ORB算法介绍 Introduction to ORB (Oriented FAST and Rotated BRIEF)
Introduction to ORB (Oriented FAST and Rotated BRIEF)
1. Introduction
ORB(Oriented FAST and Rotated BRIEF)是一种广泛应用于计算机视觉领域的特征描述算法。它结合了FAST角点检测算法和BRIEF描述子算法,以实现高效且具有旋转不变性的特征提取和匹配。
ORB算法的主要特点如下:
- 旋转不变性,通过在FAST角点检测的基础上引入方向信息来实现旋转不变性,这意味着即使图像发生旋转,提取的ORB特征仍能保持一致;
- 使用二进制BRIEF描述子来表示特征,这种描述子的优点在于它们具有紧凑的表示形式,便于计算和匹配,并且对光照变化和噪声有一定的鲁棒性;
- 设计时注重了快速性能,它使用了FAST角点检测算法的快速特性,并且使用二进制BRIEF描述子进行特征描述,从而提高了特征提取和匹配的速度。
- ORB算法的快速性能和良好的鲁棒性,它在实时应用中得到广泛使用。例如,它可以用于实时跟踪、姿态估计、立体视觉等。
- 算法的开源实现可在OpenCV等计算机视觉库中找到,使其易于使用和集成到各种项目中。
当涉及到计算机视觉和图像处理任务时,特征匹配是一项重要的技术。特征匹配是指在不同图像或图像中的不同位置之间寻找相对应特征的过程。这些特征可以是图像中的显著点、边缘、角点或者其他具有区别性的局部结构。
特征匹配是许多计算机视觉问题的基础,例如物体识别、图像配准、图像检索、增强现实。在本文中,我们提出了一种基于BRIEF的非常快速的二进制描述符,称为ORB,它具有旋转不变性和抗噪性。通过实验证明,ORB的速度比SIFT快两个数量级,并且同时在许多情况下表现出色。
2. oFAST: FAST Keypoint Orientation
2.1 Fast
FAST特征点提取算法的主要思想是通过对像素值的快速比较来检测图像中的显著角点。该算法通过对每个像素周围的16个邻域像素进行强度比较来判断该像素是否是角点。具体的步骤如下:

- 选择一个像素点作为候选角点,并获取该像素的灰度值。
- 选择一个适当的阈值T。
- 给定一个半径r,假设r=3,这样我们便得到了圆上的16个邻域像素,检查这些像素,如果存在连续的n个像素与候选像素的灰度值差小于T或大于T,则将该像素标记为非角点。
- 如果某个像素被标记为非角点,则将候选像素标记为非角点。
- 如果某个像素的16个邻域像素中有n个像素与候选像素的灰度值差大于T,则将该像素标记为角点。
- 对图像中的每个像素重复上述步骤,直到遍历完整个图像。
FAST算法的优点是速度快,适用于实时的应用场景。它可以在图像中快速检测到大量的角点。然而,由于FAST算法主要是通过阈值比较来判断角点,所以对于存在边缘的地方可能会有较多的误检。
2.2 oFast
2.2.1 Scale invariance
然而,FAST特征并没有方向性和多尺度特征。因此,ORB算法使用了多尺度图像金字塔。图像金字塔是单个图像的多尺度表示,由一系列图像组成,这些图像都是以不同分辨率的图像版本。金字塔中的每个级别都包含比前一个级别更低分辨率的图像。一旦ORB创建了金字塔,它就使用快速算法在图像中检测关键点。通过在每个级别检测关键点,ORB有效地在不同尺度上定位关键点。这样,ORB在某种程度上具有尺度不变性。
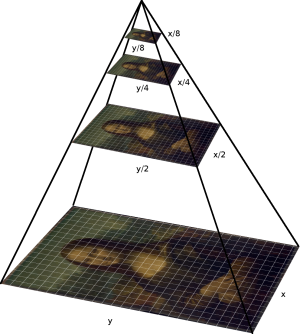
2.2.2 Rotation invariance
在定位关键点后,ORB现在为每个关键点分配一个方向,如左侧或右侧,具体取决于该关键点周围的强度变化水平。为了检测强度变化,ORB使用强度质心。在这里,ORB假设了强度质心和中心位置有偏移,这个向量可以用来推断一个方向。
作者将一个图像块的矩定义为:
通过这些矩可以找到图像的质心:
然后构造了一个从图像中心 \(O\)到质心的 \(\overrightarrow{O C}\)变量,然后由下面这个式子给出图像块的方向:
当我们定义了特征点的方向之后,我们便可以把这个信息加入到特征点的描述符中,来使得特征点具有一定的旋转不变性。
