CSAPP学习笔记——chapter9 虚拟内存
CSAPP学习笔记——chapter9 虚拟内存
虚拟内存提供三个重要的功能。第一,它在主存中自动缓存最近使用的存放磁盘上的虚拟地址空间的内容。虚拟内存缓存中的块叫做页。对磁盘上页的引用会触发缺页,缺页将控制转移到操作系统中的一个缺页处理程序。缺页处理程序将页面从磁盘复制到主存缓存,如果必要,将写回被驱逐的页。第二,虚拟内存简化了内存管理,进而又简化了链接、在进程间共享数据、进程的内存分配以及程序加载。最后,虚拟内存通过在每条页表条目中加人保护位,从而了简化了内存保护。
这一章主要介绍了现代操作系统中虚拟内存的概念,先是介绍了虚拟内存的一般概念,这一部分我将在本文第一小节进行一个串联;第二部分介绍了内存映射,并以Linux为例,介绍了fork函数,execve函数的实现细节;第三部分则是介绍了动态内存分配,程序员通过如malloc, new, free, delete等语言特定的函数和操作符来控制,重点介绍了动态内存分配器如何维护进程的堆区域。
xv6上的进程结构:
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
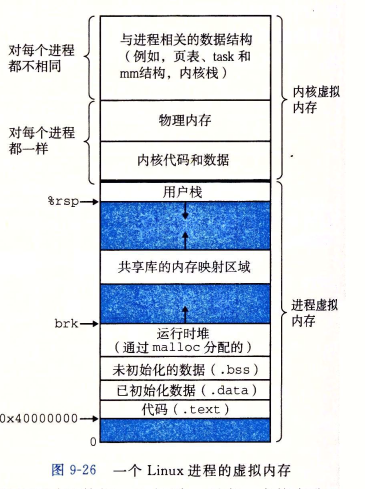
一、端到端的地址翻译
地址翻译符号小结
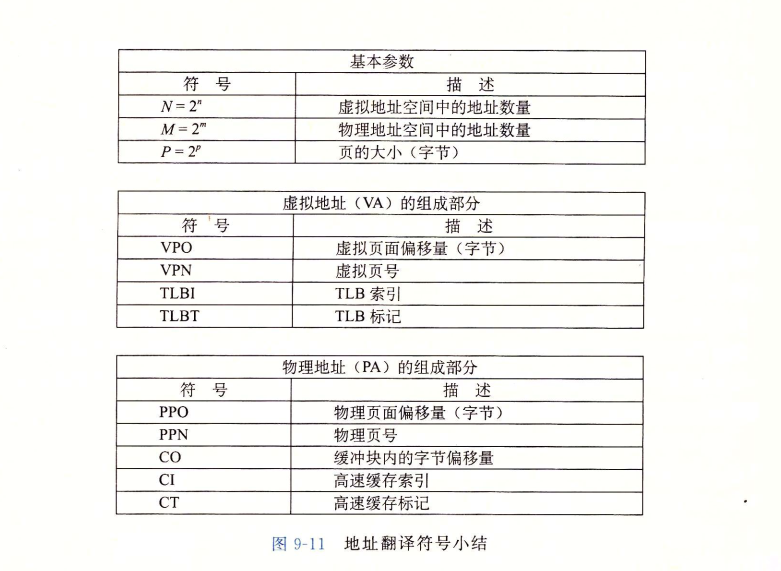
这里回顾一下MMU地址翻译的流程图:
地址翻译一般流程
处理器生成一个虚拟地址,地址翻译器(MMU)根据虚拟页号和页表基址寄存器中的值得到一个PTE(页表项),如果有效位为1,则将物理页号(PPN)与虚拟地址中的VPO串联起来,得到相应的物理地址。下面介绍结合了TLB和高速缓存的系统的地址翻译流程。
在这一节里,我们通过一个具体的端到端的地址翻译示例,来综合一下我们刚学过的这些内容,这个示例运行在有一个 TLB 和 LI d-cache 的小系统上。为了保证可管理性,我们做出如下假设:
- 内存是按字节寻址的。
- 内存访问是针对 1字节的字的(不是4 字节的字)
- 虚拟地址是 14 位长的(n=14)。
- 物理地址是12 位长的(m=12)
- 页面大小是 64 字节(P=64)。
- TLB 是四路组相联的,总共有 16 个条目。
