初探编译链接原理
初探编译链接原理
bug
最近因为遇到了一个有意思的 bug,就去学习了一下编译链接原理,本篇博文记录学习过程中相关的一些思考。
foo5.c
/* $begin foo5 */
/* foo5.c */
#include <stdio.h>
void f(void);
int x = 15213;
int y = 15212;
int main()
{
f();
printf("x = %d y = %d \n",
x, y);
return 0;
}
/* $end foo5 */
bar5.c
/* $begin bar5 */
/* bar5.c */
double x;
void f()
{
x = -0.0;
}
/* $end bar5 */
编译运行:
gcc -o foobar5 foo5.c bar5.c
./foobar5

可以看到输出很明显不符合预期,好奇怪啊,按理来说应该是x = 15213,y=15212,但是为什么看起来像是 \(bar5.c\)中对 x 的赋值影响了
\(foo5.c\)中的 x,y 呢。这里我们先不进行解释,再对 bar5.c做一个简单的修改:
bar5.c
/* $begin bar5 */
/* bar5.c */
static double x; // 这里添加了 static
void f()
{
x = -0.0;
}
/* $end bar5 */

此时的结果就符合预期了。这个bug 一般被称为全局变量的命名污染问题。那么什么是全局变量的命名污染问题呢,让我们从编译链接的原理进行探索。
编译链接原理
本节内容参考《深入理解计算机系统》第七章链接原理。当我们编写完成一段代码,最终变成一个可执行文件中间经历了编译和链接两个过程。
编译则分为预处理,编译,汇编三个过程,预处理处理#开头的预处理命令,比如宏展开,条件编译指令;编译则是将预处理后的代码进行一定的语法语义分析,然后生成相关的汇编指令,汇编器主要是将前面编译器得到的main.s文件翻译成一个可重定位目标文件。(这个文件后面会展开介绍)。
