mysql调优(new)
mysql调优(new)
针对mysql5.7版本
目的:
针对业务,实际场景的问题来对mysql服务端进行优化。
解决实际中的各类问题。
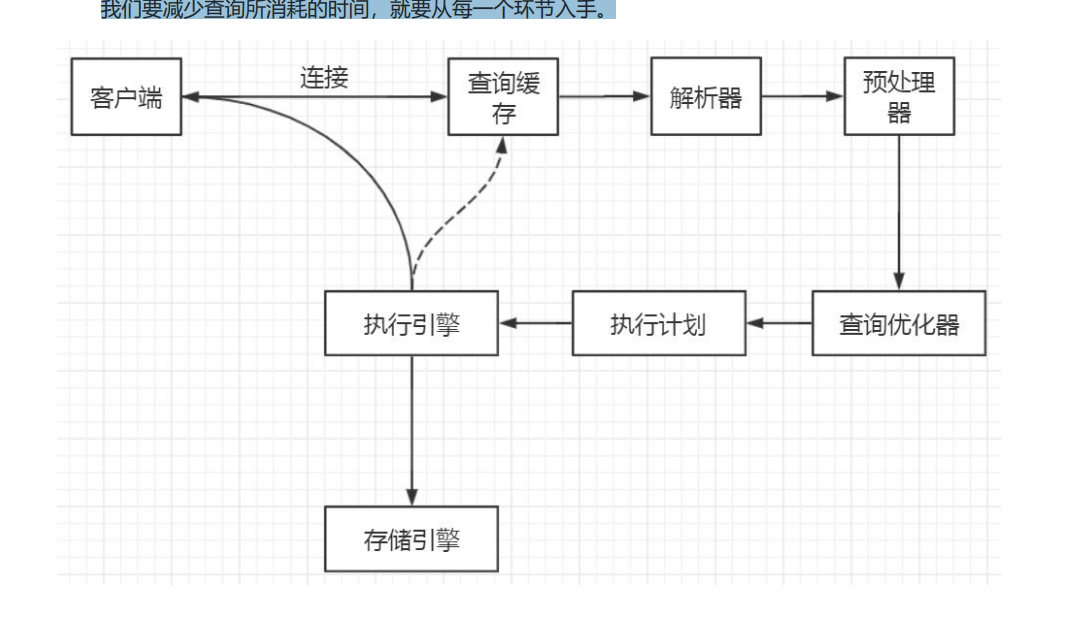
1.基础架构
总体架构
总体分为三层
连接,服务,存储引擎
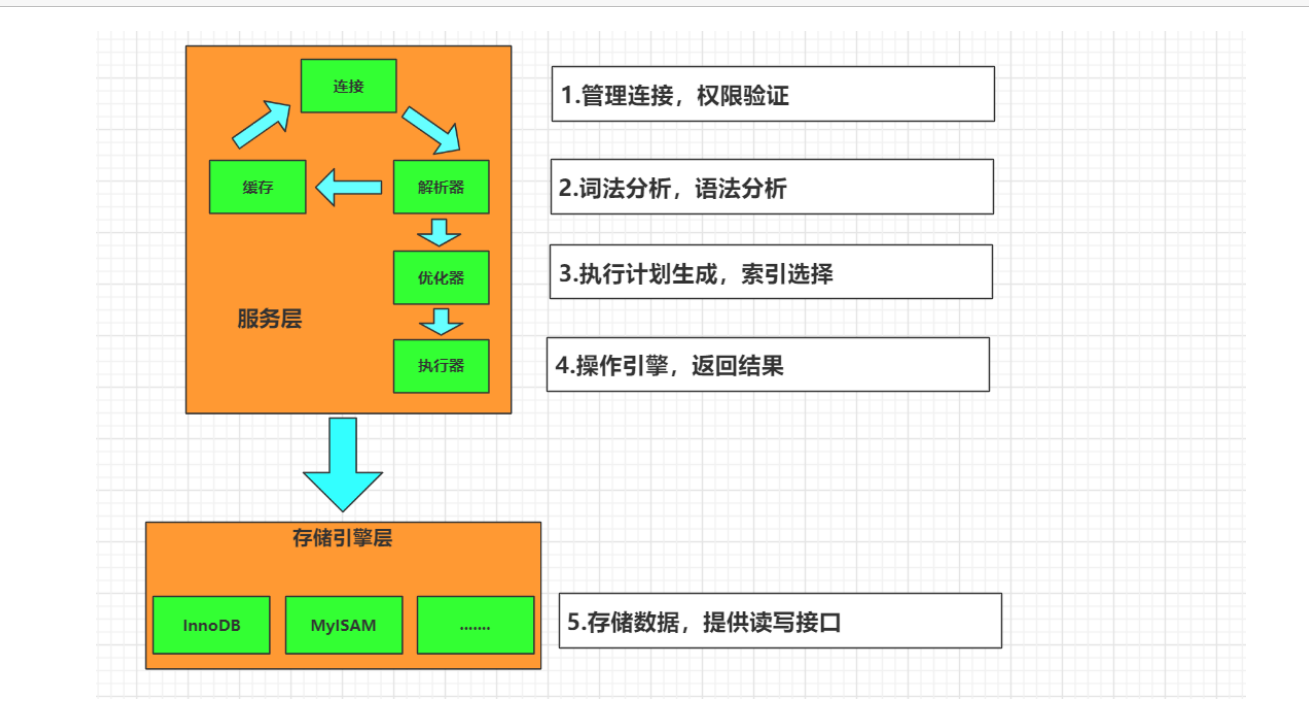
详细模块
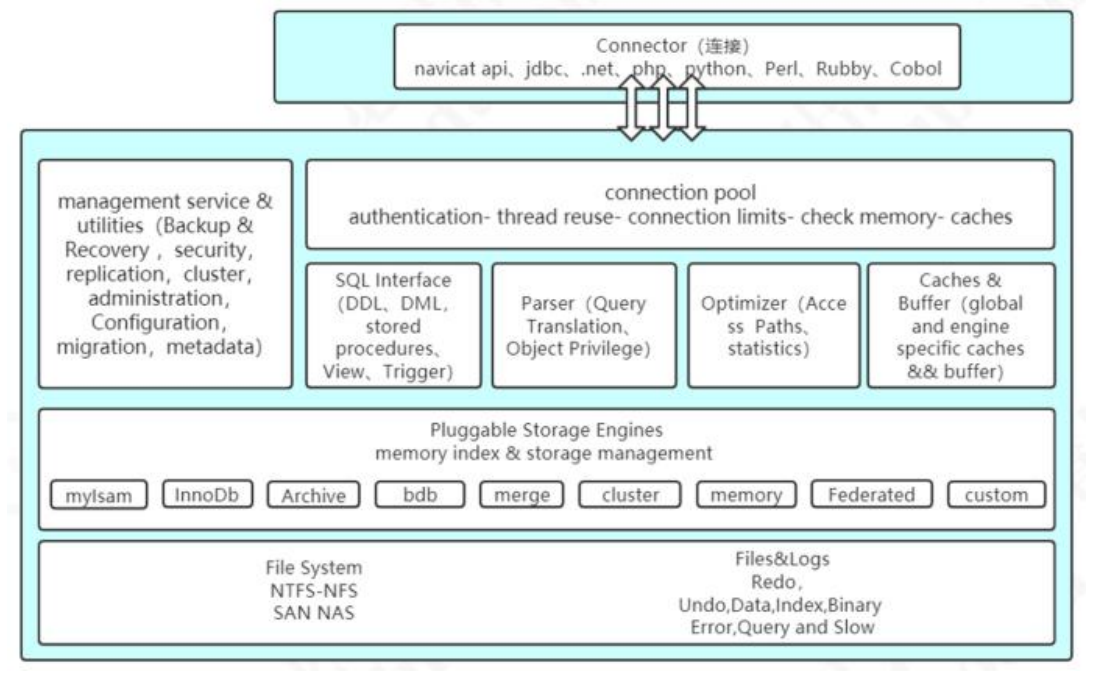
1.Connector:用来支持各种语言和 SQL 的交互,比如 PHP,Python,Java 的 JDBC
2.Management Serveices & Utilities:系统管理和控制工具,包括备份恢复、MySQL 复制、集群等等
3.Connection Pool:连接池,管理需要缓冲的资源,包括用户密码权限线程等等
4.SQL Interface:用来接收用户的 SQL 命令,返回用户需要的查询结果
5.Parser:用来解析 SQL 语句
6.Optimizer:查询优化器
7.Cache and Buffer:查询缓存,除了行记录的缓存之外,还有表缓存,Key 缓存,权限缓存等等。
8.Pluggable Storage Engines:插件式存储引擎,它提供 API 给服务层使用,跟具体的文件打交道。
2.一条查询sql的执行流程(详解)
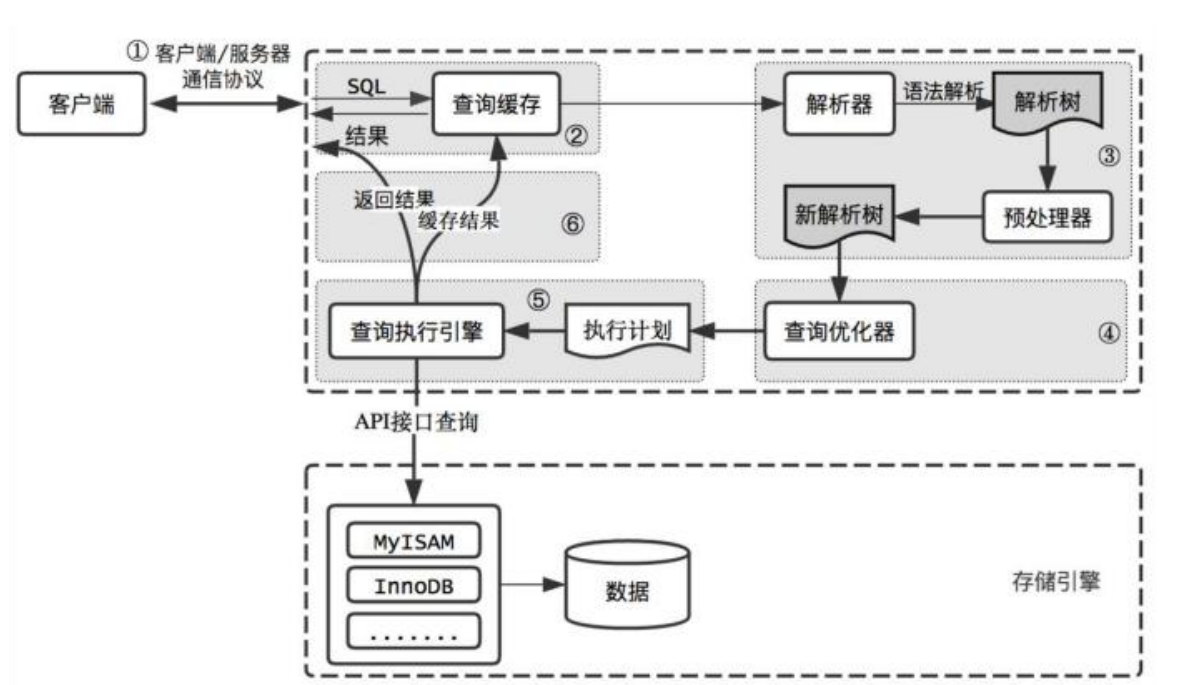
建立连接 查询缓存
1.建立连接
2.查询缓存
3.语法解析(解析器)
4.查询优化--》执行计划 索引选择 (优化器)
5.执行(执行器)
建立连接
首先运行mysql服务,监听端口3306(默认)
通信协议
MySQL 支持多种通信协议。
- TCP/IP协议,用的最多,我们java中的数据库驱动就是用的这个
- Unix Socket,要用到服务器上的一个物理文件(mysql.sock)。
- 另外还有命名管道(Named Pipes)和内存共享(Share Memory)的方式
通信方式
单工:数据单向传输
半双工:双向传输,但不能同时传输
全双工:双向传输,可以同时传输
mysql用的半双工。因此客户端和服务端不能同时发送数据。
所以客户端发送 SQL 语句给服务端的时候,(在一次连接里面)数据是不能分成小块发送的,不管
