数据结构
Introduction
Analyzing Algorithms
-
插入排序:与左边的元素进行比较。
-
RAM Model
- 原子操作
- 常数时间操作
- 顺序执行
- \(t_j\) :while 循环的次数
Asymptotic Notation Divide-and-Conquer
-
渐进记号
- \(\Theta\)
- \(O=\leq\)
- \(\Omega=\geq\)
-
具体复杂度和抽象复杂度
- concrete:use RAM model,including a lot of 细节。
- abstract:use 渐进记号 analyze.
Solving Recurrences – 1
-
递归式的定义:描述具有递归调用的算法运行时间,通过小的输入上的已知的函数值来describe a function.
-
矩阵乘法的Divide and Conquer Algorithm

Solving Recurrences – 2 Sorting - 1
-
代入法
- 重复替代
- 观察模式
- 确定合适的steps
-
递归树
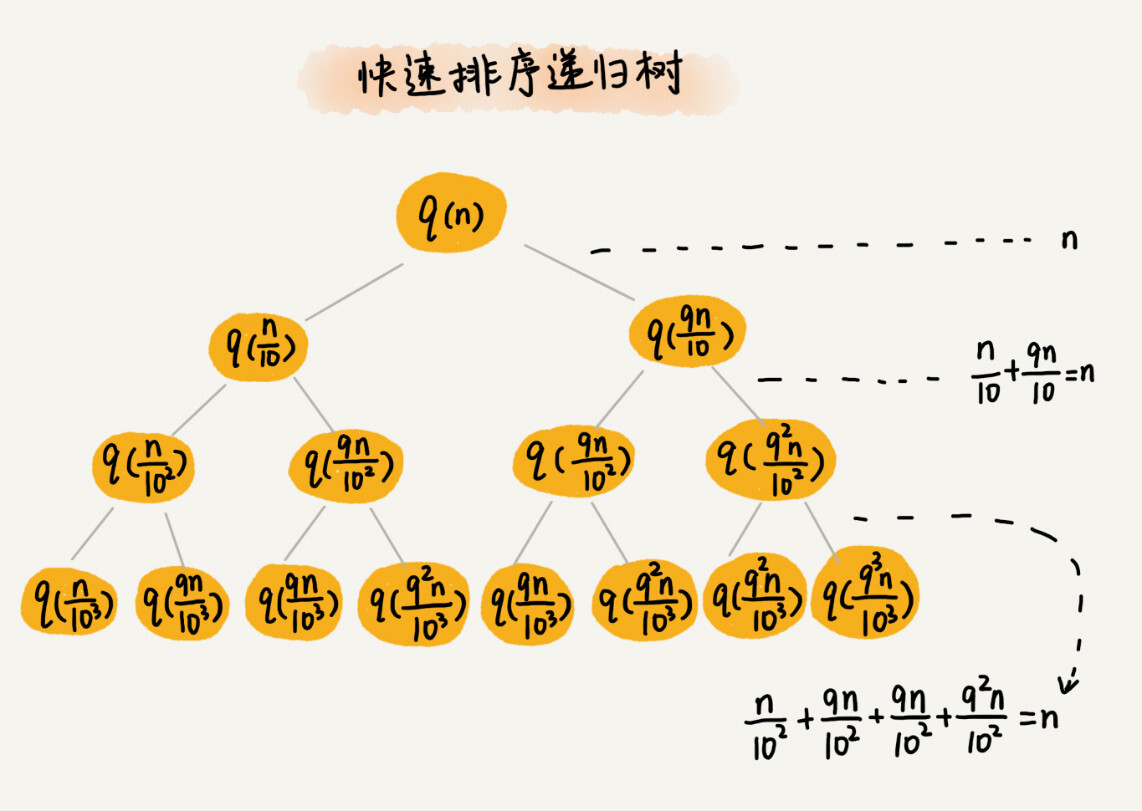
-
主方法
- 第一种情况:若 \(f(n)<n^{\log_{b}^a}\),那么 \(T(n)=\Theta(n^{\log_{b}^a})\) 。
- 第二种情况:若 \(f(n)=n^{\log_{b}^a}\),那么 \(T(n)=\Theta(n^{\log_{b}^a}\log n)\) 。
- 若 \(f(n)>n^{\log_{b}^a}\),那么 \(T(n)=\Theta(f(n))\) 。
-
循环不变性:循环执行过程中某些条件或属性始终为true的一种assertion。这些条件在循环的每次迭代中都是true的,并且在开始和结束后都是true.
