视觉SLAM十四讲——有关相机运动的汇报
视觉SLAM十四讲——有关相机运动的汇报
大概用了一个月的时间看完slam十四讲,里面很多内容算是填坑了很多以前遇到的不懂的点,并且脑海里也大致有了一个关于SLAM的框架,现在就这篇文章将其中相机运动估计的部分进行一个介绍。

SLAM是什么?
SLAM的英语全称是Simultaneours Localization and Mapping,中文译作“同时定位与地图构建”。
它是指搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建立环境的模型,同时估计自己的运动。如果这里的传感器主要为相机,那就称为“视觉SLAM"。
下面我们看一个视频:
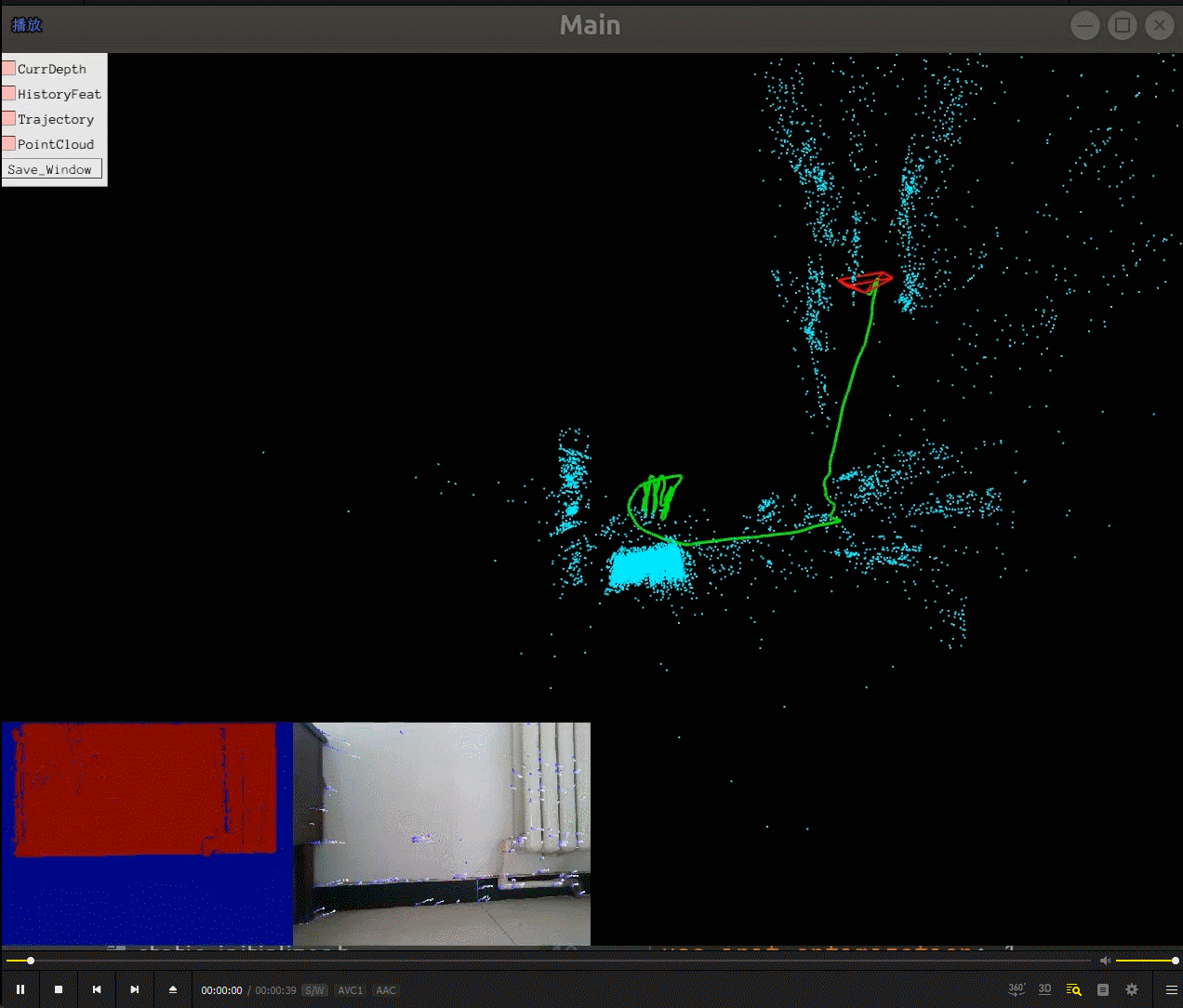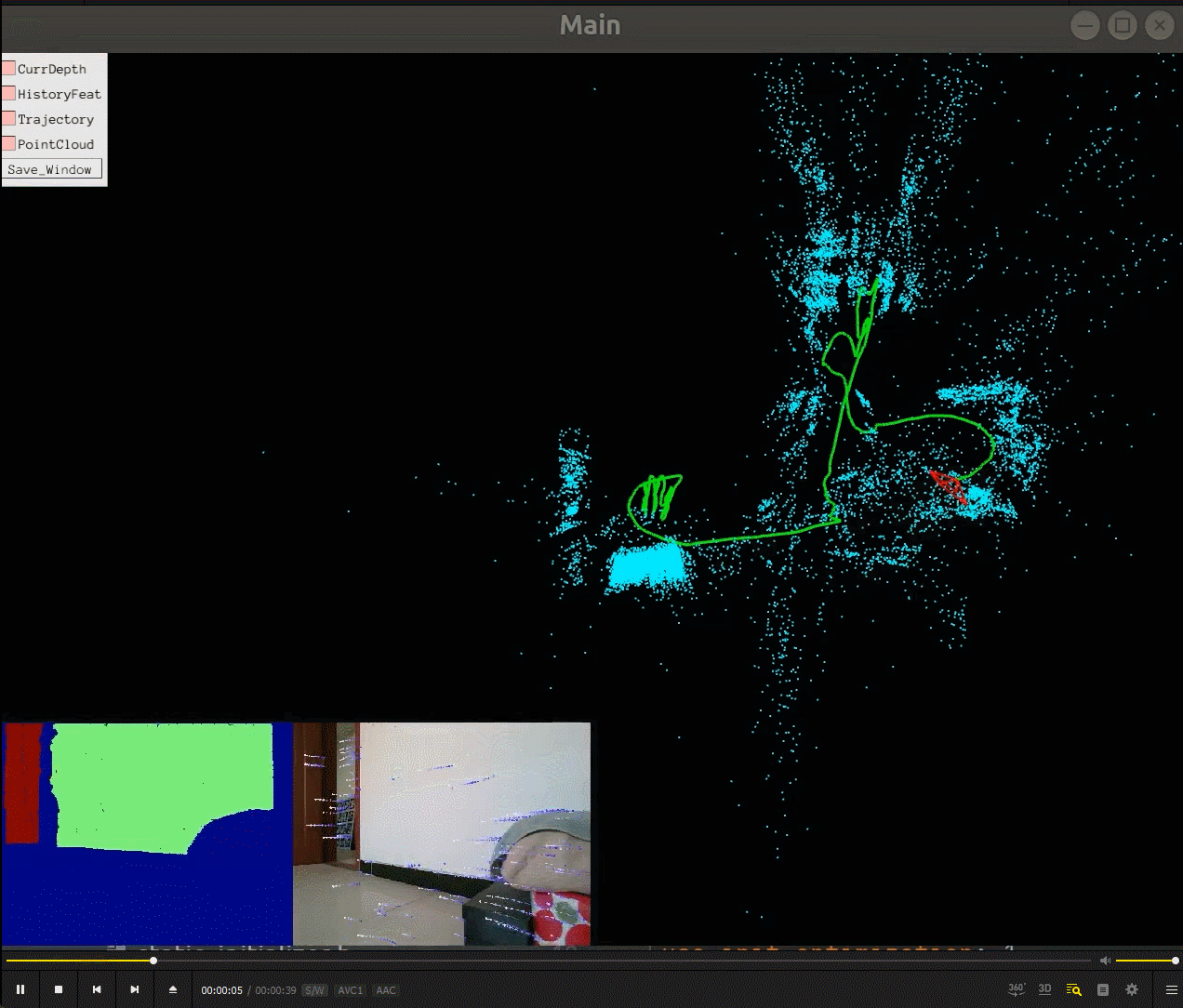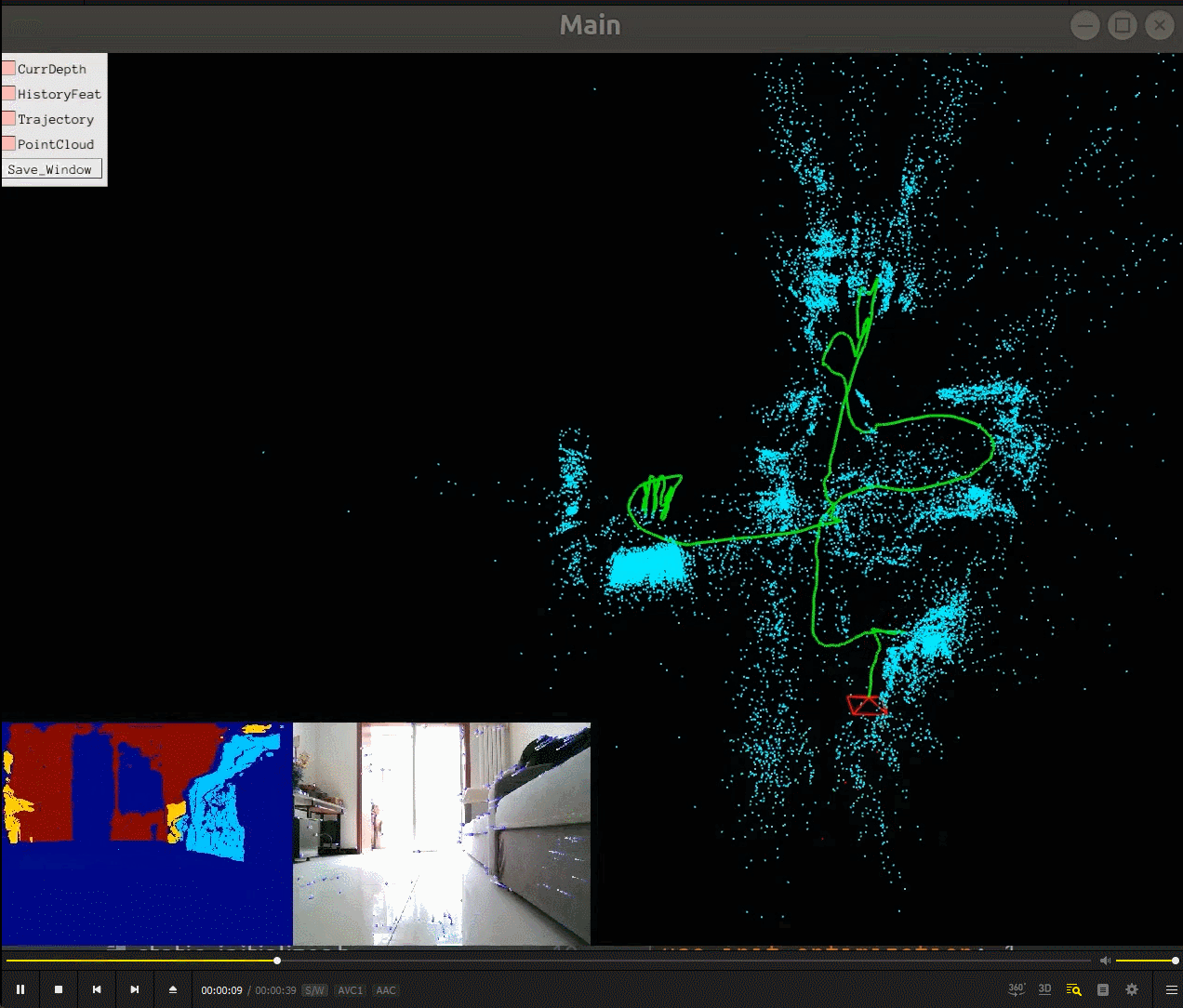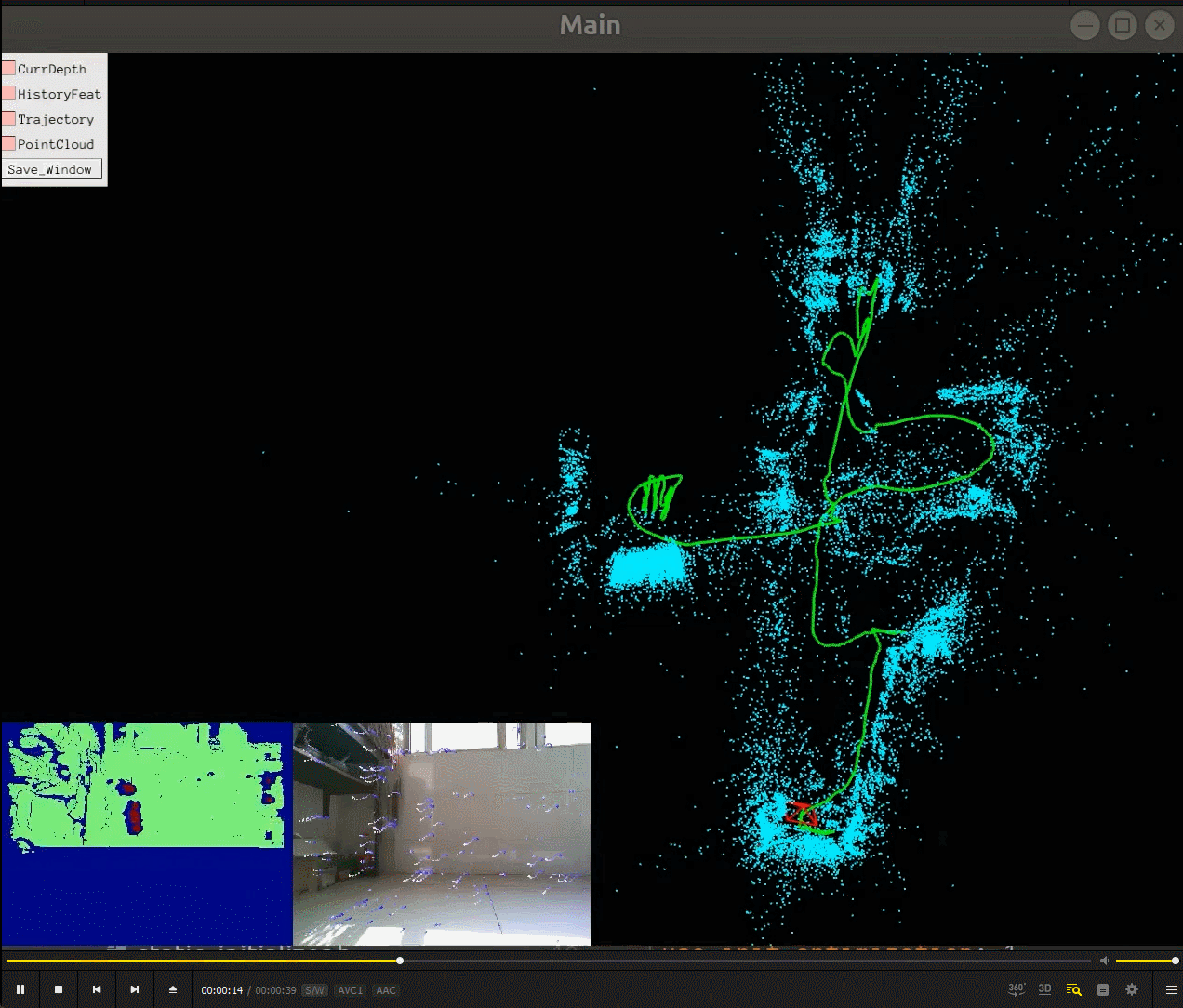
我们可以看到相机一边在环境中运动(绿色的轨迹),一边重建了场景的稀疏地图(蓝色的点),相机的运动估计还有场景的稀疏地图建立是同时进行的,所以SLAM(同时定位与建图)名字由此而来。
1. 先验知识