你的 SQL 语句有多大,都是一次性发送。
如果发送给服务器的数据包过大,我们必须要调整 MySQL 服务器配置 max_allowed_packet 参数的值
(默认是 4M)。
show variables like 'max_allowed_packet';
对于服务端返回数据也是,数据包别太大,能分页就分页。
连接方式
MySQL 既支持短连接,也支持长连接。短连接就是操作完毕以后,马上 close 掉。长连接可以保持 打开,后面的程序访问的时候还可以使用这个连接。
长时间不活动的连接,MySQL 服务器会断开
#默认都是28800s 8小时
show global variables like 'wait_timeout'; (非交互式超时时间,如 JDBC 程序)
show global variables like 'interactive_timeout'; (交互式超时时间,如数据库工具)MySQL 默认的最大连接数是 151 个(5.7 版本),最大是 16384(2^14)。
#最大连接数
show variables like 'max_connections';
#查看 3306 端口当前连接数
netstat -an|grep 3306|wc -l;
查询缓存
MySQL 内部自带了一个缓存模块。默认是关闭的。主要是因为 MySQL 自带的缓存的应用场景有 限,第一个是它要求 SQL 语句必须一模一样。第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效。
在 MySQL 5.8 中,查询缓存已经被移除了。 ==》用的场景少 还难维护
语法解析(解析器)
是对 SQL 语句进行词法和语法分析和语义的解析。
检查sql是否合法,如果不合法的话,,会在预处理器处理时报错。
查询优化(优化器)
优化器开展工作。
根据sql的解析结果生成不同的执行计划,选择最优的一条来执行。
MySQL 里 面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种。
优化器常见的优化处理
- 是否使用索引
- 查询数据,是不是能直接从索引里面取到值。
- count()、min()、max(),比如是不是能从索引里面直接取到值。
- ……
优化器最终会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。