3. rBRIEF: Rotation-Aware BRIEF
3.1 BRIEF
RIEF在2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述,采用二级制的位异或运算,大大的加快了特征描述符建立的速度,同时也极大的降低了特征匹配的时间,是一种非常快速,很有潜力的算法。
如果说FAST用来解决寻找特征点的速度问题,那么BRIEF就用来解决描述子的空间占用冗余问题。
BRIEF描述的子的计算流程:
-
使用高斯核对图像进行平滑处理,以防止描述符对高频噪声过于敏感。
-
在关键点周围的定义邻域内随机选择一对像素。该定义邻域被称为\(p\),它是一个围绕特征点的像素正方形区域。
-
然后我们在这个patch里面按照一定的策略(这个策略很重要,后面还会提起)选取256个像素对。
-
如果第一个像素比第二个像素灰度值高,则将相应的位赋值为 1,否则为 0,也就是binary test。我们选取256个像素点对,就得到了一个256位的BRIEF描述子。
二进制测试:
\[ \tau(\mathbf{p} ; \mathbf{x}, \mathbf{y}):= \begin{cases}1 & : \mathbf{p}(\mathbf{x})<\mathbf{p}(\mathbf{y}) \\ 0 & : \mathbf{p}(\mathbf{x}) \geq \mathbf{p}(\mathbf{y})\end{cases} \]\(p(x)\)代表x点的像素灰度值,特征描述子定义为n个二进制测试:
\[f_n(\mathbf{p}):=\sum_{1 \leq i \leq n} 2^{i-1} \tau\left(\mathbf{p} ; \mathbf{x}_i, \mathbf{y}_i\right) \]
3.2 steered BRIEF
为了使得BRIEF描述子具有一定的旋转不变性,我们通过下面的方法将Fast关键点计算出的的方向信息\(\theta\)加入到BRIEF描述子中。对于n个二进制测试对应的点对集合,我们定义一个\(2 *n\) 的矩阵:
利用Fast计算出的\(\theta\)定义一个旋转矩阵\(R_{\theta}\):
最终BRIEF描述子定义为:
作者将上面的方法定义为 steered BEIEF。
然而,使用steeredBRIEF方法得到的特征描述子具有旋转不变性,但是却在另外一个性质上不如原始的BRIEF算法。是什么性质呢,是描述符的可区分性。这个性质对特征匹配的好坏影响非常大。描述子是特征点性质的描述。描述子表达了特征点不同于其他特征点的区别。我们计算的描述子要尽量的表达特征点的独特性。如果不同特征点的描述子的可区分性比较差,匹配时不容易找到对应的匹配点,引起误匹配。
作者对100k的特征点计算其描述符,对这些描述符进行统计,得到这样一张图:
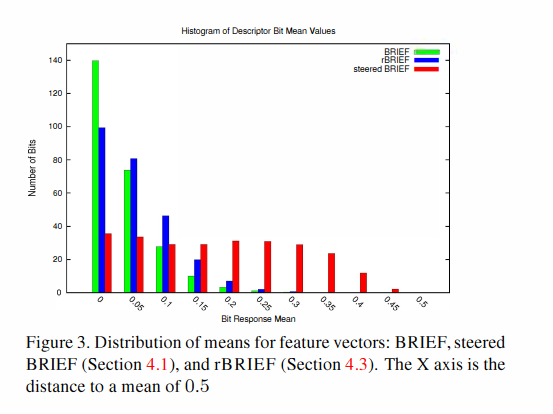
横轴表示每个描述符的均值距离 0.5 的距离,纵轴表示相应均值下描述符的个数
对于一串01向量,我们知道,其均值越是接近0.5,则表明这串向量的方差越大,方差又表明了数据的离散程度,描述符具有越高的方差,则代表其表征性越好。
先不看rBRIEF方法,我们发现,接近0.5均值的描述符个数中,BRIEF的数量远远高于steered BRIEF,可去分析更强,而steered BRIEF失去了这个特性。
3.3 rBRIEF
下面我们介绍解决上面这个问题的方法:rBRIEF。
前面我们在3.1BRIEF 小节提到过,“我们是按照一定的策略选取像素点对来构建描述子的”。 作者的思路就是构造一种更好的选取策略,把那些均值更加接近0.5的描述子选取出来,使得得到的描述子更加具有表征性。
下面我们介绍一下rBRIEF算法:
首先作者从PASCAL上得到了300k的Fast keypoints,把他们定义为training set。
我们知道,对于一个\(31 \times 31\)的Patch,如果定义一个\(5 \times 5\)的sub_window,那么我们可以在这个Patch上得到\(N= (31 -5)^2\)个sub_windows。我们计算每个sub_windows的灰度值,那么就可以到的\((^N_2)\)个Binary tests。去掉其中一些重叠的那么可以最终可以得到\(M=205590\)个可能得Binary tests。