链接则主要包含两个核心内容,符号解析和重定位。符号解析主要是将一系列符号进行匹配;重定位将各个目标文件的段(如代码段和数据段)合并到一个统一的内存布局中,调整对变量、函数等的引用,确保这些引用指向正确的内存地址。
最终才得到我们看到的可执行文件。
这一节内容介绍了一段源代码到最终的可执行文件的大致过程,但是里面引出了一些名词比如可重定位目标文件,符号解析。我们会在接下来展开介绍。
编译过程
- 预处理:这一步处理所有以
#开头的预处理指令。包括宏定义的展开、条件编译指令的处理以及头文件的包含。 - 编译:将预处理后的源代码转换成汇编代码。编译器将源代码分析(语法分析和语义分析),并生成对应的中间表示或直接生成汇编指令。
- 汇编:将编译阶段生成的汇编代码转换为机器可读的指令(通常是机器代码)。这些指令被封装成可重定位目标文件的格式(.o文件)。
链接过程
-
合并:
链接器将各个目标文件中的段(如代码段和数据段)合并。每个目标文件可能会有自己的段布局,链接器需要将它们合并到一个统一的内存布局中。(符号表也是其中的一个段,也是符号之间容易出现冲突的地方)。
-
符号解析:
- 局部符号:这些符号只在定义它们的源文件(即编译单元)中可见。链接时不需要特别处理这些符号,它们不会与其他目标文件中的符号发生冲突。
- 全局符号:可以被其他目标文件引用的符号。全局符号可以是变量或函数等。
- 未定义符号:这些符号在当前目标文件中被引用但未定义。链接器需要在其他目标文件中找到这些符号的定义。
链接器会检查所有的目标文件,将全局符号和未定义符号进行匹配。如果一个未定义的符号在其他某个目标文件中有定义,链接器就将这两个符号关联起来。
-
重定位:
- 链接器还需要调整代码中对变量、函数等的引用,确保这些引用指向正确的内存地址。例如,如果一个函数引用了另一个在不同目标文件中定义的函 数,链接器需要更新这个引用,使其指向正确的地址。
最终,链接器会生成一个可执行文件,这个文件包含了合并和重定位后的所有代码和数据,以及运行程序所需的所有其他信息(如程序入口点)。
可重定位目标文件查看
段
这个一个可重定位文件(.o)的结构:
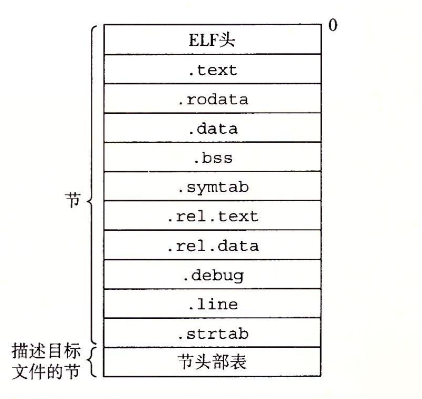