为了更好地去介绍相机运动的估计,需要先补充几个先验知识,这些先验知识是视觉方向的一些必备知识,即使您的研究方向不是SLAM,这一节的内容也是通用的。
1.1 特征点匹配
我们可以简单地把图像中特征点理解为“图像里一些特别的地方”。

这些特征点是不会因为相机的运动轻易产生变化的,所以不同位置的相机拍摄出来的图像,他们的特征点能够进行一个匹配。

图像特征点的提取算法有很多,传统方法有SIFT,ORB,FAST等等,现在也有好多基于深度学习的方法SuperPoint,GIFT。
具体的实现我们先暂不展开,感兴趣的读者可以去查询有关图像特征点匹配的内容。现在们只需要知道我们可以在不同的图像上提取特征点,并且对他们进行一个匹配即可。
1.2 最优化理论
1.2.1 最小二乘问题
最小二乘法是由勒让德在 19 世纪发现的,形式如下式:
观测值就是我们的多组样本,理论值就是我们的假设拟合函数。目标函数也就是在机器学习中常说的损失函数,我们的目标是得到使目标函数最小化时候的拟合函数的模型。
我们看一个最简单的最小二乘问题:
\(f(x)\)指残差,即观测值与理论值的差,\(F(x)\)称为损失函数(或代价函数,cost function),根据模型的不同有线性模型和非线性模型,分为线性最小二乘和非线性最小二乘。
我们希望找到一个\(x\),使其代入\(F(x)\)这个函数时,\(F(x)\)取得最小值。
