CSAPP学习笔记——Chapter10,11 系统级I/O与网络编程
CSAPP学习笔记——Chapter10,11 系统级I/O与网络编程
Chapter10 系统级I/O
系统级I/O这一章的内容,主要可以通过这张图概括:
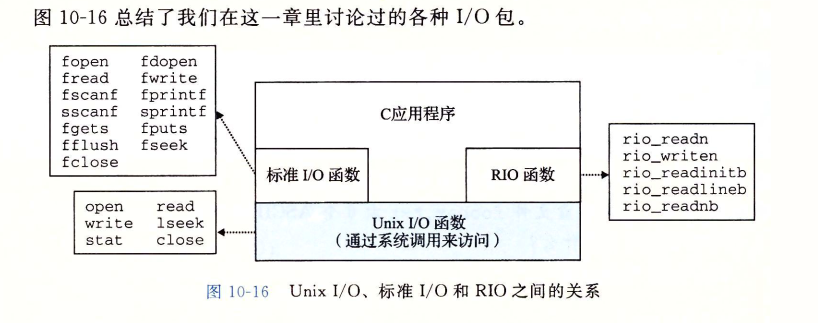
Unix I/O模型是在操作系统内核中实现的。应用程序可以通过诸如 open、close、lseek、read、write 和 stat 这样的函数来访 Unix I/O。较高级别的 RIO 和标准I/O函数都是基于(使用)Unix I/O 函数来实现的。RIO函数是专为本书开发的 read 和 write的健壮的包装函数。它们自动处理不足值,并且为读文本行提供一种高效的带缓冲的方法。标准I/O 函数提供了 Unix I/O 函数的一个更加完整的带缓冲的替代品,包括格式化的I/O例程,如printf和 scanf。
这里面有一个知识点,缓冲相较于没有缓冲的Unix I/O好在什么地方?
下面我会围绕这这个问题介绍一下Unix I/O、RIO、标准I/O函数。
Unix I/O

read
read 函数从描述符为 fd 的当前文件位置复制最多n个字节到内存位置 buf。返回值-1表示一个错误,而返回值 0 表示 EOF。否则,返回值表示的是实际传送的字节数量。
返回值
- 成功时,返回实际读取的字节数,这个值可能小于请求的
count,特别是在读取普通文件时到达文件末尾,或者在读取网络数据时网络缓慢等情况下。 - 如果读取到文件末尾(EOF),返回
0。 - 出错时,返回
-1,并设置errno以指示错误类型。
阻塞行为
read调用的阻塞行为取决于文件描述符的状态和读取操作的上下文:
- 对于普通文件,如果请求的
count字节可用,read通常会读取所请求的字节数并返回。如果到达文件末尾,返回的字节数可能会少于请求的count,或者在完全到达末尾时返回0。 - 对于网络套接字和管道,如果没有数据可读,
read会阻塞,直到有数据到达、连接关闭、或者收到信号中断read调用。 - 文件描述符可以被设置为非阻塞模式。在这种模式下,如果
read操作会阻塞,它会立即返回-1,并且errno被设置为EAGAIN或EWOULDBLOCK。
错误处理
read函数在出错时返回-1,具体的错误原因可以通过检查errno值来确定。一些常见的错误包括:
EINTR:读取操作被信号中断。EAGAIN或EWOULDBLOCK:在非阻塞模式下,当前没有数据可读。EBADF:fd不是一个有效的文件描述符或不是打开的读取。EFAULT:buf指向的缓冲区不可访问。
write
write 函数从内存位置 buf 复制至多n个字节到描述符 的当前文件位置。
这两个Unix I/O函数是没有缓冲区的,也就是每次读写都是内存和文件的直接交互。
RIO函数
RIO(Robust I/O)提供了两种不同的函数:
- 无缓冲的输入输出函数。这些函数直接在内存和文件之间传送数据,没有应用级缓冲。它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
- 带缓冲的输入函数。这些函数允许你高效地从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内,类似于为 printf 这样的标准 I/0函数提供的缓冲区。与[110]中讲述的带缓冲的I/0 例程不同,带缓冲的 RIO 输入函数是线程安全的,它在同一个描述符上可以被交错地调用。例如,你可以从一个描述符中读一些文本行,然后读取一些二进制数据,接着再多读取一些文本行。
因为我们的读写主要是文本文件,所以第一类函数不在今天的讨论范围。
缓冲区定义
/* Persistent state for the robust I/O (Rio) package */
/* $begin rio_t */
#define RIO_BUFSIZE 8192
typedef struct {
int rio_fd; /* 文件描述符,也就是被缓冲的文件*/
int rio_cnt; /* Unread bytes in internal buf */
char *rio_bufptr; /* Next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* Internal buffer */
} rio_t;
/* $end rio_t */
初始化缓冲区函数
/* $begin rio_readinitb */
void rio_readinitb(rio_t *rp, int fd)
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
}
/* $end rio_readinitb */
当读写缓冲区初始化之后,
rio_read
还需要看一个rio_read()的源码,这个是基于Unix I/O read编写的带缓冲版本:
/* $begin rio_read */
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
{
// rio_t 缓冲区
// userbuf 用户存放数据的存放地
// 用户希望读取的字节数
int cnt;
while (rp->rio_cnt <= 0) { /* Refill if buf is empty */
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf,
sizeof(rp->rio_buf));
if (rp->rio_cnt < 0) {
if (errno != EINTR) /* Interrupted by sig handler return */
return -1;
}
else if (rp->rio_cnt == 0) /* EOF */
return 0;
else
rp->rio_bufptr = rp->rio_buf; /* Reset buffer ptr */
}
/* Copy min(n, rp->rio_cnt) bytes from internal buf to user buf */
cnt = n;
if (rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, cnt);
rp->rio_bufptr += cnt;
rp->rio_cnt -= cnt;
return cnt;
}
/* $end rio_read */
这个函数在读取数据之前,先把缓冲区填满,然后再把数据从缓冲区填入到userbuf。
返回从内部缓冲区复制到用户缓冲区的字节数,如果遇到错误(read返回-1且errno不是EINTR),则返回-1。如果遇到文件结束(EOF),并且没有数据可读(即在尝试重填缓冲区之前rio_cnt就为0),则返回0。
基于这个函数我们得到了rio_readlineb和rio_readnb:
rio_readlineb
/* $begin rio_readlineb */
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
{
int n, rc;
char c, *bufp = usrbuf;
for (n = 1; n < maxlen; n++) {
if ((rc = rio_read(rp, &c, 1)) == 1) {
*bufp++ = c;
if (c == '\n') {
n++;
break;
}
} else if (rc == 0) {
if (n == 1)
return 0; /* EOF, no data read */
else
break; /* EOF, some data was read */
} else
return -1; /* Error */
}
*bufp = 0;
return n-1;
}
/* $end rio_readlineb */
这段代码是一个读取行的函数,它逐个字符地从输入源(通过rio_t *rp表示)读取字符,直到遇到换行符\n或达到最大长度maxlen。这个函数在读取到行的末尾或遇到文件结束(EOF)时停止读取,并且在遇到错误时返回-1。
在函数的最后,*bufp = 0;这行代码的作用是在字符串的末尾添加一个空字符(null terminator,值为0的字符),将其转换为一个标准的C字符串。C字符串是以空字符结尾的字符数组,这样做可以确保使用字符串的函数(如printf、strlen等)能够正确识别字符串的结束位置。
rio_readnb
/* $begin rio_readnb */
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = rio_read(rp, bufp, nleft)) < 0)
return -1; /* errno set by read() */
else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* return >= 0 */
}
/* $end rio_readnb */
如果只看返回值的话,这个函数似乎和rio_read()的功能似乎是一样的,都是调用者给定一个缓冲区(包含文件描述符),一个userbuf,一个最大字节数n,返回未读取的字节数。其实这两个函数的主要区别在于数据的读取量不同,前者更加侧重于单次读取操作,往往小于用户请求的数据,后者则是用户使用时才调用的函数,它会持续调用rio_read直到达到用户请求的字节数n或遇到EOF。
综上这三者的关系如下:
标准I/O

这里主要介绍了标准I/O在网络应用上的限制,大概意思就是两个流不能同时参与一个文件的读写。这会对套接字编程带来一些坏的影响。
回答之前的问题
说了这么多,在文件和内存之间的一个添加一个应用级缓冲,有什么好处?