- L1 d-cache 是物理寻址、直接映射的,行大小为 4 字节,而总共有 16 个组
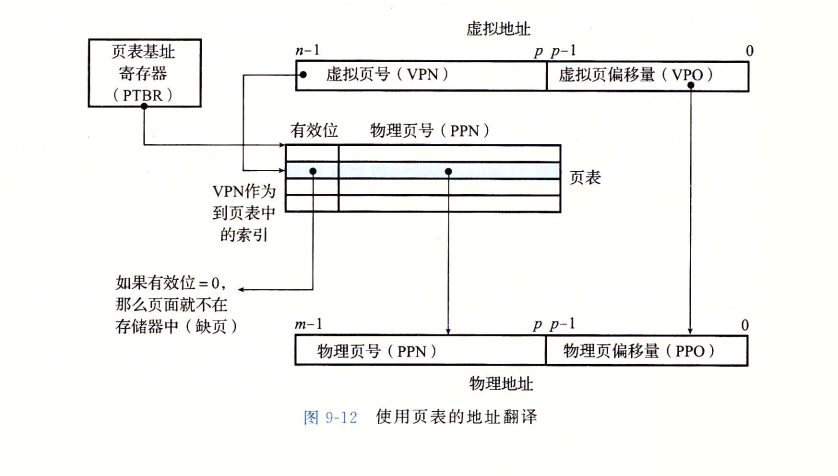
根据上面的假设,可以得到虚拟地址和物理地址的格式:
因为虚拟地址的位数是14,一个页面大小是64即\(2^6\)字节,所以页表项一共有\(2^{14}/2^6=2^8\)个,因此需要8个二进制位作为虚拟页号,据此可以进而推出物理地址的格式。下面给出当前系统的一个快照:

下面我们逐一介绍各个名词:
- TLB(快表)相当于是页表的一个高速缓存,因为页表是存储在主存上的,使用TLB能加速地址翻译。因为 TLB 有4 个组,所以 VPN 的低2位就作为组索引(TLBI)。VPN 中剩下的高 6 位作为标记(TLBT),用来区别可能映射到同一个 TLB组的不同的VPN。
- 页表,这里可能有读者会发现,这里的PTE怎么只有PPN,没有PPO,这跟前面图9-12不一样啊;其实就是没有的,因为CPU生成的虚拟地址中的VPO和PPO是一样的,所以我们只需要取出页表中的物理页号和VPO组合就可以了。
- 高速缓存缓存的是磁盘的数据,。直接映射的缓存是通过物理地址中的字段来寻址的。因为每个块都是 4字节,所以物理地址的低 2 位作为块偏移(CO)。因为有 16 组,所以接下来的 4 位就用来表示组索引CI。剩下的 6 位作为标记(CT)。
下面假设CPU给了一个虚拟地址:
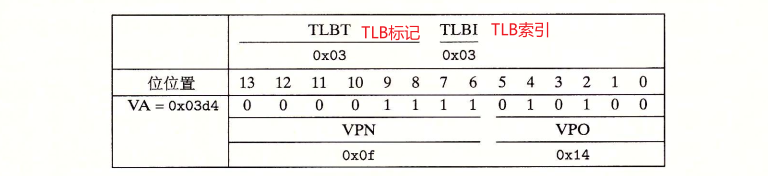
将其手动划分为VPN和VPO,MMU会根据VPN先查找TLB,先检查TLB是否缓存了PTE0x0f,这一步是根据TLBT和TLBI实现的。
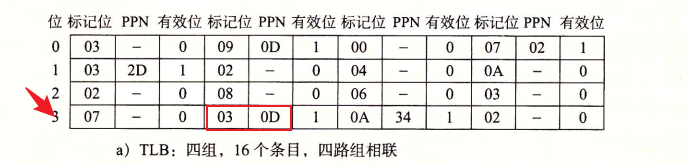 根据TLB索引定位到第三行,然后再根据TLB标记得到PPN,将PPN和VPO相加便得到了物理地址
根据TLB索引定位到第三行,然后再根据TLB标记得到PPN,将PPN和VPO相加便得到了物理地址0x354;这里如果TLB不命中的话,MMU就会去主存上的页表取出物理页号。
接下来,MMU会把物理地址发送给缓存:

根据标记位,发现命中,然后根据缓存偏移CO把数据0x36取出返回给CPU。

这里如果缓存不命中的话,就会根据物理地址去主存上取数据。
综上,我们介绍了在TLB命中,缓存命中时的地址翻译过程。
