原子指令,自旋锁,CAS
原子指令,自旋锁,CAS
问题
我们先看一下这段代码:
/*
* badcnt.c - An improperly synchronized counter program
*/
/* $begin badcnt */
/* WARNING: This code is buggy! */
#include "csapp.h"
void *thread(void *vargp); /* Thread routine prototype */
/* Global shared variable */
volatile long cnt = 0; /* Counter */
int main(int argc, char **argv)
{
long niters;
pthread_t tid1, tid2;
niters = 100000;
/* Create threads and wait for them to finish */
Pthread_create(&tid1, NULL, thread, &niters);
Pthread_create(&tid2, NULL, thread, &niters);
Pthread_join(tid1, NULL);
Pthread_join(tid2, NULL);
/* Check result */
if (cnt != (2 * 100000))
printf("BOOM! cnt=%ld\n", cnt);
else
printf("OK cnt=%ld\n", cnt);
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
long i, niters = *((long *)vargp);
for (i = 0; i < niters; i++) //line:conc:badcnt:beginloop
cnt++; //line:conc:badcnt:endloop
return NULL;
}
/* $end badcnt */
这段代码创建了两个线程,每个线程都对cnt全局变量执行100000次++操作,所以我们的得到的cnt应该是200000,但是结果却并不是这样:
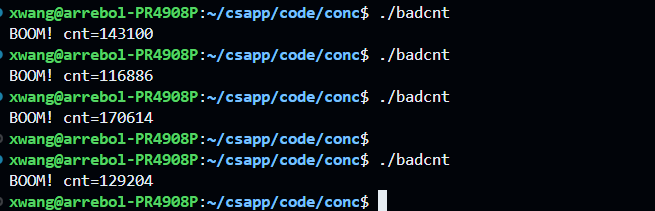
很奇怪啊,两个线程都对cnt执行++操作,怎么比200000要小啊,而且每次结果都不一样。
其实从汇编语言(指令)的角度去理解这个,就能解释这个问题。将cnt++翻译成对应的汇编指令,是这样:
movq cnt(%rip), %rdx // 加载cnt
addq $1, %rdx // 更新cnt
movq %rdx, cnt(%rip) // 写回cnt
我们知道,指令才是cpu上执行的最小单位(可以把一条指令的执行理解成不可中断的),我们可以发现,如果一个进程在更新cnt之后,还没有写回,但是此时另一个进程已经读取了cnt,是不是就出问题了!就比如此时cnt是1,一个进程取出来了进行加1,得到2,但是还没有写回,但是另一个进程此时正在执行第一条指令,这样就出问题了。所以这是导致cnt结果不符合期待的原因。