下面我们讨论一下怎么求解这个问题,
首先我们很容易想到求\(F(x)\)的导数,然后令导数等于0,然后求解\(x\)。
这样我们就求解出导数为0处的极值,它们可能是极大、极小或鞍点处的值,这时只要逐个代入\(F(x)\)比较就可以了。
但是有些情况方程(2)可能不好求解(导函数比较复杂),这个时候我们考虑使用迭代的方式。
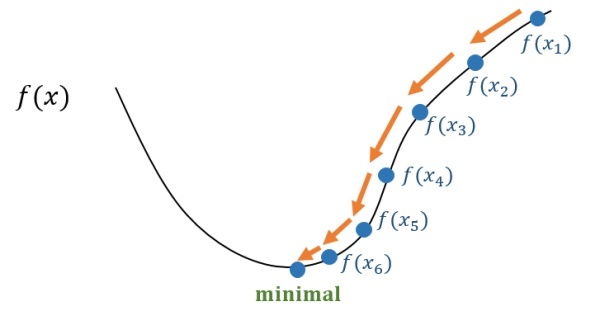
现在我们就高斯牛顿法讨论一下问题(1)的解法:
对于第k次迭代,我们将\(f(x)\)在x处进行一阶泰勒展开:
其中\(J(x)^T\)的导数是\(f(x)\)关于x的导数,此时公式(3)表示的是对\(f(x)\)在\(x_k\)处的一个线性近似。所以原问题变为了寻找一个\(\Delta x\),使得\(||f(x_k)+J(x_k)^T \Delta x||^2\)达到最小。
我们将上述函数对\(\Delta x\)求导,并令导数为0。
先展开目标函数的平方项:
求上式关于\(\Delta x\)求导,并令导数为0:
可以得到如下方程组:
因此,高斯牛顿法的算法步骤可以写作:
- 给定初始值\(x_0\)
- 对于第k次迭代,求出当前的雅克比矩阵\(J(x_k)\)和误差\(f(x_k)\)