当然,这个执行计划是不是一定是最优的执行计划呢?不一定,因为 MySQL 也有可能覆盖不到所有的执行计划。
我们可以通过explain关键字来查询sql的执行计划
EXPLAIN select name from user where id=1;存储引擎
基本介绍
我们的数据是放在哪里的?执行计划在哪里执行?是谁去执行?
插件式的存储引擎,根据业务可以对不同表使用不同的存储引擎。
不同的存储引擎通过提供不同的存储机制、索引方式、锁定水平等功能,来满足我们的业务需求。
#查看库里所有表的存储引擎
show table status from `ihrm`;
#查看表的存储引擎
show table status like 'bs_city'
各种存储引擎
官网:https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
可以查一下
SHOW ENGINES ;常用的有InnoDB MyISAM
MyISAM和InnoDB区别
MyISAM: 5.5之前默认存储引擎
3个文件存数据,
适用于以读为主的表。
存储了表的行数(count 速度更快)。
支持表锁(更新时其他线程不能读写表,查询时其他线程不能写),不支持行锁
不支持事务
innodb: 5.5之后默认存储引擎(包括5.5)
2个文件存数据
支持事务,外键
支持表锁,行锁(默认行锁)
安全性比较高
其他存储引擎,不怎么用
Memory CSV Archive
Memory (1个文件)
所有数据都保存在内存,适合做临时表,读写快
默认使用哈希索引
3.一条更新的sql执行流程
大致过程和查询差不多,解析器-》优化器-》执行器
区别就在于拿到符合条件的数据之后的操作。
InnoDB 里面有个内存的缓冲池(buffer pool)。
更新时不会直接写到磁盘(IO代价大),而是先写入到这个缓冲的内存中,innodb有专门的线程来将buffer pool的数据写入到磁盘。内存的数据页和磁盘数据不一致的 时候,我们把它叫做脏页。
(每隔一段时间一次性把多个修改写到磁盘。--》刷脏)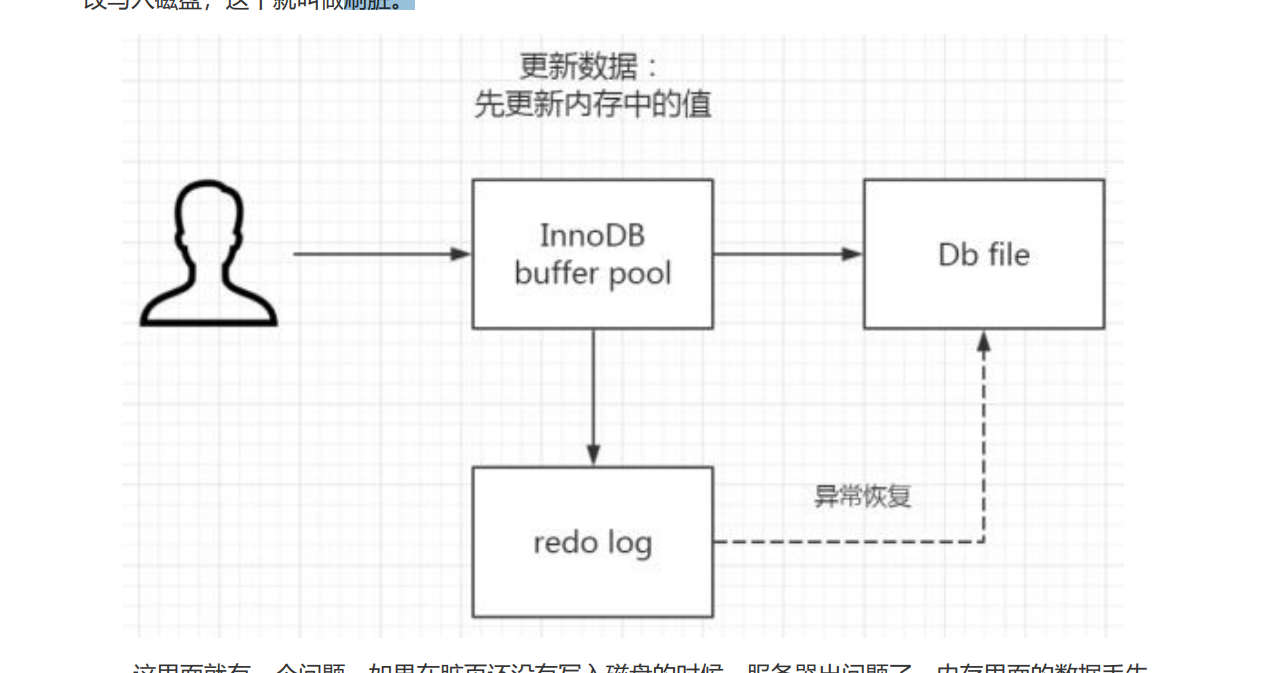
这里就会有问题:内存数据没有同步到磁盘,mysql服务就挂了咋办?--》持久化机制
持久化机制通过日志文件来实现:redo log,bin log