二、内存映射
内存映射(Memory Mapping)是操作系统提供的一种机制,允许进程将磁盘上的文件或匿名内存映射到它的虚拟地址空间。这个功能通常通过系统调用如mmap在类Unix系统中实现。
一个对象可以被映射到虚拟内存上,要么作为共享对象,要么作为私有对象,例如,每个C程序都需要来自标准C库的printf这样的函数,但如果每个对象都保留一个这样的副本,岂不是太浪费空间了,因此根据下图的内存映射可以节省空间:
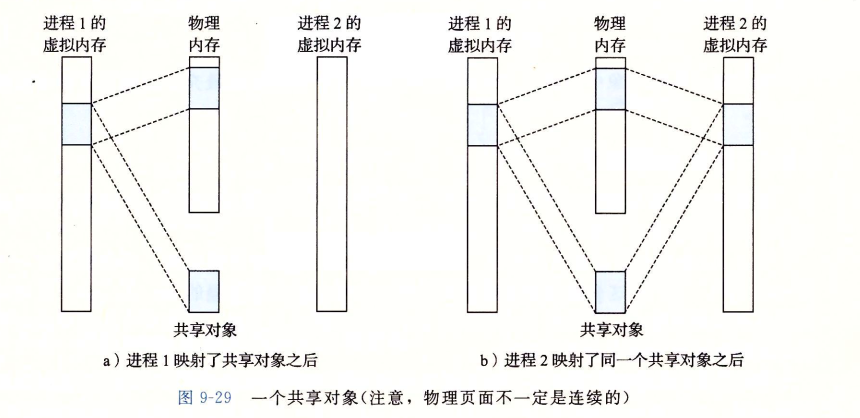
写时复制概念
写时复制(Copy-On-Write,COW)是一种资源管理技术,常用于操作系统中进行进程创建(如fork系统调用)和内存页管理。它的巧妙之处在于优化性能和内存使用,通过延迟复制直到真正需要时才进行,以此来减少不必要的资源消耗。
COW的核心思想是当多个进程或多个内存页需要相同的数据时,它们初始时共享同一份数据副本而不是直接创建多个拷贝。这份数据保持不变,直到某个进程试图修改它。在修改发生的那一刻,操作系统才会创建一份数据的真实拷贝给那个进程,而其他进程仍然指向原始数据。
再看fork函数
当fork()函数在一个进程中调用,它创建一个新进程,这个新进程拥有与原进程(父进程)相同的虚拟内存布局。这是通过复制原进程的虚拟内存结构实现的,包括内存管理结构(如mm struct)、区域结构和页表。然而,这种复制是浅层的,意味着新创建的进程(子进程)并不立即获得物理内存页面的新副本。相反,这两个进程共享相同的物理页面,这些页面被标记为只读。
关键点在于,每个页面都被设置为"写时复制"(Copy-On-Write, COW)。这意味着,只要这些共享页面是被读取的,两个进程可以安全地共享它们。但一旦任一进程尝试修改其中的任何一个页面,操作系统的内存管理机制会介入,为该进程创建该页面的一个新的、物理上独立的副本。这个新页面随后会被标记为可写,并且是该进程的私有属性。
通过这种方式,fork()实现了对虚拟内存的高效复制,同时保持了每个进程对其虚拟地址空间的完全控制。这样的设计保证了虚拟内存的抽象概念不会被破坏,即使在进程复制的情况下。每个进程都感觉它拥有自己的独立地址空间,即使在物理层面上,很多内存页面在一开始是共享的。
三、动态内存分配
为什么使用动态内存分配?