- 求解增量方程: \(H \Delta x = g\)
- 如\(\Delta x\)足够小,则停止;否则,令\(x_{k+1} = x_k + \Delta x_k\),返回第二步。
说一下我的理解,其实观察高斯牛顿法的算法流程,我们可以发现其思想是把一个非线性函数在某个区域内用一个线性函数近似,然后求解这个线性函数的最小值,获得一个增量,并不断迭代。这样的话就不难看出,高斯牛顿法的迭代速度是非常快的,但是很容易走出锯齿路线。

所以实际中我们往往设置一个步长,使得\(x_{k+1} = x_k + \alpha \Delta x\),还有使用更为严谨一些的列文伯格-马夸尔特方法将更新控制在一个信赖域的范围内。但尽管高斯牛顿法有一些缺点,它依然是非线性优化方面一种简单有效的方法。
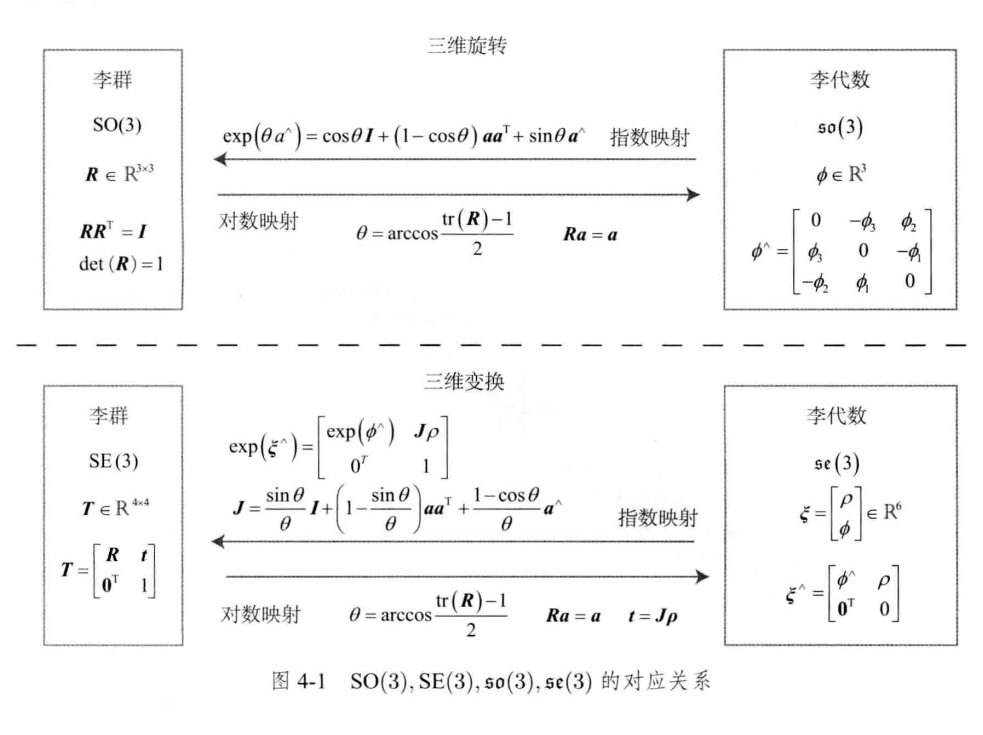
1.3 李群与李代数
不知道大家读论文的时候有没有经常遇到这几个符号\(SE(3), \mathfrak{s e}(3),SO(3),\mathfrak{s o}(3), \phi ,ξ\)
 |
 |
 |
... |
|---|---|---|---|
 |
 |
 |
... |
读完本小节,我们会对这些符号有一个较为全面的认识。
1.3.1 群与李群