- 不变性断言:提出的不变性假设。
- Initialization:循环开始之前初始状态满足所需的条件。
- Maintenance:每次迭代都不会破坏不变性条件,一次迭代前true,下一次迭代前也true.
- Termination:迭代结束时,不变性需要提供足够的信息来prove the correctness of the algorithm.
-
选择排序:顺次选i~l最小的即可,然后swap(i,l) 。
Sorting - 2
-
复杂度:
- concrete:算法的运行时间或所需步骤的数量,是一个具体的数值。
- abstract:关注算法性能的总体趋势,通常使用大O表示法。
-
heapify:维持堆的结构。
Basic Data Structures
- ADTs:数据集合和操作集合的抽象。
- 特点
- 隐藏了具体的实现细节,只暴露了操作的接口。
- 独立于实现方式。
- 封装了数据结构和算法,不用关心内部的实现机制。
- 优点
- 关注操作。
- 不用关注如何实现
- 将truth和efficiency depart,因为关注的是操作的逻辑,而不是具体的实现。
- 与data structure的关系
- 抽象 vs 具体
- 规范 vs 实现
- 特点
Data Structures - 2
散列表/哈希表
-
散列函数应当将一个大范围的键均匀的放到有限数量的槽位上。
-
冲突解决
- 链接法
- 开放寻址法
- 线性探测法:顺序找下一个空闲槽位。不好的点在于:多个元素连续的储存在相邻的位置上。
- 二次探测法:use 二次函数探测下一个空闲的位置,\(hash + i^2\) 。优点是减少聚集,缺点是实现复杂计算开销大。
- 双哈希:use 第二个哈希函数来确定下一个探测的位置,\(hash + hash2*i\) 。优点可以避免聚集且不会像二次探测有规律的变大。缺点实现复杂要俩哈希函数。
关于Ordered list Query Modify 一些函数的q
- 选择好的散列函数
- 哈希表的大小尽量为质数。
- 选择合适大小的模数。
Trees
delete:find successor point.
add:according to the rule
B-tree:
- defination
- 所有叶子depth相同。
- 每个内部节点有a个key和a+1个指向子节点的link
- p1 key1 p2 key2 ...... pn keyn pn+1,keyi 单调向上 。
- |keyi|keyi+1|,keyi比左边的link指向的key大,比右边的小。
- m阶b树,最少 \(\lceil\frac{m}{2}\rceil\) 个branches。
- 操作
- 插入:找到插入的位置进行插入,若没有上溢出,不用adjust,else 将中间元素 \(\lceil\frac{m}{2}\rceil\) 上移两边fracture。
- 构建:不断插入即可。
- 删除:删除非叶节点元素都相当于是删除叶节点元素(nxt or pre),若未下溢出无需adjust,若下溢出,兄弟够借的话借,不够的话,合并即可。
Dynamic Programing
- 记忆化比递推(自底向上方法)慢(因为递归的原因)
Elementary Graph Algorithms
-
dfs中顶点的属性
-
颜色属性:
- 白色:未被访问过。
- 灰色:已被访问过,但还在栈中。
- 黑色:已被访问过,但已经不在栈中。
-
时间戳属性:
- 发现时间Discovery Time。
- 完成时间Finishing Time。
-
父属性
- 父节点指向其在Tree里的上一个节点。
-
-
基于dfs的边分类
- 树边
- 非树边
- 后向边:连接到了祖先的边。
- 自环:连接到了相同的点。
- 前向边:连接到了已经被访问过的后代。(无向图没有)
- 交叉边:两个点在不同的dfs树中。(无向图没有)
Strongly Connected Components & Minimum Spanning Trees
强连通分量
使用Kosaraju算法
- DFS记录Finishing Time.
- 构造反图(即转置)。
- 逆向图上DFS,从Finishing Time最大的点开始。
重复2.3.得到的各个集合就是一个强连通分量。
prim&kruscal
1.safe edge,最小的可以选择的合法边。
通用算法
-
A边集合respect(S,V-S)意味着集合A中没有边跨过该割。
- 初始化:随机选择一个点作为起始点。
- 寻找轻边
- update MST and 割,使得新的割still respect MST。
重复2.3.直到MST包含所有顶点。
-
与prim和kruscal的关系
- 基于点的MST算法,管理一个increasing tree A,under the framework of 通用算法,每次扩展新边,然后将新点加入
- 基于边的MST算法,对于每一个点边集,通过寻找轻边来进行合并,然后update每一个点边集。
