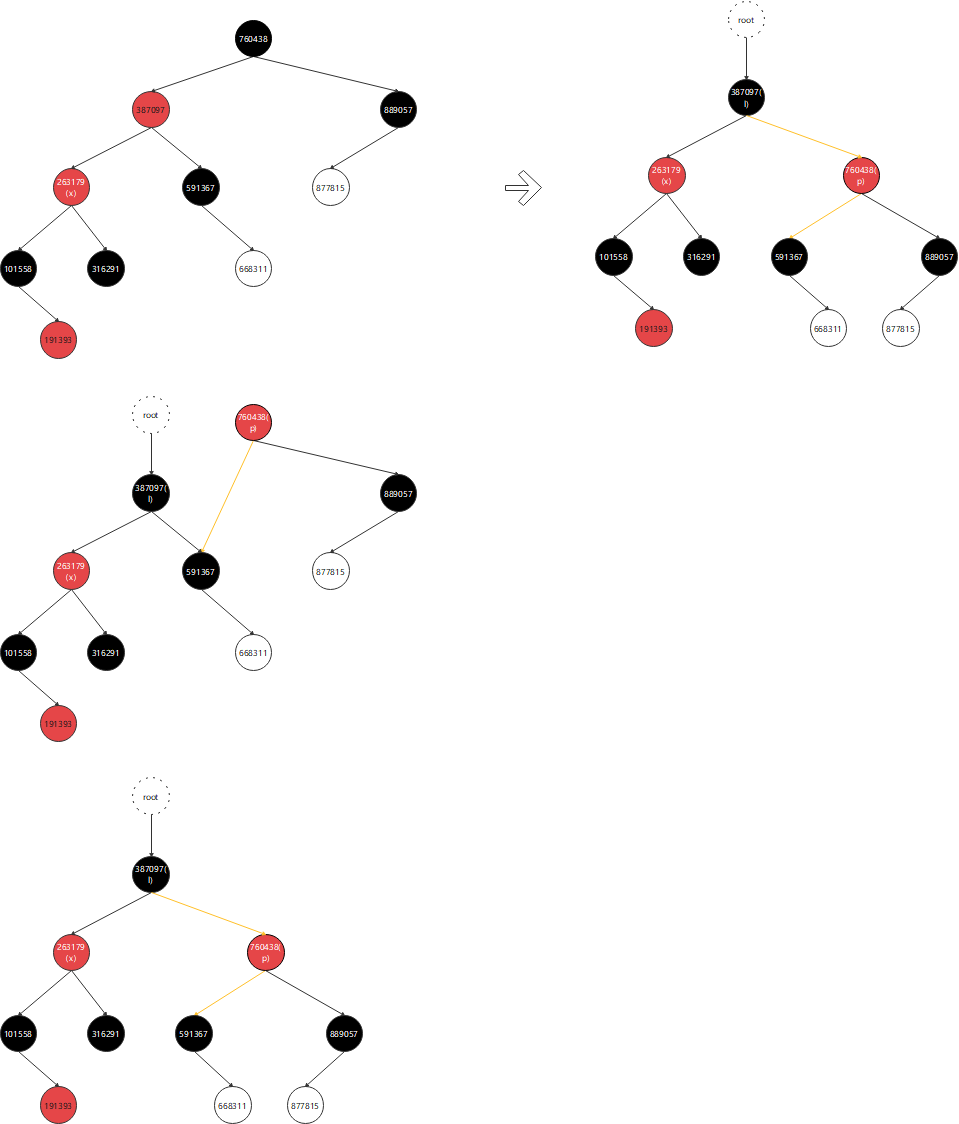
private static void test3() {
TreeMap treeMap = new TreeMap();
// 1. 父节点为红,并且父节点为左孩子
// 2. 叔叔节点为黑
// 3. X当前节点是左孩子
treeMap.put(889057, 889057);
treeMap.put(591367, 591367);
treeMap.put(760438, 760438);
treeMap.put(877815, 877815);
treeMap.put(316291, 316291);
treeMap.put(387097, 387097);
treeMap.put(101558, 101558);
treeMap.put(668311, 668311);
treeMap.put(263179, 263179);
treeMap.put(191393, 191393);
}
private static void test4() {
TreeMap treeMap = new TreeMap();
// 1. 父节点为红,父节点为右孩子,叔叔节点为红
treeMap.put(357708, 357708);
treeMap.put(878400, 878400);
treeMap.put(845548, 845548);
treeMap.put(833347, 833347);
treeMap.put(90065, 90065);
treeMap.put(735614, 735614);
}
private static void test5() {
TreeMap treeMap = new TreeMap();
// 1. 父节点为红,父节点为右孩子,叔叔节点为黑,当前节点为左孩子
treeMap.put(176938, 176938);
treeMap.put(396377, 396377);
treeMap.put(110248, 110248);
treeMap.put(752846, 752846);
treeMap.put(610441, 610441);
}
private static void test6() {
// 1. 父节点为红,父节点为右孩子,叔叔节点为黑,当前节点为右孩子
TreeMap treeMap = new TreeMap();
treeMap.put(937433, 937433);
treeMap.put(844023, 844023);
treeMap.put(655944, 655944);
treeMap.put(815559, 815559);
treeMap.put(966114, 966114);
treeMap.put(858760, 858760);
treeMap.put(23926, 23926);
treeMap.put(150570, 150570);
treeMap.put(614739, 614739);
}
}
private void fixAfterInsertion(Entry<K,V> x) {
// 设置当前节点为红
x.color = RED;
// 然后判断是进行左旋,右旋,还是其他操作,只要当前节点不为空,并且不是根节点,并且父节点为红,那么就考虑旋转操作
// 进行旋转操作的前提是对应节点的父节点是红色
// 这里是一个循环,然后下面x = parentOf(parentOf(x)); 这个算法是自低向上的
while (x != null && x != root && x.parent.color == RED) {
// 当父节点是祖父的左孩子
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
// 获取对应的叔叔节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
// 叔叔节点为红,当前处理节点可左可右
if (colorOf(y) == RED) {