最终算法的描述如下:
-
对training set进行所有的M个Binary tests,这样我们会得到一个\(300k \times M\)的矩阵\(Q\)
-
对于每个tests,求其平均值,按照距离0.5的距离从小到大排序,把新的矩阵叫做T。(对应到矩阵上就是按照\(Q\)的列向量的均值升序排列)
-
贪婪搜索
a. 定义空矩阵R,把第一个Binary test结果放到R中,然后再从T中删除
b.把T中下一个Binary test结果取出,计算其与R中所有的Binary tests的相关性,如果相关性小于某个阈值,则把它放到R中;否则丢弃。
c.重复上一个过程,直到R中有256个Binary tests。如果最终小于256,则提升阈值,再次运行。
这个算法其实不是很好理解。大体思想就是通过这个策略选取出M个Binary tests中表征性最好的,同时彼此之间相关性最小的。
之后这256个Binary test,就可以在ORB中使用了。
4. Evaluation
4.1 ORB vs SIFT
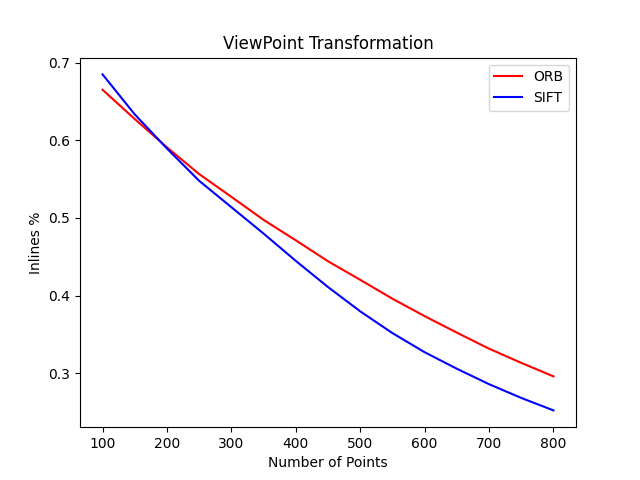
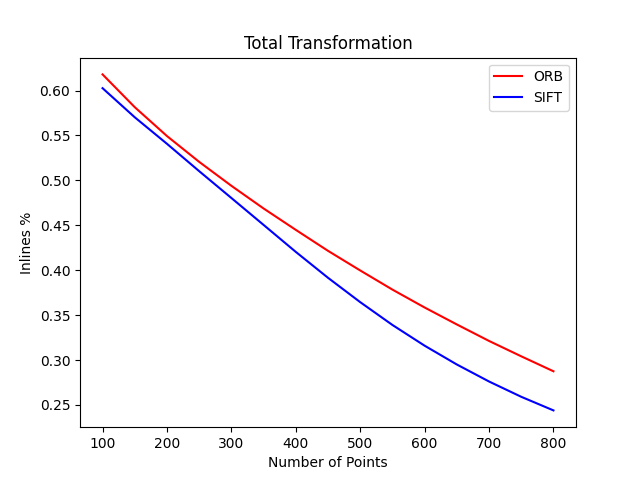
我选用了Hpatches数据集,这个数据集里主要包括光照变换,视角变换,以及一些常见的变换,来对比SIFT和ORB的内点率。
对于一个图片对,计算方法如下:
-
分别使用SIFT,ORB提取800个特征点,进行特征匹配
-
将特征匹配结果按照距离升序排列
-
选取前N=100个点,利用H矩阵(Ground Truth)计算内点率
-
N=N+50,然后再执行第三步计算内点率。
最后计算所有图片的内点率。
 |
 |
 |
|---|
| Detector | SIFT | ORB |
|---|---|---|
| Time per frame(s) | 0.09 | 0.01 |
结果是有些出人意料的,ORB的速度更快,而且内点率也更高,也符合论文里的结果:
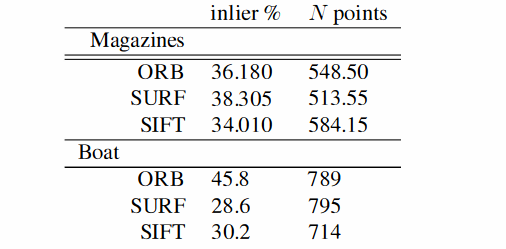
4.2 Visualization
| SIFT | ORB |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
5. Summary
读完ORB的论文,最直接的感受是深度学习之前的论文,相对来说阅读成本要高很多,因为涉及了很多的算法,基础概念等等。
首先是了解了高斯差分金字塔,图像质心,图像的矩等概念;其次作者对BRIFE的改进也令人印象深刻,也许一开始只是发明了steered BRIEF,按理来说此时的描述子拥有了一定的旋转不变性,效果应该更好才对,可是作者发现效果反而更差了,作者并没有气馁,进而通过PCA和统计方差去分析描述子的质量,这一点我觉得是令人钦佩的,最后根据分析的结果,去把那些表征性最强,相关性最小的Binary test选取出来,也就得到了最后的结果rBRIEF。“也许如何看待失败,将我们分向了不同的路”;最后的实验结果也是令人有些意料之外的,ORB论文里实验证明自己比SIFT效果好,一开始我是不信的,直到我自己跑完了实验,才确信,以后涉及到使用特征匹配的任务,也会使用一下ORB算法尝试一下。
6. Refer
[ORB]https://ieeexplore.ieee.org/abstract/document/6126544
[Hpatches]https://github.com/hpatches/hpatches-dataset
[lowkeyway]https://zhuanlan.zhihu.com/p/91479558
[New-Time]https://blog.csdn.net/haoliliang88/article/details/51841131
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/17533944.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号