redo log
记录更新后的值。 日志文件
特点:
记录修改后的值(事务的持久性就是通过redo实现)
文件大小是固定的,前面的内容会被覆盖,所以不能用于回滚。
innodb存储引擎实现的,并不是所有存储引擎都有。
bin log
相当于全量日志,记录所有更新操作
MySQL Server 层也有一个日志文件,叫做 binlog,它可以被所有的存储引擎使用。
binlog 以事件的形式记录了所有的 DDL 和 DML 语句(因为它记录的是操作而不是数据值,属于逻 辑日志),可以用来做主从复制和数据恢复。
文件内容可以追加,没有固定大小限制
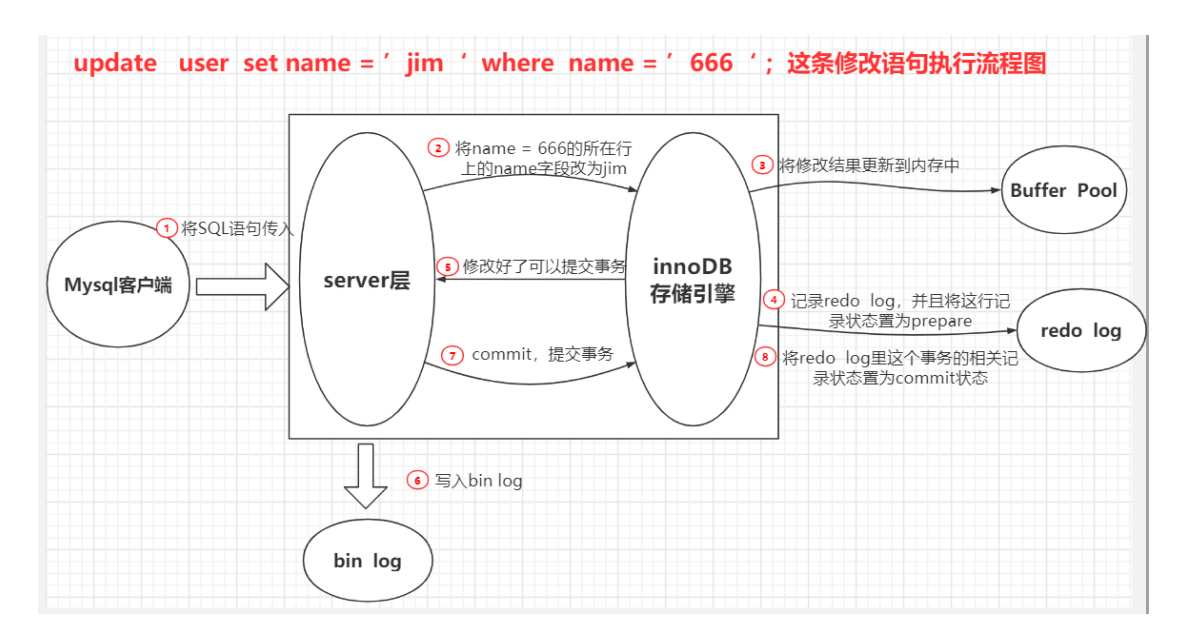
update -- >redolog--> binlog
4.mysql索引原理
索引介绍
就是一种数据结构,用于快速检索。(目录)
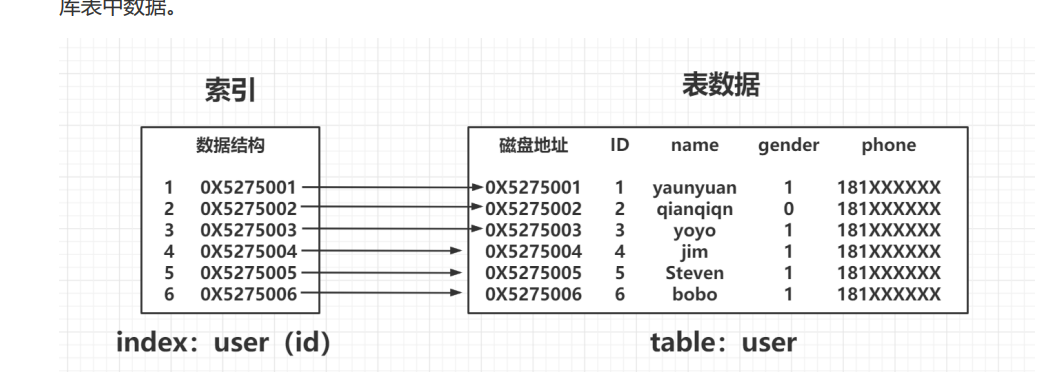
索引类型
innoDb/MyISAM存储引擎有4种类型:
normal:普通索引
unique:唯一索引,值唯一但是可以允许一条数据为null (主键索引是特殊的唯一索引 值不能为null)
fullText:全文索引,针对比较大的数据创建,防止like效率慢的问题(只支持字段为文本类型:比如char、varchar、text)
spatial:空间索引(用得少)
索引的数据结构
索引结构发展演变:
二叉树 (Binary Search Tree):
取决于tree的深度,最坏的情况和全表扫描没区别……(斜树)
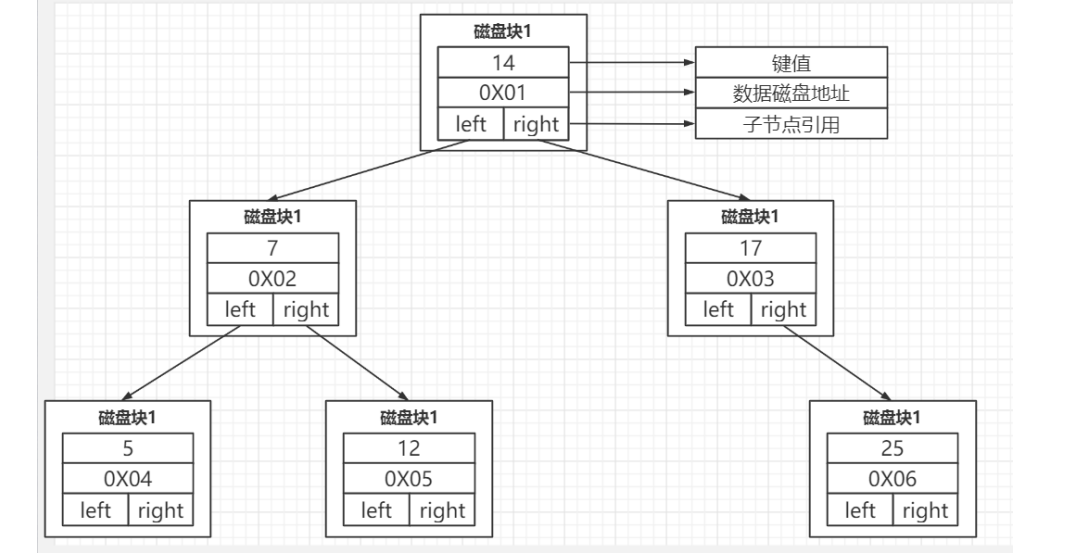
平衡二叉树(AVL Tree):
插入数据时会自动计算调整,保证平衡
每个节点存单个东西:索引的键值,自己的地址,左右指定节点的地址
问题:
-
数据量大的话还是比较深,需要多次磁盘IO。--- 还是慢
-
InnoDB 操作磁盘的最小的单位是一页(或者叫一个磁 盘块),大小是 16K(16384 字节)。意思就是你1个节点数据存的东西太少的话,还是一个节点就要一次IO --- 》 浪费IO的空间(理论来讲一个节点能把16k存完最好)