对应本博客第一张图的堆区域,动态内存一般是程序员在编程时自己定义的,使用动态内存分配的最重要原因是程序真正运行时才知道某些数据结构的大小。
比如这段代码:
#include <stdio.h>
int main(){
int *array, i, n;
scanf("%d", &n);
array = (int *)Malloc(n*sizeof(int));
for(i = 0; i < n; i++)
scanf("%d", &array[i]);
free(array);
return 0;
}
比如这段代码,在代码运行之前并不知道array数组的大小,如果把array设置为固定的大小,则很有可能导致空间的浪费,或者溢出。
隐式动态链表
分配器将堆视为一组不同大小的块的集合。
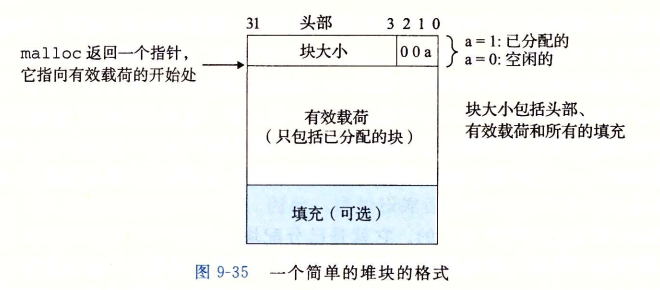
头部编码了这个块的大小,以及这个块是已经被分配还是空闲的;载荷则是块中的有效内容,比如一个整数数组;填充则是为了保证地址的对齐。
定义
隐式空闲链表(Implicit Free List)是一种在堆内存管理中使用的数据结构,用于跟踪堆中的空闲(未分配)内存块。它是动态内存分配算法的一个组成部分,通常用于实现如malloc和free这样的函数。
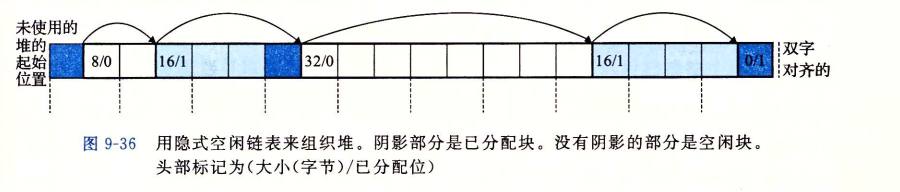
在隐式空闲链表中,堆被视为一系列的块(blocks),每个块要么是已分配的,要么是空闲的。每个块通常包含一些管理信息(如块的大小和分配状态),以及实际的数据区域。这些块在物理上连续排列在堆内存中。
隐式空闲链表的特点是:
- 空闲块的发现:为了找到空闲块,内存分配器必须遍历堆中的块,从头到尾检查每个块的分配状态。这通常是通过读取块的头部信息来完成的,头部信息会指示块的大小和是否被分配。
- 链表的隐式性:与显式链表不同,隐式空闲链表中的块并不包含指向下一个空闲块的指针。相反,分配器通过读取每个块的头部信息来决定哪些块是空闲的,并找到下一个块的位置。
- 内存利用和碎片:虽然隐式空闲链表简化了空闲内存块的管理,但它可能导致效率低下和内存碎片问题。查找合适的空闲块(尤其是在堆较大时)可能需要遍历整个堆,这会降低分配和释放内存的效率。同时,由于块的大小固定,可能导致内部碎片。
总的来说,隐式空闲链表提供了一种相对简单的方式来管理堆内存中的空闲块,但可能在性能和内存利用率方面存在一些折衷。为了改善这些问题,可以使用更复杂的内存管理策略,如显式空闲链表、分离适配(segregated fit)或伙伴系统(buddy system)。
释放空闲块
当分配器释放一个已分配块的时候,可能有其他空闲块与这个新释放的空闲块,这个时候就要考虑合并这两个空闲块,不然可能会导致“假碎片现象”。
对于隐式链表来说,可以很方便的访问到下一个空闲块的内容,当前块被释放之后,再检查下一个块,如果他也是空闲的,就采取立即合并的方式;但是这种方式并不一定适用于所有的情况。
如何合并上一个块?