在我看来主要是性能
-
减少磁盘I/O操作次数
缓冲区能够一次读很多的数据,也就是将很多小的I/O操作合并成一次大的I/O操作,从而避免了程序陷入内核引发多次的磁盘读写。
-
减少系统调用
每次进行文件I/O操作时,通常涉及到系统调用,这些调用在用户空间和内核空间之间进行上下文切换,有一定的开销。通过缓冲,可以减少需要进行的系统调用的次数,因为数据可以在用户空间的缓冲区中累积到一定量后再一次性地进行系统调用处理。
Chapter11 网络编程
这一章的前面介绍了一些计网的知识,大致描述了主机A中的一个进程是怎么把数据传送到主机B的进程的。
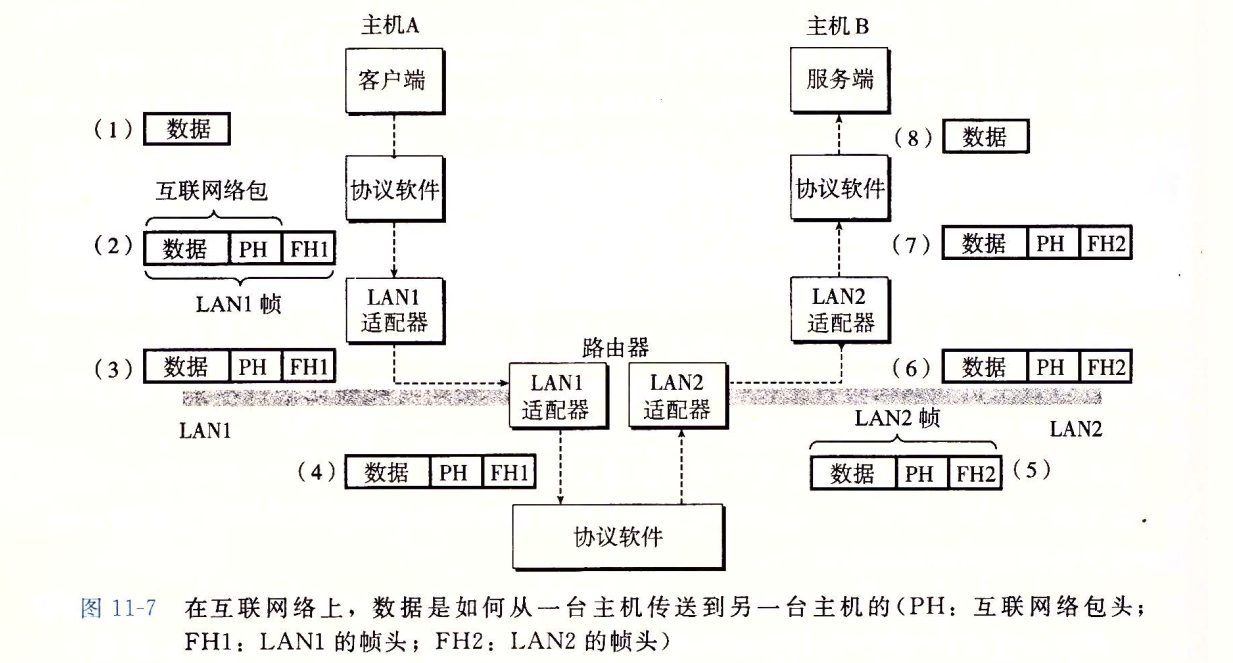
接下来我主要介绍一下套接字编程的基本概念:
一个连接是由它两端的套接字地址唯一确定的。这个套接字地址叫做套接字对,由下列元组来表示:
(cliaddr:cliport, servaddr:servport)
其中 cliaddr 是客户端的 IP 地址,cliport是客户端的端口,servaddr是服务器的IP地址,而servport 是服务器的端口。例如,图11-11 展示了一个 Web 客户端和一个 Web
服务器之间的连接。

套接字接口
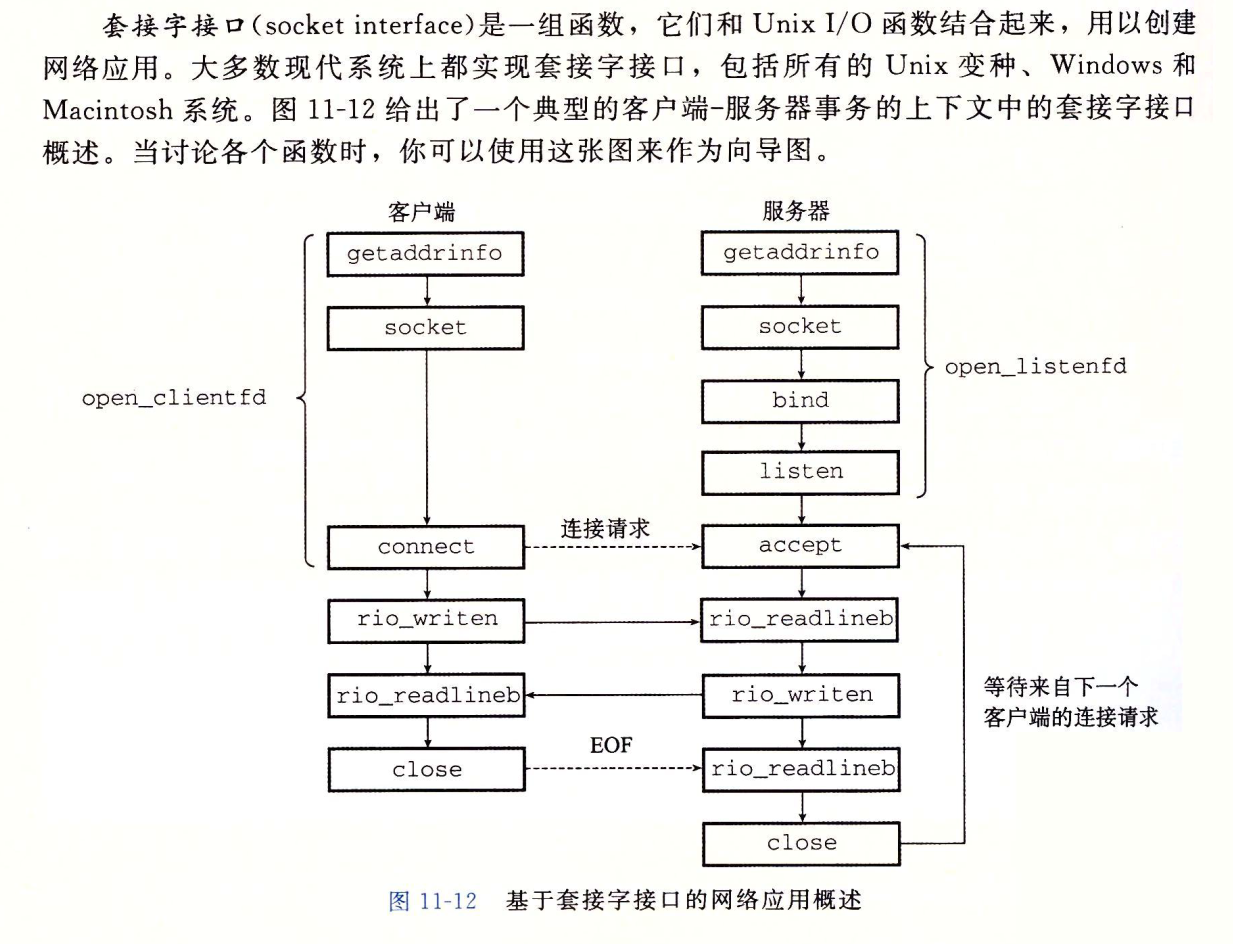
套接字地址结构

主机和服务的转换
Linux提供了一些强大的函数(称为 getaddrinfo和getnameinfo)实现二进制套接字地址结构和主机名、主机地址、服务名和端口号的字符串表示之间的相互转化。当和套接字接
口一起使用时,这些函数能使我们编写独立于任何特定版本的IP协议的网络程序。
getaddrinfo

这个函数接收一个主机地址host,服务类型service,以及一个控制连接属性的hints,返回一个指向addrinfo结构的列表。
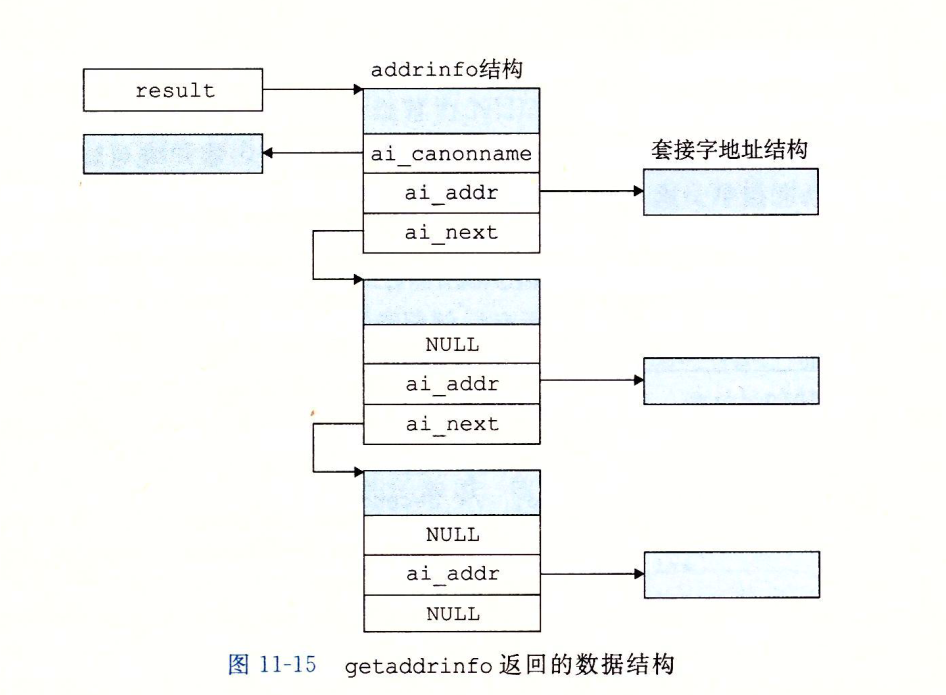