#查询表对应 索引和数据的空间大小 select CONCAT(ROUND(SUM(DATA_LENGTH/1024/1024),2),'MB') AS data_len, CONCAT(ROUND(SUM(INDEX_LENGTH/1024/1024),2),'MB') as index_len from information_schema.TABLES where table_schema='test' and table_name='t_user';
**Btree:多路平衡查找树(分裂、合并)
也存三个东西:索引键值),自己的地址,指向的节点地址,数据
- 索引值就是具体的数据:主键索引保存数据,非主键索引保存主键值
和AVL不一样的是,指向的节点地址永远比关键字数多 1,如下:
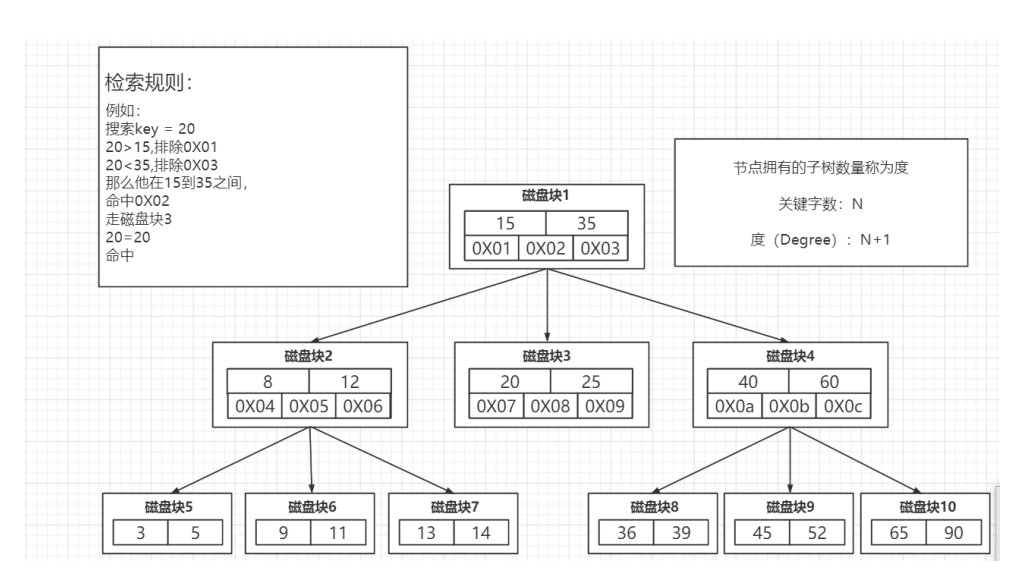
每个节点存更多的索引数据。
相对于AVL解决的问题:数据存储的多,分叉多
高瘦--》矮胖
B+树(加强版多路平衡查找树)
改良版的BTREE,解决的问题比BTREE更全面
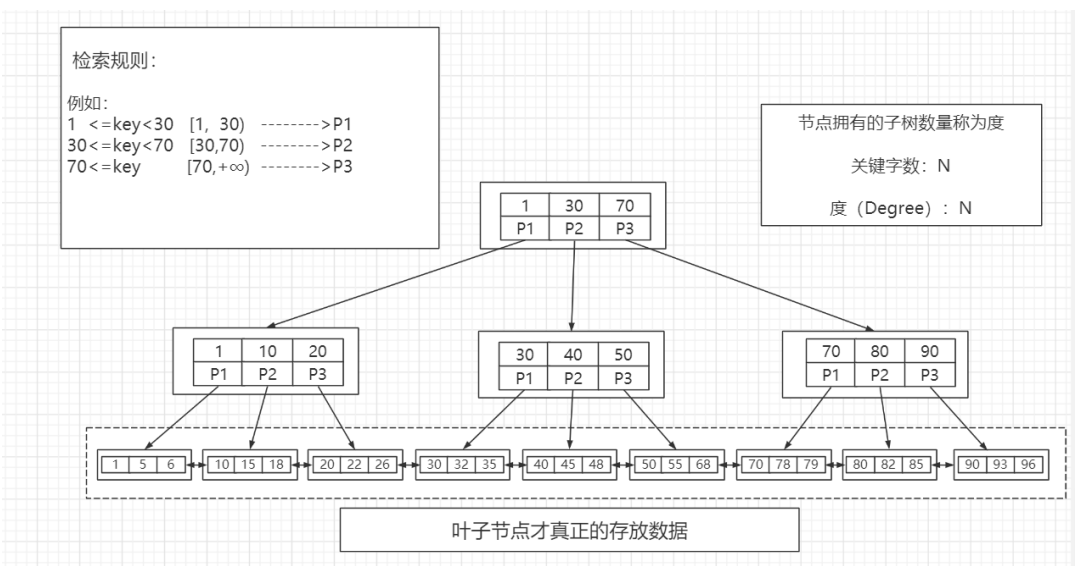
特点:
关键字的数量是跟路数相等的;
只有叶子节点才存数据。所以匹配到关键字不会直接返回,还会往下搜索,一直到叶子节点。
B+Tree 的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个 叶子节点的第一个数据,形成了一个有序链表的结构。
优势:
每个节点能存储更多索引值(因为数据都在叶子节点了)
-
数据多的话,一次磁盘IO能够加载的索引关键字更多
-
分叉更多 ----》更矮更胖
效率稳定:因为都要到叶子节点拿数据,所以io次数比较稳定
排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
mysql使用的索引结构
一般有两种:常用的是B+Tree(innodb 和 myisam)
哈希索引
还有一种是hash索引,特点如下:

查询速度快,通过hashcode直接匹配。
只能进行等值匹配,不能范围查询和模糊查询
数据量大或者字段值重复多的话,会造成hash冲突,(采用拉链法解决),效率会降低。
memory存储引擎支持哈希索引
B+Tree落地
不同存储引擎存储的文件也不一样
show VARIABLES LIKE 'datadir'; #查询相关数据文件存储的位置innodb:2个文件frm(表结构) ibd(数据+索引)
myisam: 3个文件 frm (表结构) MYD (数据) MYI(索引)