// 场景1:父节点为红,父节点为左孩子,叔叔节点为红 --------------------------------------------------------- (只需要调整颜色)
// 父节点染黑
setColor(parentOf(x), BLACK);
// 叔叔节点染黑
setColor(y, BLACK);
// 祖父节点染红
setColor(parentOf(parentOf(x)), RED);
// x回溯到祖父
x = parentOf(parentOf(x));
} else {
// 叔叔节点为黑
// X是父节点的右孩子
// 场景2:父节点为红,父节点为左孩,叔叔节点为黑,当前节点为右孩子-------------------------- (需要左旋,然后右旋)
if (x == rightOf(parentOf(x))) {
// X指向父节点
x = parentOf(x);
// 左旋父节点
rotateLeft(x);
}
// 场景3:父节点为红,父节点为左孩,叔叔节点为黑,当前节点为左孩子-------------------------- (需要直接右旋)
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
// 右旋
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
// 场景4:父节点为红,父节点为右孩子,叔叔节点为红 --------------------------------------------------------- (只需要调整颜色)
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
// 场景5: 父节点为红,父节点为右孩,叔叔节点为黑,当前节点为左孩子-------------------------- (需要右旋,然后左旋)
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
// 场景6: 父节点为红,父节点为右孩,叔叔节点为黑,当前节点为右孩子-------------------------- (需要直接左旋)
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
// 根节点设置为黑
root.color = BLACK;
}
remove操作
参考:
https://www.cnblogs.com/cutter-point/p/11587453.html
参考
https://www.cnblogs.com/cutter-point/p/11587453.html
https://www.cnblogs.com/cutter-point/p/10976416.html
https://baike.baidu.com/item/红黑树/2413209
https://www.bilibili.com/video/BV1iJ411E7xW?p=125&vd_source=45cea88d5df1dd8adc80a4c6958ab8fd
WeakHashMap
- 强引用(Strong Reference),我们正常编码时默认的引用类型,强应用之所以为强,是因为如果一个对象到GC Roots强引用可到达,就可以阻止GC回收该对象
- 软引用(Soft Reference)阻止GC回收的能力相对弱一些,如果是软引用可以到达,那么这个对象会停留在内存更时间上长一些。当内存不足时垃圾回收器才会回收这些软引用可到达的对象
- 弱引用(WeakReference)无法阻止GC回收,如果一个对象时弱引用可到达,那么在下一个GC回收执行时,该对象就会被回收掉。
- 虚引用(Phantom Reference)十分脆弱,它的唯一作用就是当其指向的对象被回收之后,自己被加入到引用队列,用作记录该引用指向的对象已被销毁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号