群是一种集合加上一种运算的代数结构。我们把集合记作A,把运算记作\(\cdot\),那么一个群可以记作\(\mathbf{G}=(\mathbf{A},\ \cdot)\)。群要求这个运算满足以下几个条件:
- 封闭性:
\[\forall a_1, a_2 \in A, \quad a_1 \cdot a_2 \in A \]
- 结合率:
\[\forall a_1, a_2, a_3 \in A, \quad\left(a_1 \cdot a_2\right) \cdot a_3=a_1 \cdot\left(a_2 \cdot a_3\right) \]
元:
\[\exists a_{0} \in A , s.t. \forall a \in A, \quad a_{0} \cdot a=a \cdot a_{0}=a . \\ \]逆:
\[\forall a \in A, \quad \exists a^{-1} \in A, \text { s.t. } \quad a \cdot a^{-1}=a_0 . \]
那么定义三维旋转矩阵组成的特殊正交群\(SO(3)\),以及三维变换矩阵组成的特殊欧式群\(SE(3)\) ,并且是关于乘法成群,不关于加法成群。
我们可以看到,旋转矩阵存在两个约束$ \boldsymbol{R} \boldsymbol{R}^{T}=\boldsymbol{I}, \operatorname{det}(\boldsymbol{R})=1$。