MYISAM的B+TRee索引:
MyISAM 的 B+Tree 里面,叶子节点存储的是数据文件对应的磁盘地址。
分了两个文件分别存索引和数据
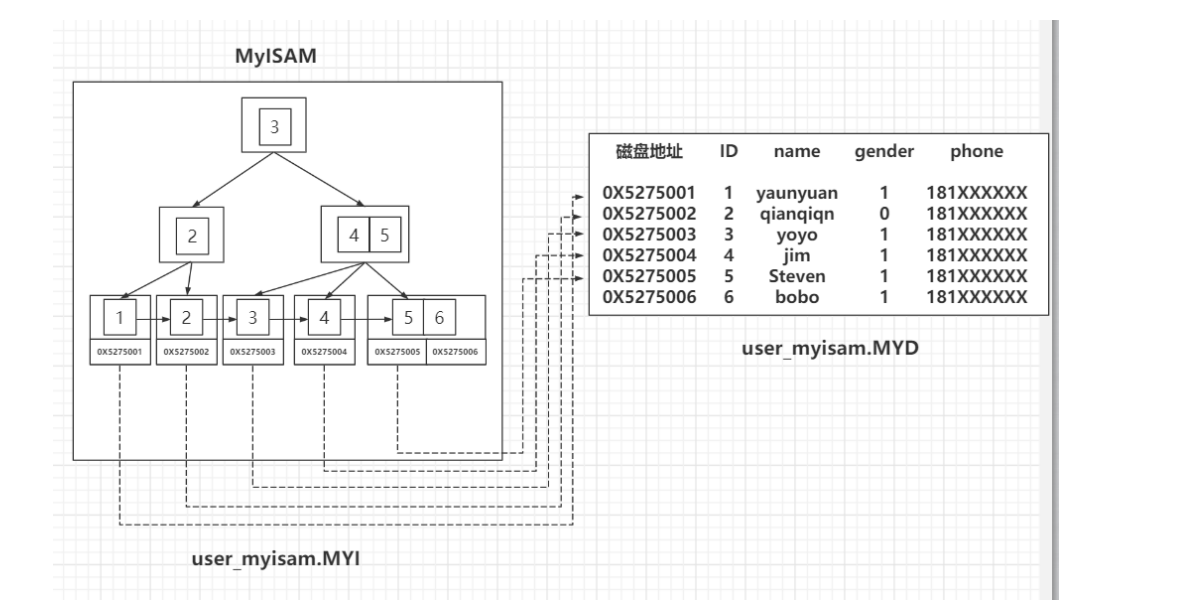
innodb的B+TRee索引:
innodb索引和数据存在同一个文件中,数据在b+tree的叶子节点上存储。
是这里会有一个问题,一张 InnoDB 的表可能有很多个多索引,数据肯定是只有一份的,那数据 在哪个索引的叶子节点上呢?。。
这里涉及到聚集索引的概念。
聚集索引不是索引的类型,而是数据存储的一种方式
就是索引键值的逻辑顺序跟表数据行的物理存储顺序是一致的。(比如字典的目录是按拼音排序 的,内容也是按拼音排序的,按拼音排序的这种目录就叫聚集索引)。--- 比如数据的内容按照主键排序。
innodb就是使用聚集索引的树结构来存储数据的。(一般以主键索引作为聚集索引,数据存储在主键索引树上的叶子结点上,决定数据行的物理存储顺序。)
问题又来了?数据都存在聚集索引的叶子节点上,那非聚集索引怎么拿到完整的数据? --- 回表
非聚集索引的叶子节点数据存的是聚集索引的key,拿到key之后再回表,去聚集索引树上的叶子节点拿到完整数据。(回表能避免就避免,加快效率)
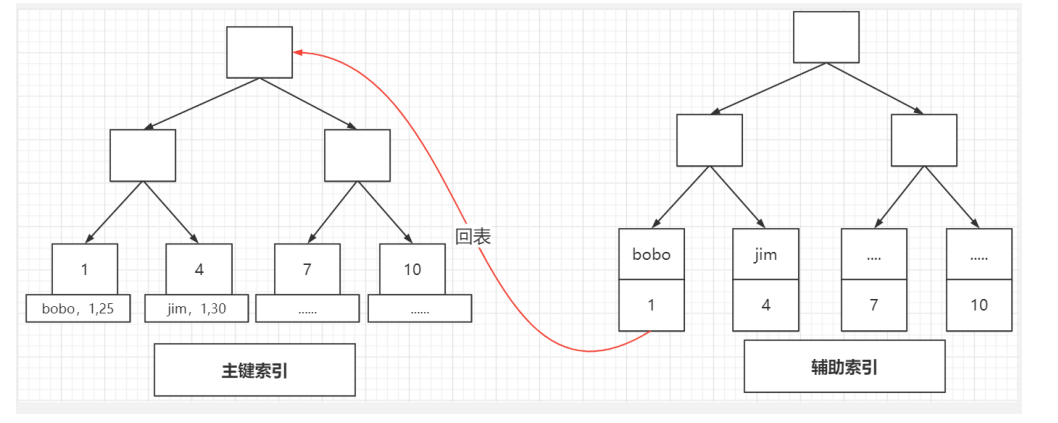
我们一般用什么来作为聚集索引:
-
主键
-
没有主键的话,不包含有 NULL 值的唯一索引作
-
都没有的话,则 InnoDB 会选择内置 6 字节长的 ROWID 作为隐藏的聚集索引, 它会随着行记录的写入而主键递增。
select _rowid name from t_user1;
5. 索引使用原则
索引并不是越多越好,更新数据时需要重新维护
不建议在离散度低的字段建索引
离散度=count(distinct(column_name)) : count(*)---》重复值越多,离散度就越低,太低的话导致扫描行数过多
联合索引最左匹配:
- 针对多个字段可以建立联合索引 ,单列索引是特殊的联合索引
- 查询sql匹配的字段也要根据索引的联合索引的顺序一样,否则不会走索引。(建立联合索引一定要把常用的字段放到最左边),如果多个字段都匹配到了联合索引的话,效率会比单列索引高
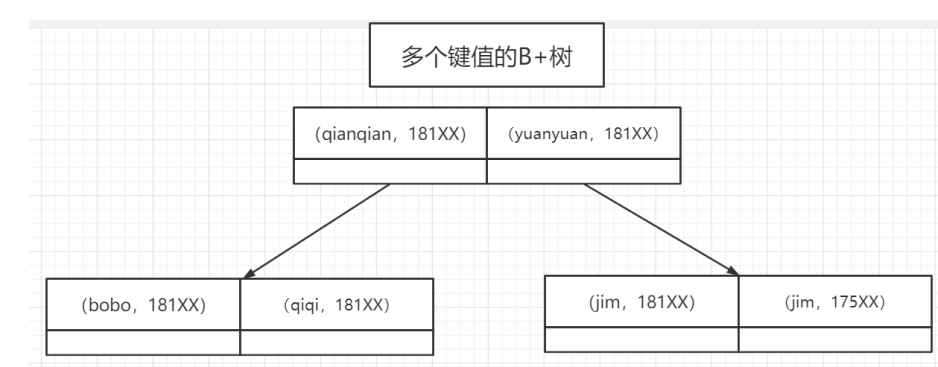