其中值得注意的是这几个:

我们使用如下命令查看.o文件:
gcc -c foo5.c
gcc -c bar5.c
// -c代表进行编译和汇编阶段,但是不链接,此时我们完成了编译过程,得到foo5.o、bar5.o文件
readelf -S foo5.o
readeldf -S bar5.o
// 这个指令代表使用 readelf 查看foo5.o、bar5.o的段内容
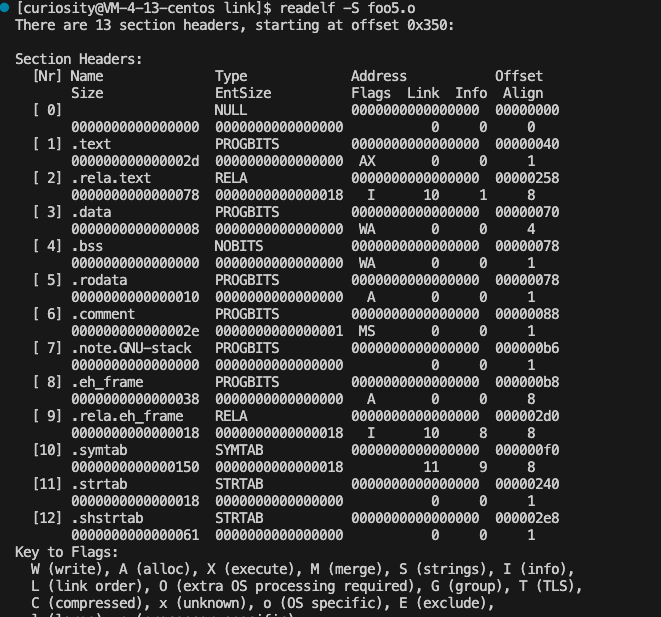 |
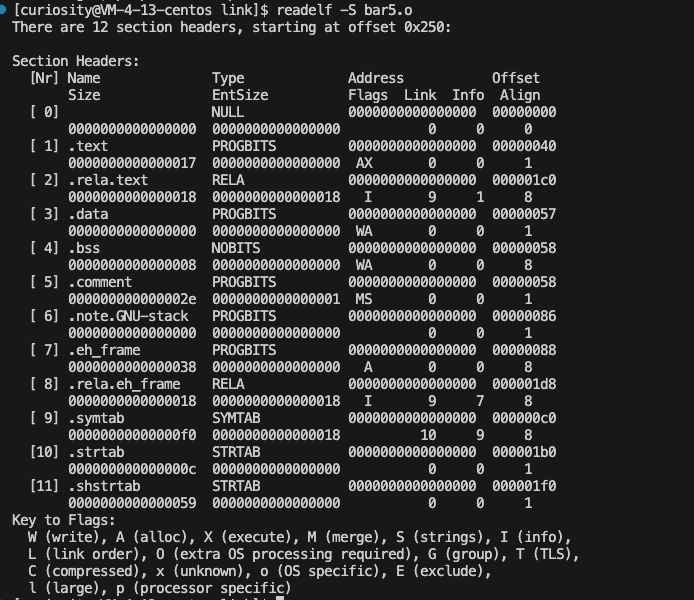 |
|---|
可以看到.text 段有一个AX 标志,代表 Alloc 和可执行。
其实这个过程翻译成大白话就是,一段源代码经过预编译,编译,汇编三个阶段,最后生成了机器码(.o 文件),这些机器码是按照段这样一个结构进行空间划分的,比如.data段,.bss段等等。但是此时代码之间还没有进行合并,合并过程我们会考虑解决全局的变量和函数之间的命名问题,这也就印出来下面的内容。
符号
我们使用如下命令查看一些foo5.o,bar5.o的符号表。
readelf -s foo5.o
readelf -s bar5.o
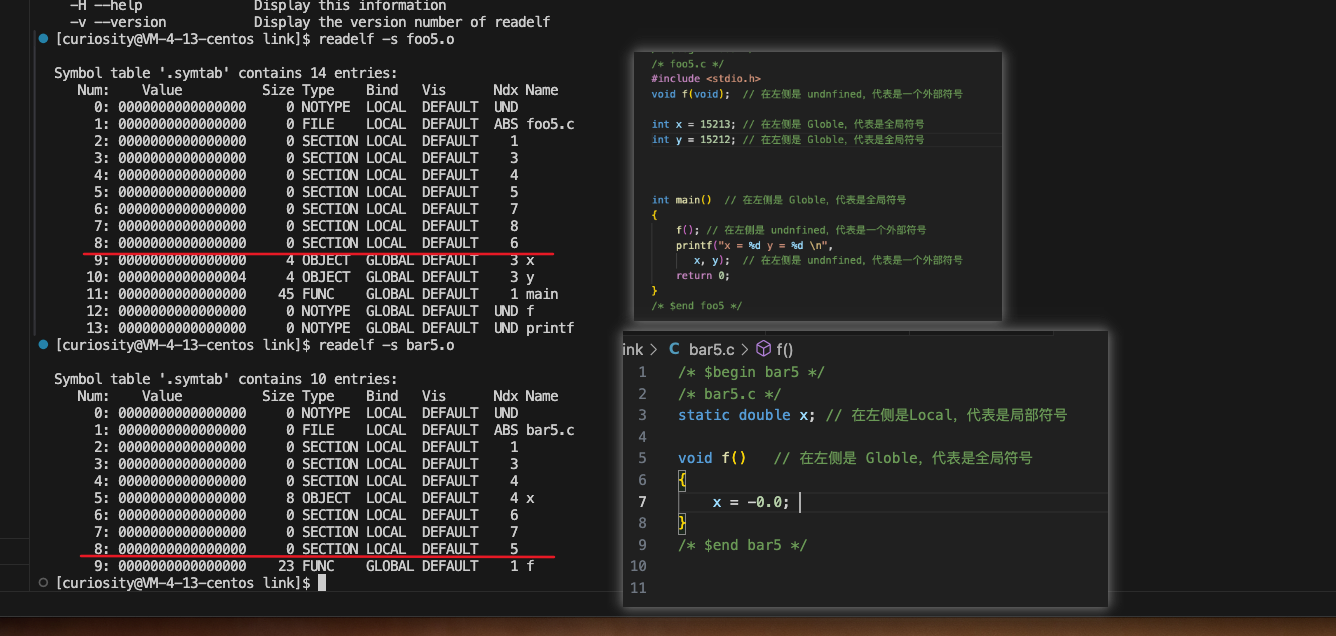
我们可以发现,所有的函数名,以及一些全局变量(没有添加 static 的)都是全局符号,这也就是说,在从一个源代码编译链接成一个可执行文件的时候,他们都是对每个源文件可见的。所以在合并过程的符合合并时就有可能会会产生冲突。
Linux 针对符号合并有如下规则:

所以到这里也就解释了一开始为什么foo5.c中的 x,y会被修改,这是因为 foo5.c中的x初始化了,是一个强符号,bar5.c中的 x 是一个弱符号,所以在合并过程中,就选择了foo5.c中的int x,然后 foo 函数调用赋值,就相当于用一个 double 进行了覆盖。
更多例子可参阅《深入理解计算机系统》P471。
.text段机器码&汇编代码
# 交错显示源代码和汇编代码(前提是目标文件中包含调试信息):
objdump -S foo5.o