解决方案
思路1
前面不是说一个++操作被分解为了三条指令吗,如果CPU实现了一个这样的指令:
inc 1, cnt(%rip)
这个指令是在cnt(%rip)上实现加1操作,这样是不是就万事无忧了,但是其实这样也是不行的🙅,因为指令并不是CPU上执行的最小单位,现代处理器CPU会把一个指令分为五个步骤进行执行,取指,译码,访存,执行,写回,这样做是为了实现处理器流水线,加快指令的执行。详见:CSAPP学习笔记——chapter4 处理器体系结构
所以正如下图所示,如果一个前面的inc指令在写回之前,前面已经有指令进行了访存,那么一样会导致错误的结果。
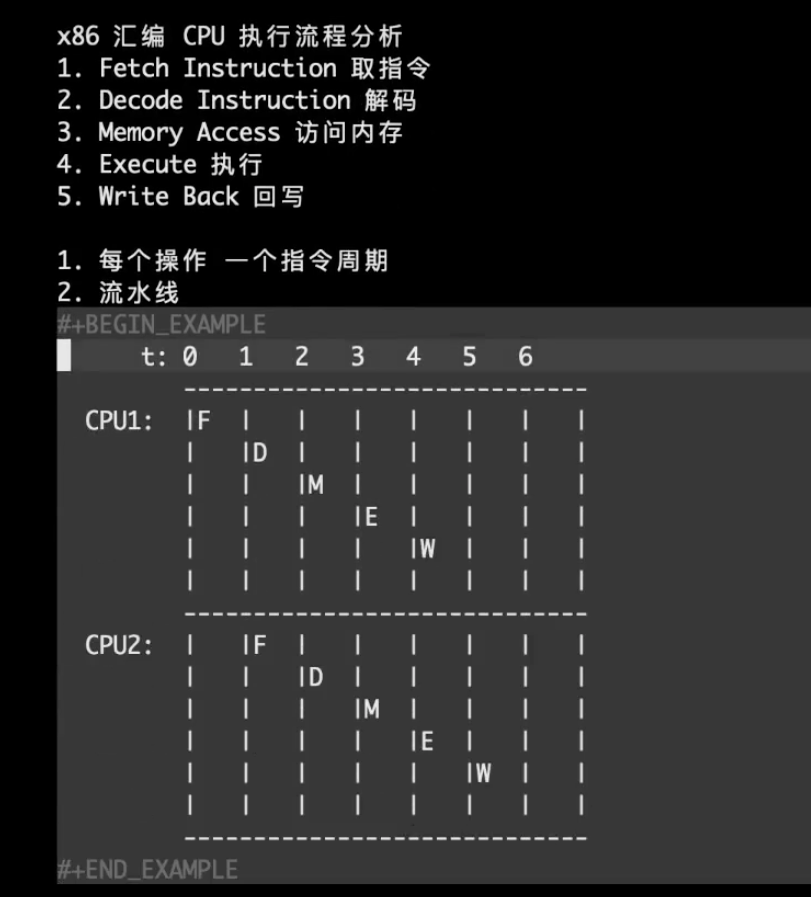
原子指令
C++给我们提供了原子操作: atomic<int> cnt;这个时候对cnt进行算数运算,就是正确的。宏观意义上就是对a进行的操作是原子的,但是atomic的是怎么实现的呢?。其实x86-64处理器提供了一个汇编指令帮助编译器实现atomic。
也就是 CMPXCHG (compare and exchange)(原子指令):
在执行CMPXCHG之前,先在EAX中存储了旧值,
这个指令的功能是这样的:
- 比较:
CMPXCHG首先将目标内存位置的值与 EAX 或 RAX中的旧值进行比较。- 交换:如果目标内存位置的值与寄存器中的值相等(即比较结果为相等),
CMPXCHG会将另一个指定寄存器的值写入目标内存位置。如果不相等,CMPXCHG将目标内存位置的值加载到那个寄存器中。这个指令的基本形式如下:
CMPXCHG 目标位置(与eax比较), source
稍微提一下原子指令在x86 硬件上的实现,大概如下图所示,将下一条指令的读内存给推迟到了上一条指令的写回。所以原子指令会牺牲一定的效率,但是又相较于使用互斥锁效率高,因为没有线程的上下文切换等开销。
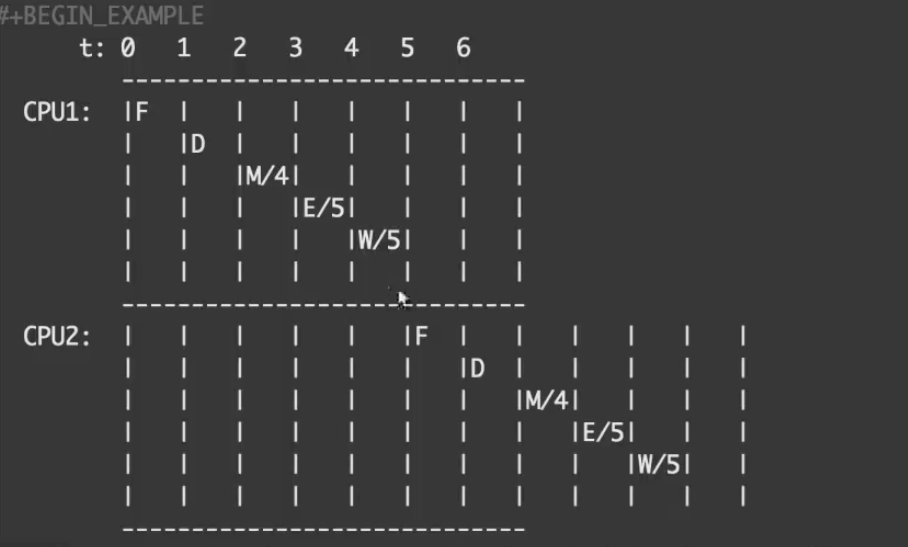
在执行累加之前,首先把cnt的旧值存储到eax中,然后再去读取这个值,并执行运算得到source值,此时就会执行CMPXCHG了,如果旧值和目标位置值相等,就写入,这个写入是不可中断的(应该是CMPXCHG内部的实现),如果不相等,就把目标内存的值加载到eax中的值就会被更新为内存中的新值,再重新执行算数操作,然后重复这个过程。
自旋锁
在xv6上基于原子指令还可以实现自旋锁,核心代码在这里:
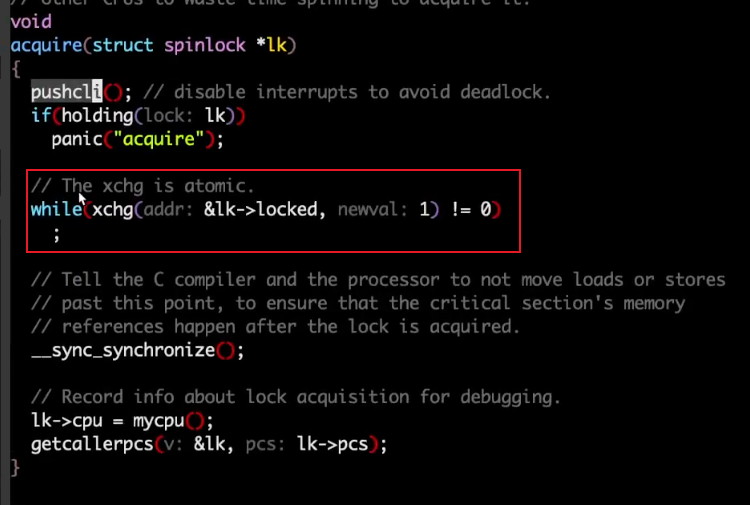
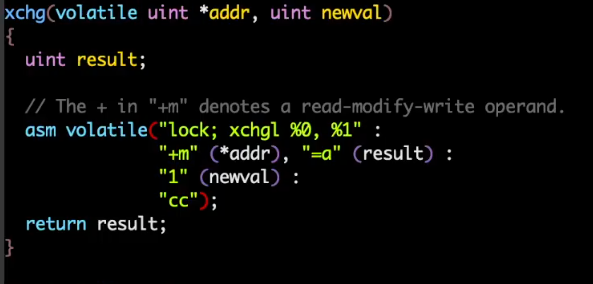
可以看到这里不断的想使用 xchg获取一把锁,将锁的值设为 1,如果写入之前不是 0,就代表获取锁失败了,因此会在这里使用 while 循环一直等待。
可以看到自旋锁也没有涉及线程的阻塞。
refer
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/18086216

 浙公网安备 33010602011771号
浙公网安备 33010602011771号