那么进一步想,什么是李群呢?
李群是指具有连续(光滑)性质的群。像是整数群就是离散的,所以不是李群。然而对于\(SO(3)\),\(SE(3)\)在实数空间上是连续的,我们可以想出一个三维物体在空间中运动的过程,是连续的,所以\(SO(3)\),\(SE(3)\)是李群。不过严谨来说,对于“连续”的定义,有会引出一系列数学推导。我们可以先这样认识一下李群。
1.3.2 李代数的引出
我们先看一下这个函数:
对于三维世界世界坐标系下的一个点\(P\),其投影的像素坐标是\(u\)。我们将点\(P\)乘以一个变换矩阵\(T\),把他变到相机坐标系\(TP\),然后再乘以相机内参内参\(K\),再除以这个点的深度值,就得到了点\(P\)对应的像素坐标,也就是\(\frac{1}{s} \boldsymbol{K} \boldsymbol{T} \boldsymbol{P}\),然而,由于我们估计的\(T\)的不准确性,\(u\) 与 \(\frac{1}{s} \boldsymbol{K} \boldsymbol{T} \boldsymbol{P}\)会存在一个误差,这个误差也就是我们熟知的重投影误差。
然后这个函数的目标就是:我们希望通过对\(T\)的优化,来最小化重投影误差。
