【collection】4.java容器之LinkedList,Stack,CopyOnWriteArrayList
LinkedList
节点数据结构
/**
* 泛型结构
* @param <E> node
*/
private static class Node<E> {
E item;
// 双向链表,向前和向后
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
add
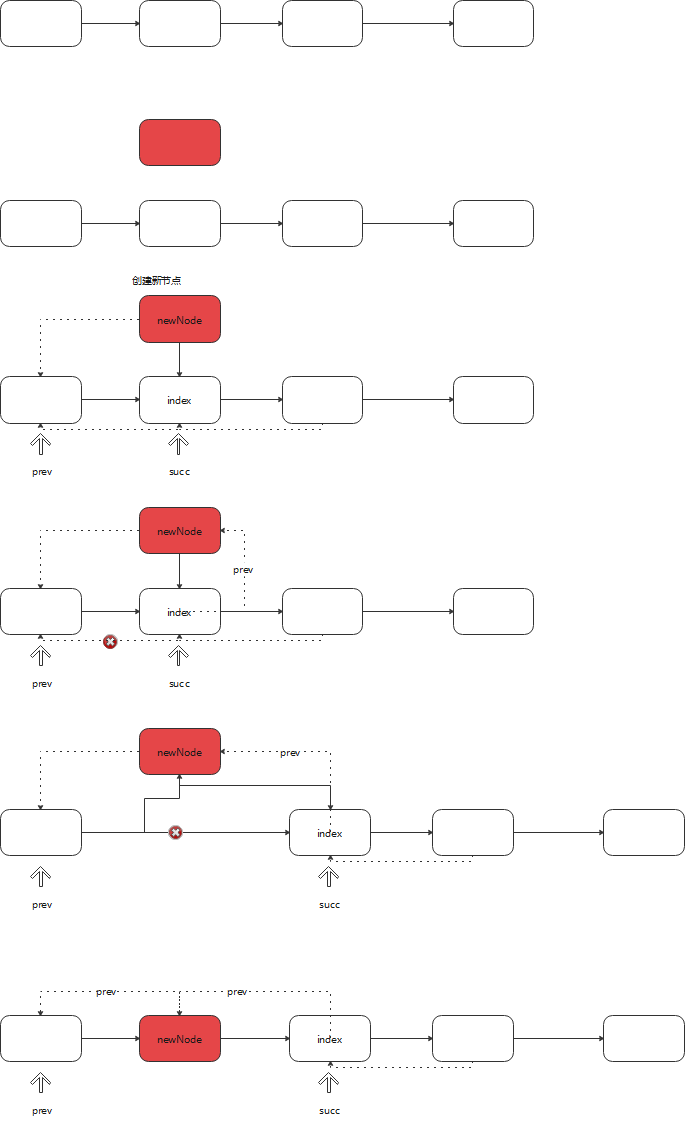
结论:新节点是插入到原来index的前面,原来index以及以后的节点,整体后移一位
/**
* Returns the (non-null) Node at the specified element index.
* 这里索引用了二分的思想,但是不是二分的算法
* 首先区分index是否小于一般,如果是,那么从前往后找
* 如果大于一般,那么从后往前找
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
// 从first往后
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 从last往前
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
// 断开原来的前置连接线,并修改为新的
succ.prev = newNode;
if (pred == null) {
first = newNode;
} else {
// 断开原来的后置,并更新
pred.next = newNode;
}
size++;
modCount++;
}
reomove,removeFirst,remove(index)
remove默认移除首节点,于removefirst作用相同
/**
* Unlinks non-null first node f.
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else {
// 更新完first之后,这里只需要把next.prev对象设置为null即可
next.prev = null;
}
size--;
modCount++;
return element;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 前置节点为空,那么直接把first移动到next
if (prev == null) {
first = next;
} else {
// 把前面节点的后置设置为下一个,跳过当前节点
prev.next = next;
x.prev = null;
}
// 如果next本来是空的,那么把last指针前移
if (next == null) {
last = prev;
} else {
// 不为空,那么把后面节点的前置指针跳过当前,设置前面一个节点
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove(index)和 remove(Object)类似
但是remove(object)的意思是判断空和非空,因为空的无法进行equals比较,循环查找
另外remove(index)也是先根据node方法定位关联节点
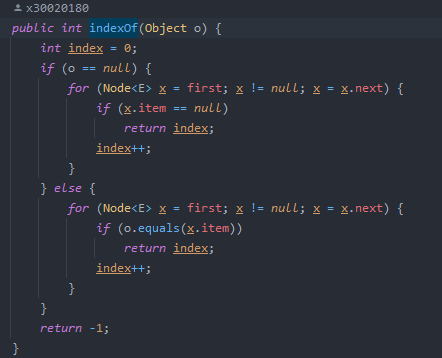
get,indexof查找
get方法也是用node(index)定位,indexof方法:判断空和非空,因为空的无法进行equals比较,循环查找
参考
https://pdai.tech/md/java/collection/java-collection-LinkedList.html#queue-方法
Stack
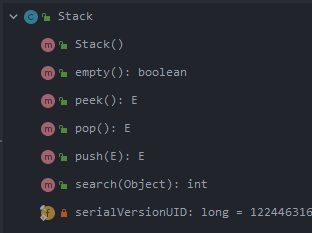
栈的实现主要依赖的是vector
这里主要是push和pop操作
扩容参考arraylist
push就是类似add,但是这里的操作都加了synchronized关键字,所以stack是线程安全的
CopyOnWriteArrayList
add操作
public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 先直接复制一个新的数组出来,并且直接把长度+1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 然后设置最后一个位置的节点
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
扩容
这个结构的扩容方式很简单暴力
直接复制出来一份满足要求大小的数组
newElements = Arrays.copyOf(elements, len + 1);
get
没有加锁
private E get(Object[] a, int index) {
return (E) a[index];
}
总结:
数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
这句话的意思是在循环操作的过程中,这个get结果是不可知的,只能保证在set的时候没问题,然后所有数据add完毕之后的结果符合预期
内存占用问题:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号