objdump -S bar.o
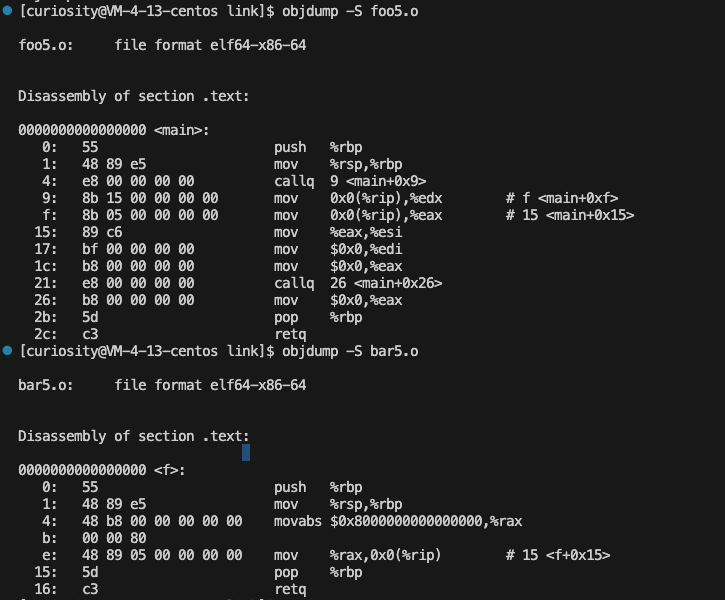
这个命令的主要作用是查看.o文件中.text段的内容,将里面的机器码通过调试信息得到汇编代码打印。但是此时我们可以发现一些地址出现的地方都是 0,这是因为编译链接的编译过程不负责地址定位,真正的地址定位写入是在链接阶段的合并过程完成之后进行重定位的、
那么就让我们接着看一下进行链接之后的 a.out 文件:
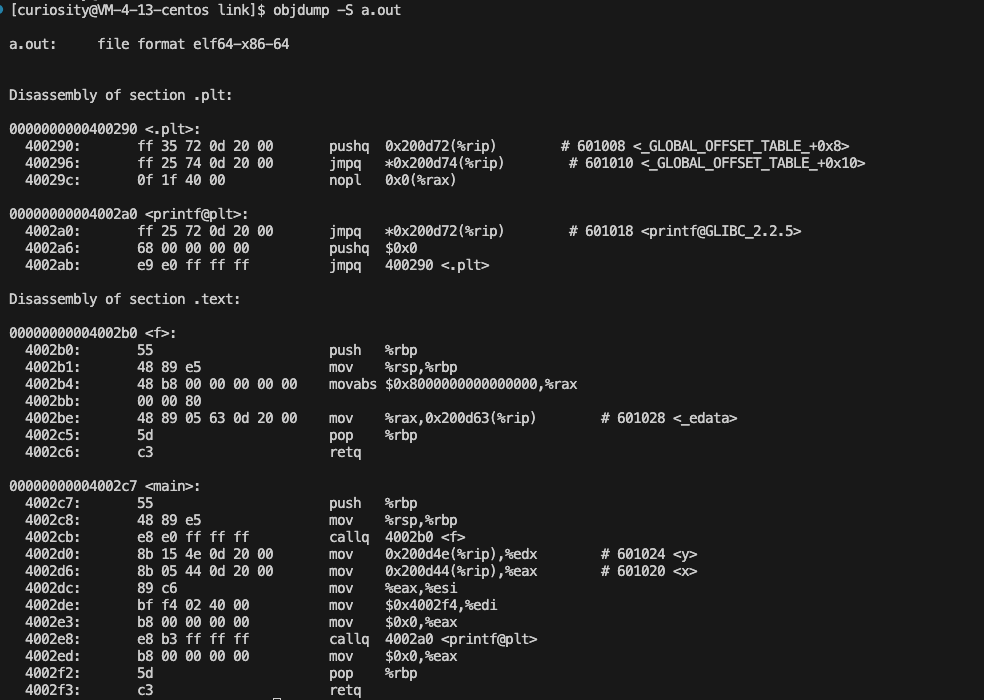
可以看到此时的代码才有了地址,这是链接器接器通过调整代码中对变量、函数等的引用,确保这些引用指向正确的内存地址实现的。
静态链接 vs 动态链接
静态链接
在静态链接中,所有需要的库函数和模块在创建可执行文件时被一次性集成进来。这意味着在链接过程中,从库中所需的代码会被复制到最终的可执行文件中。这个过程由静态链接器完成。
优点:
- 自足性:静态链接生成的可执行文件包含了所有必需的库代码,因此不依赖于系统上的外部库。这使得程序更易于分发,因为不必担心目标系统上库版本的兼容性问题。
- 性能:由于所有代码都包含在单个二进制文件中,程序启动时不需要加载外部库,可能会略微提高运行时的性能。
缺点:
- 文件大小:静态链接的可执行文件通常比动态链接的大,因为它包含了所有必需的库代码。
- 更新和维护:如果库更新(例如,修复了一个安全漏洞),每个使用该库的静态链接程序都需要重新编译和分发。这会导致维护成本增加。
动态链接
动态链接不会在编译时将库代码集成到可执行文件中。相反,程序包含对共享库(如 .dll 文件在 Windows 或 .so 文件在 UNIX/Linux)的引用,这些库在程序运行时被加载。
优点:
- 内存和磁盘空间节省:多个程序可以共享同一份物理内存中的同一个库的副本,减少了总体内存和存储需求。
- 便于更新:当库需要更新或修复时,只需替换系统上的共享库文件,而无需重新编译依赖该库的每个程序。
缺点:
- 依赖性问题:如果共享库在系统上不可用或版本不兼容,可能导致程序无法运行。