再然后,我们又会惊奇地发现,这不就是一个最小二乘问题吗,那么我们去求误差函数关于\(T\)的导数,再用高斯牛顿法迭代,问题不就得到完美的解决了吗?可是,当我们认真观察会发现,实际操作时会遇到诸多困难:
如果要求对\(T\)的导数,按照导数的定义,会存在$lim _{\Delta T \rightarrow 0} {(T+\Delta T )P - TP \over {\Delta T}} $ 之类的形式,这就给优化方程带来了三个约束条件:
-
\(T \in SE(3)\)
-
$\Delta T \in SE(3) $
-
$T + \Delta T \in SE(3) $
再结合\(SO(3)\)的两个约束,正交阵,行列式值为1。这会给优化带来巨大的困难。
那么有没有一种方式,能够使得优化绕开这些约束,快乐地迭代呢?有的,答案是李代数。
每个李群都有与之对应的李代数。李代数描述了李群的局部性质。 李代数由一个集合 \(V\),一个数域 \(F\) 和一个二元运算 \([,]\) , 组成。如果它们满足以下几条性质,则称$ (V, F,[],)$ 为一个李代数,记作 \(g\) 。
- 封闭性: \(\forall \mathbf{X}, \mathbf{Y} \in V,[\mathbf{X}, \mathbf{Y}] \in V\).