按照隐式链表的定义,当前块是无法访问到上一个块的信息的,如何上一个块也空闲了,怎么合并呢?第一个思路是在每个块后面添加一个脚部,由于每个脚部的大小是固定的,所以当前块可以根据地址验算得到上一个块的信息。
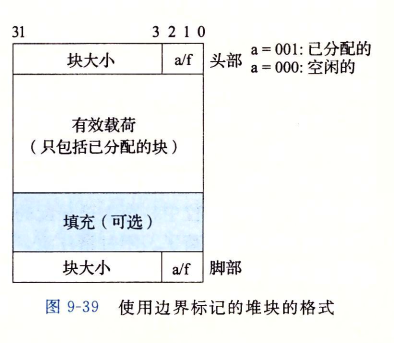
显式空闲链表
显式空闲链表主要是为了解决隐式空闲链表分配与堆块的总数呈线性关系。一种更好的方法是将空闲块组织成某种数据结构,方便查找。
第一种方法是将空闲块组织成双向链表:
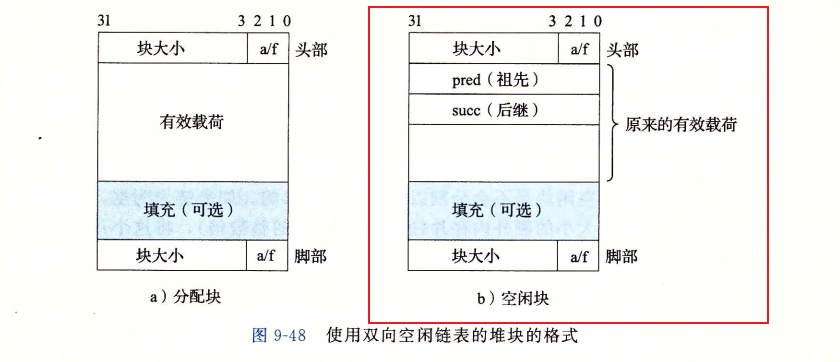
这样查找合适的空闲块的时候就可以直接根据链表结构进行查找了。
第二种方法是分离存储:
根据2的幂来划分空闲块的大小:

不过这段内容,书里介绍的比较粗略,先在这存个索引,以后用到了再深究。
四、C程序中常见的与内存有关的错误
这部分内容作者从间接引用坏指针、读未初始化的内存、允许栈缓冲区溢出 、假设指针和它们指向的对象是相同大小的 、造成错位错误引用指针,而不是它所指向的对象、误解指针运算、引用不存在的变量 、引用空闲堆块中的数据、引起内存泄漏这些方面介绍了常见的与内存有关的错误。

Q&A
- 第一节,如果主存也没有命中咋办怎么办?
地址翻译小节介绍了操作系统生成一个虚拟地址A,然后根据这个地址先检查TLB,如果没有再去检查主存的页表,如果页表也没有命中的话,就会触发一个缺页异常。随后这个异常导致控制从程序转到内核的缺页处理程序,处理程序首先检查这次访问是不是合法的,比如虚拟地址A是不是合法的,试图访问内存区域是不是合法的。如果合法的话,就会选择一个牺牲页,如果这个页面被修改过,就把这个页的内容写回磁盘,并将新的页面换入主存,并更新页表。执行完这些步骤,缺页处理程序返回,这时候程序就可以正常翻译虚拟地址A,从而不会 产生缺页中断了。
- 虚拟地址有啥用,感觉直接让CPU生成一个物理地址,然后访问主存看着也挺好的?
虚拟地址在现代计算机系统中有着非常重要的作用,其优势主要体现在以下几个方面:
- 内存保护与隔离:每个进程拥有自己的虚拟地址空间,这意味着一个进程不能直接访问或修改另一个进程的内存。这种隔离提供了更强的安全性和稳定性,因为一个程序的错误不会直接影响到其他程序的运行。
- 简化内存管理:虚拟内存使得每个进程看起来都有一个连续的、完整的内存空间,即使物理内存是碎片化的。这大大简化了程序的内存管理,因为程序员不需要关心物理内存的分布情况。
- 更有效的内存利用:虚拟内存允许操作系统进行更为灵活的内存管理,如页面置换(将不常用的内存页面移到磁盘上)和懒加载(只在需要时加载内存页面)。这样可以让系统更高效地利用有限的物理内存资源。
- 支持大型应用程序:使用虚拟内存,系统可以为应用程序提供远大于实际物理内存的地址空间。这使得可以运行大型应用程序,即使它们的内存需求超过了物理内存的容量。
- 简化多任务处理:在多任务操作系统中,虚拟内存允许每个进程操作在自己的独立地址空间内,从而简化了上下文切换的过程。
直接使用物理地址的主要问题是,它不支持上述提到的特性,如内存保护、灵活的内存管理和简化的多任务处理。此外,物理内存的直接使用在现代多任务和大型应用程序的环境下会导致管理上的复杂性和安全风险。因此,虚拟地址在现代计算机系统中被广泛采用。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/17958267

 浙公网安备 33010602011771号
浙公网安备 33010602011771号