在客户端调用了 getaddrinfo之后,会遍历这个列表,依次尝试每个套接字地址,直到调 用socket 和 connect 成功,建立起连接。类似地,服务器会尝试遍历列表中的每个套接字地址,直到调用 socket 和 bind成功,描述符会被绑定到一个合法的套接字地址。为了避免内存泄漏,应用程序必须在最后调用 freeaddrinfo,释放该链表。
getnameinfo

这个函数接受一个套接字地址,套接字的大小。然后将套接字中的主机地址和服务类型保存到host和service中。
至于flags:

示例
我们看一段代码 hostinfo.c,综合运用了上面的两个函数,这段代码展示出域名到它相关联的IP地址之间的映射:
/* $begin hostinfo */
#include "csapp.h"
int main(int argc, char **argv)
{
struct addrinfo *p, *listp, hints;
char buf[MAXLINE];
int rc, flags;
if (argc != 2) {
fprintf(stderr, "usage: %s <domain name>\n", argv[0]);
exit(0);
}
/* Get a list of addrinfo records */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET; /* IPv4 only */ //line:netp:hostinfo:family
hints.ai_socktype = SOCK_STREAM; /* Connections only */ //line:netp:hostinfo:socktype
if ((rc = getaddrinfo(argv[1], NULL, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo error: %s\n", gai_strerror(rc));
exit(1);
}
/* Walk the list and display each IP address */
flags = NI_NUMERICHOST; /* Display address string instead of domain name */
for (p = listp; p; p = p->ai_next) {
Getnameinfo(p->ai_addr, p->ai_addrlen, buf, MAXLINE, NULL, 0, flags);
printf("%s\n", buf);
}
/* Clean up */
Freeaddrinfo(listp);
exit(0);
}
/* $end hostinfo */
我们可以看到这段代码先是hints定义了连接的一些属性,然后调用getaddrinfo获得与给定服务器的连接列表,再去遍历这个addrinfo列表,读取其中的ip。

这里也可以用这个ip访问百度了。
进一步封装
这一小节介绍客户端使用getaddrinfo和socket函数得到和服务器连接的函数openclientfd以及服务器创建监听描述符的函数opend_listenfd。
/********************************
* Client/server helper functions
********************************/
/*
* open_clientfd - Open connection to server at <hostname, port> and
* return a socket descriptor ready for reading and writing. This
* function is reentrant and protocol-independent.