覆盖索引: 如果是非主键索引的情况下,是需要回表获取数据的
- select的数据可以直接从索引中获得,不需要回表,这时候使用的索引就叫做覆盖索引,
- 能使用就使用,大大提高了检索效率(减少了IO次数)
什么字段上创建索引?
用于 where 判断 order 排序和 join 的(on)字段上创建索引
频繁更新的值,别建索引
什么情况索引会失效
- 用不用索引,最终都是优化器说了算。基于开销的原则,开销怎么小怎么来
索引列上使用函数,表达式……
explain SELECT * FROM `t2` where id+1 = 4;
字符串不加引号,出现隐式转换
explain SELECT * FROM `user_innodb` where name = '136';
like 条件中前面带%
负向查询可能不走索引:(看开销 有时候全表反而更快 取决于优化器) --注意跟数据库版本、数据量、数据选择度都有关系。
not in ,!= ,not like
6.mysql优化思路和工具
mysql调优的最终目的:
- 目的:提高系统吞吐量,减少响应时间(压榨资源)
我们说到性能调优,大部分时候想要实现的目标是让我们的查询更快。一个查询的动作又是由很多 个环节组成的,每个环节都会消耗时间,我们在第一节课讲 SQL 语句的执行流程的时候已经分析过了。 我们要减少查询所消耗的时间,就要从每一个环节入手。
连接--配置优化
服务端:
设置合适的可用连接数
及时释放不活动的连接
-- 修改最大连接数,当有多个应用连接的时候
show variables like 'max_connections';
--及时释放不活动的连接,注意不要释放连接池还在使用的连接
-- 交互式和非交互式的客户端的默认超时时间都是 28800秒,8 小时,我们可以把这个值调小。
show global variables like 'wait_timeout';
客户端
使用连接池,复用连接,避免每次执行sql都要新建连接,用完又销毁
具体怎么配置,还是要压测来确定。 不同的硬件条件可以要针对不同的配置
架构优化
缓存
缓存减轻数据库压力
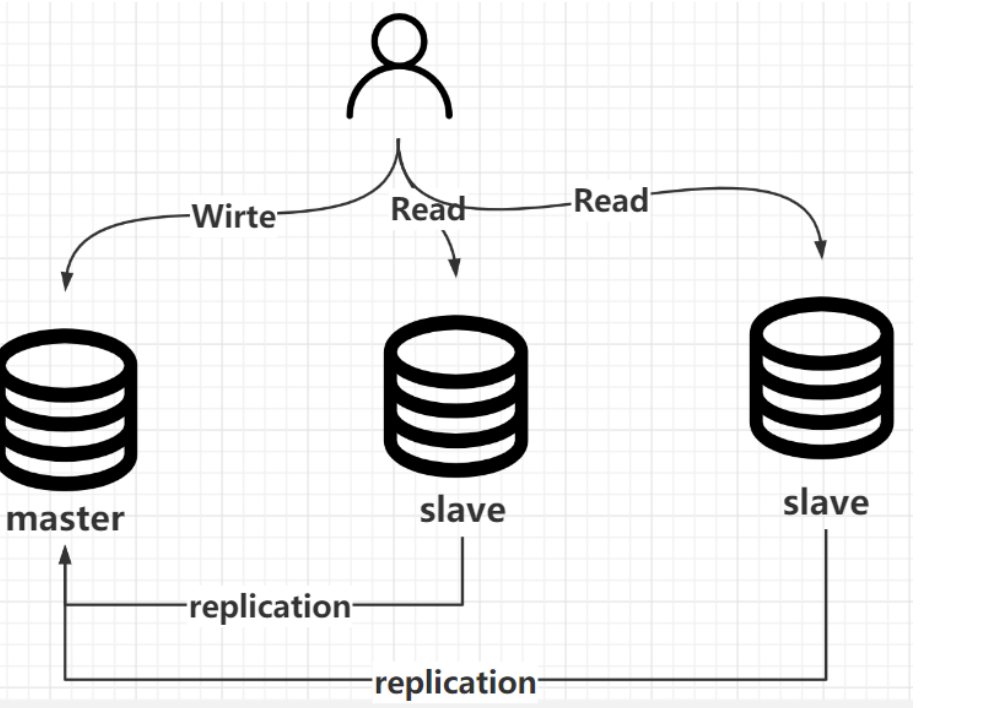
集群(主从复制)
加机器,分担压力
主从复制: master slave (读写分离哦,主写从读)
主从复制如何实现,怎么解决数据同步的问题的?