- 启动时间:因为在程序启动时需要加载外部库,可能稍微增加程序的启动时间。
实现机制
- 静态链接器:在编译时,静态链接器查找程序中引用的所有符号(如函数、变量等),并从静态库中解析这些符号,将必要的库代码直接复制到最终的可执行文件中。
- 动态链接器(也称为运行时链接器或加载器):在程序运行时,动态链接器负责加载程序所需的动态库,解析外部符号引用,并在必要时执行地址重定位。这通常是通过操作系统的一部分来完成的 。
总结
这篇博文由一个 bug 引出了编译链接的整个过程。我们可以看到一个源代码文件最终变成一个可执行文件中间经历了编译和链接两个过程,编译过程又分为预编译,编译,和汇编;预编译阶段主要处理#开头的代码,编译则是进行一些语法分析和优化,最终生成汇编代码,而汇编则是生成机器代码,同时将源文件通过一个叫做可重定位目标文件进行保存。这个可重定位目标文件里面有一个段,叫做符号表段,里面存储了当前源文件的符号(主要是函数,以及一些全局变量)。之后链接过程会分为合并,符号解析,重定位三个阶段。合并主要就是合并.text,.data, .bss段等,其中符号表段合并时由于不同文件之间可能会有一些重名的符号,因此在这一步可能会触发一些隐晦的 bug,重定位则是根据最终合并后的一些数据和函数的地址,将对应的机器码调用地址进行修改。
最后我们探讨了静态链接和动态链接。静态链接其实本质上就是不同文件直接进行合并,好处是程序更易于分发,同时性能好一些。坏处是程序体积会很大,同时会有内存资源的浪费,同时也不利于维护。动态链接则是存储了一个到动态链接库的映射,程序再进行加载的时候,动态链接器会将动态链接库里的一些符号解析到本地代码,必要时进行重定位。这样的好处是程序更加轻量化,节省内存空间,同时也便于维护。缺点是容易产生依赖性问题,性能相对来说差一些。
最新进展, gcc 4.8 不会检查强弱符号,gcc 11 double 也是强符号,此时编译不通过。

本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/18396700

 浙公网安备 33010602011771号
浙公网安备 33010602011771号