*
* On error, returns:
* -2 for getaddrinfo error
* -1 with errno set for other errors.
*/
/* $begin open_clientfd */
int open_clientfd(char *hostname, char *port) {
int clientfd, rc;
struct addrinfo hints, *listp, *p;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */
if ((rc = getaddrinfo(hostname, port, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo failed (%s:%s): %s\n", hostname, port, gai_strerror(rc));
return -2;
}
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
if (close(clientfd) < 0) { /* Connect failed, try another */ //line:netp:openclientfd:closefd
fprintf(stderr, "open_clientfd: close failed: %s\n", strerror(errno));
return -1;
}
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* All connects failed */
return -1;
else /* The last connect succeeded */
return clientfd;
}
/* $end open_clientfd */
/*
* open_listenfd - Open and return a listening socket on port. This
* function is reentrant and protocol-independent.
*
* On error, returns:
* -2 for getaddrinfo error
* -1 with errno set for other errors.
*/
/* $begin open_listenfd */
int open_listenfd(char *port)
{
struct addrinfo hints, *listp, *p;
int listenfd, rc, optval=1;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Accept connections */
hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG; /* ... on any IP address */
hints.ai_flags |= AI_NUMERICSERV; /* ... using port number */
if ((rc = getaddrinfo(NULL, port, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo failed (port %s): %s\n", port, gai_strerror(rc));
return -2;
}
/* Walk the list for one that we can bind to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Eliminates "Address already in use" error from bind */
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, //line:netp:csapp:setsockopt
(const void *)&optval , sizeof(int));
/* Bind the descriptor to the address */
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */
if (close(listenfd) < 0) { /* Bind failed, try the next */
fprintf(stderr, "open_listenfd close failed: %s\n", strerror(errno));
return -1;
}
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* No address worked */
return -1;
/* Make it a listening socket ready to accept connection requests */
if (listen(listenfd, LISTENQ) < 0) {
close(listenfd);
return -1;
}
return listenfd;
}
/* $end open_listenfd */
一个用于得到一个文件描述符clientfd,客户端可以直接通过这个描述符进行文件读写;一个用于打开一个监听端口,使得用户能够请求这个端口并连接。
echo服务器
这里算是对上面内容的一个综合运用,包含了系统级I/O。
客户端
/*
* echoclient.c - An echo client
*/
/* $begin echoclientmain */