binlog
有了这个 binlog,从服务器会获取主服务器的 binlog 文件,然后解析里面的 SQL 语句,在从服务
器上面执行一遍,保持主从的数据一致。
这里面涉及到三个线程,连接到 master 获取 binlog,并且解析 binlog 写入中继日志,这个线程叫
做 I/O 线程。
Master 节点上有一个 log dump 线程,是用来发送 binlog 给 slave 的。
从库的 SQL 线程,是用来读取 relay log,把数据写入到数据库的。
这个是主从复制涉及到的三个线程。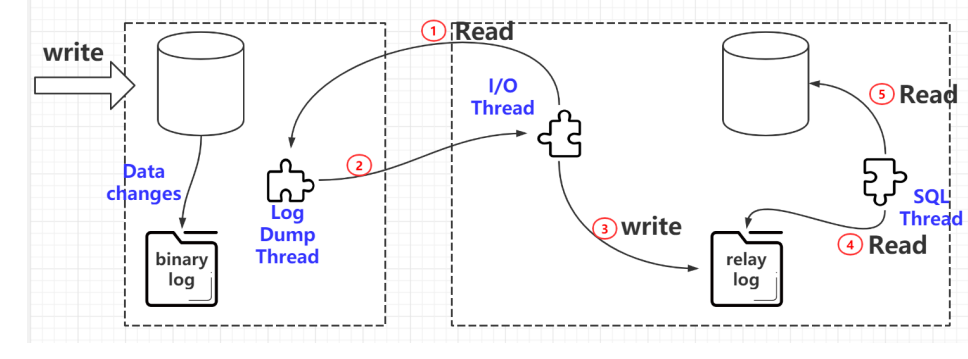
分库分表
我们在做了主从复制之后,如果单个 master 节点或者单张表存储的数据过大的时候,比如一张表 有上亿的数据,单表的查询性能还是会下降,我们要进一步对单台数据库节点的数据进行拆分,这个就 是分库分表。
优化器(执行计划)
优化器就是对我们的 SQL 语句进行分析,生成执行计划。
问题:在我们做项目的时候,有时会收到 DBA 的邮件,里面列出了我们项目上几个耗时比较长的查 询语句,让我们去优化,这些语句是从哪里来的呢? 我们的服务层每天执行了这么多 SQL 语句,它怎么知道哪些 SQL 语句比较慢呢? 第一步,我们要把 SQL 执行情况记录下来。
慢查询日志 slow query log
# 慢查询日志默认关闭 开启是有代价的(会影响性能)
show variables like 'slow_query%';
# 超过多长时间的 SQL 才记录到慢日志,默认是 10 秒
show variables like 'long_query%';
# 可以动态修改(重启失效)
set @@global.slow_query_log=1; -- 1 开启,0 关闭,重启后失效
set @@global.long_query_time=3; -- mysql 默认的慢查询时间是 10 秒,另开一个窗口后才会查
到最新值
#也可以配置文件my.cnf修改,持久
slow_query_log = ON
long_query_time=2
slow_query_log_file =/var/lib/mysql/localhost-slow.log
#模拟慢查询
select sleep(10);
#查看有多少慢查询
show global status like 'slow_queries';
#获取慢查询日志文件位置 查看内容
show variables like 'slow_query%';
#日志内容多的话 难以分析 可以使用工具来分析---MySQL 提供了mysqldumpslow的工具,在MySQL 的bin目录下。
#查询用时最多的 10 条慢 SQL:
./mysqldumpslow -s t -t 10 -g 'select' /usr/local/mysql/data/iZwz984mbcsaw0ihvbfzfpZ-slow.logshow profile
可以查看SQL 语句执行的 时候使用的资源,比如 CPU、IO 时间的消耗情况。
#开启
select @@profiling;
set @@profiling=1;
#查询profile用法
help profile;
#所有sql执行时间
show profiles;
#查询某条sql的各个过程消耗的时间 1代表queryId
show profile for query 1;
#某条sql的各个过程cpu消耗
SHOW PROFILE CPU FOR QUERY 2;
其他系统命令
#show processlist; 查询连接线程状态 可以拿到id kill掉异常线程
show processlist;
select * from information_schema.processlist; #查表效果同上
#show status 查看服务器运行状态
SHOW GLOBAL STATUS LIKE 'com_select'; -- 查看 select 次数
#show engine 存储引擎运行信息
#show engine 用来显示存储引擎的当前运行信息,包括事务持有的表锁、行锁信息;事务的锁等待
#情况;线程信号量等待;文件 IO 请求;buffer pool 统计信息。
show engine innodb status;explain
上面的工具都是定位问题
定位到问题后使用explain来分析sql
来进行优化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义