#include "csapp.h"
int main(int argc, char **argv)
{
int clientfd;
char *host, *port, buf[MAXLINE];
rio_t rio;
if (argc != 3) {
fprintf(stderr, "usage: %s <host> <port>\n", argv[0]);
exit(0);
}
host = argv[1];
port = argv[2];
clientfd = Open_clientfd(host, port);
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL) {
Rio_writen(clientfd, buf, strlen(buf)); //将读取的文本行发送给服务器
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}
Close(clientfd); //line:netp:echoclient:close
exit(0);
}
/* $end echoclientmain */
客户端使用服务器的地址和端口,得到一个连接clientfd,这个时候使用Rio_writen将buf中的数据写到clientfd,其实也就是将buf中的数据传送到了服务器。
然后再使用Rio_readlineb读取服务器传回的数据,打印输出。
服务器
/*
* echoserveri.c - An iterative echo server
*/
/* $begin echoserverimain */
#include "csapp.h"
/*
* echo - read and echo text lines until client closes connection
*/
/* $begin echo */
#include "csapp.h"
void echo(int connfd)
{
size_t n;
char buf[MAXLINE];
char test[6] = {'h', 'e', 'l', 'l', 'o', '\n'};
rio_t rio;
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //line:netp:echo:eof
printf("server received %d bytes\n", (int)n);
Fputs(buf, stdout);
Rio_writen(connfd, test, 6);
}
}
/* $end echo */
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr; /* Enough space for any address */ //line:netp:echoserveri:sockaddrstorage
char client_hostname[MAXLINE], client_port[MAXLINE];
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *) &clientaddr, clientlen, client_hostname, MAXLINE,
client_port, MAXLINE, 0);
printf("Connected to (%s, %s)\n", client_hostname, client_port);
echo(connfd);
Close(connfd);
}
exit(0);
}
/* $end echoserverimain */
服务器端则是先使用listenfd = Open_listenfd(argv[1]);打开一个监听端口,然后进入一个无限循环,调用Accept函数等待来自客户端的连接,连接之后输出客户端的信息,然后调用echo给客户端返回信息。
echo服务器总结
其实我一开始看客户端和服务器端的代码的时候,是有很多疑问的,惊讶于为什么服务器和客户端运行的如此有序:
服务器端接受客户端信息并打印:
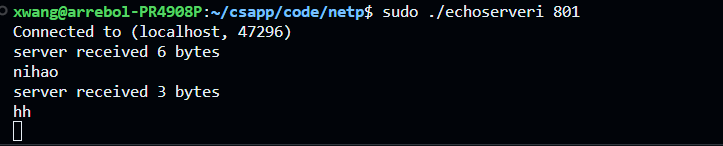
客户端发送给服务器信息并打印接受到的信息:

其中红框是发送的信息,hello是服务器返回的信息;
一方面我好奇为什么运行地如此有序?客户端发送数据,服务器接受数据,然后服务器再返回数据,客户端再打印服务器返回的数据。另一方面我由注意到,Rio_readlineb的源码如果没有读到数据,会返回-1,或者0,如果客户端读取的时候,服务器还没有返回数据,这个函数不就报错吗?然而事实并没有。
答案来自rio_readlineb里的rio_read函数里的Unix I/O 的read函数:
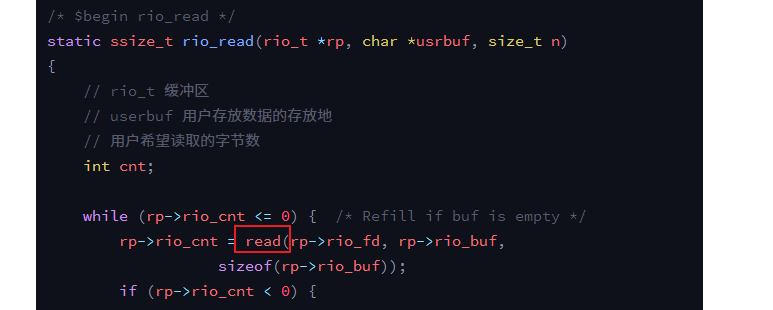

Unix系统调用已经帮我们实现了在网络套接字编程时,read函数没有数据读取时的阻塞行为。根据函数的包装,也就是如下:
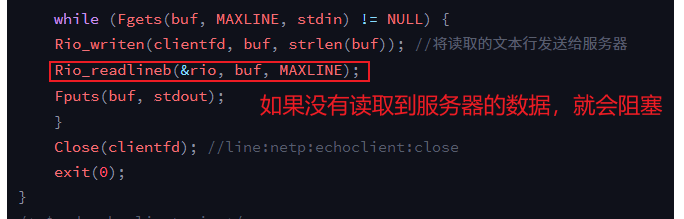
这样前面为什么有序的问题也就解答了。
Unix I/O & 网络编程总结
本篇博文介绍了《深入理解计算机系统中》Unix I/O,以及网络编程章节的一些概念,之所以合在一起介绍是因为Unix I/O在网络编程中会用到。同时我们观察到此时的echo服务器统一时刻只能处理一个客户端的连接。下一章的并行编程我们会对echo服务器进行拓展,基于并发的理论使其能够同时处理多个连接。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/17991736

 浙公网安备 33010602011771号
浙公网安备 33010602011771号