- 双线性: \(\forall \mathbf{X}, \mathbf{Y}, \mathbf{Z} \in V, a, b \in F\) ,有 \([a \mathbf{X}+b \mathbf{Y}, \mathbf{Z}]=a[\mathbf{X}, \mathbf{Z}]+[\mathbf{Y}, \mathbf{Z}],[\mathbf{Z}, a \mathbf{X}+b \mathbf{Y}]=a[\mathbf{Z}, \mathbf{X}]+b[\mathbf{Z}, \mathbf{Y}]\)
- 自反性: \(\forall \mathbf{X} \in V,[\mathbf{X}, \mathbf{X}]=\mathbf{0}\).
- 雅可比等价: \(\forall \mathbf{X}, \mathbf{Y}, \mathbf{Z} \in V,[\mathbf{X},[\mathbf{Y}, \mathbf{Z}]]+[\mathbf{Z},[\mathbf{X}, \mathbf{Y}]]+[\mathbf{Y},[\mathbf{Z}, \mathbf{X}]]=\mathbf{0}\).
简单来说,\(so(3)\)是一个三维向量的集合,其实也就是旋转向量;对应的\(se(3)\)则是由旋转向量加上一个三维的平移组成的集合,也就是一个六维的向量。
在我们把旋转角度定义在\([-\pi , \pi]\)的前提下,会有以下两个结论:
- $任意 R_0 \in SO(3), 存在唯一一个\phi_0 \in so(3)与之对应,反之亦然 $
- $任意 T_0 \in SE(3), 存在唯一一个\mathbf{\rho}_0 \in se(3)与之对应,反之亦然 $
读者还可能好奇公式(13)的其他部分的含义,推荐大家去阅读一下《视觉SLAM十四讲》第四讲。
再回到一开始的问题,我们希望通过对\(T\)的优化,来最小化重投影误差,然而T本身存在约束,我们希望把原问题构建为一个无约束的优化问题。到这里答案已经得到了:
我们可以把\(T\)转化为其对应的李代数$ \phi $,使用李代数进行优化
对应的转化公式:
对于李代数的求导思路分为两种:
-
根据李代数加法求导

-
使用扰动模型求导,分为左导数模型和右导数模型


还有右导数模型 T7:https://www.cnblogs.com/programmerwang/p/17251007.html
至此,我们介绍完了李群与李代数。
2. 相机运动的估计
下面我们正式开始相机运动估计的介绍。
2.1 视觉里程计
视觉里程计主要是估计两帧图像之间的相机运动,目前比较主流的方法有特征点法,光流法。
我们先介绍一下特征点法。
现在我们已经有了匹配好的点对,接下来,我们要根据点对估计相机的运动。这里由于相机的原理不同,情况发生了变化:
- 当相机为单目时,我们只知道2D的像素坐标,因而问题是根据两组2D点估计运动。该问题用对极几何解决。
- 当相机为双目、 RGB-D时,或者通过某种方法得到了距离信息,那么问题就是根据两组3D点估计运动。该问题通常用ICP解决。
- 如果一组为3D,一组为2D,即我们得到了一些3D点和它们在相机的投影位置,也能估计相机的运动。该问题通过PnP求解。
因此,下面几节介绍这三种情形下的相机运动估计。我们将从信息最少的2D- 2D情形出发,看看它如何求解,求解过程中又遇到哪些麻烦的问题。
2.1.1 对极几何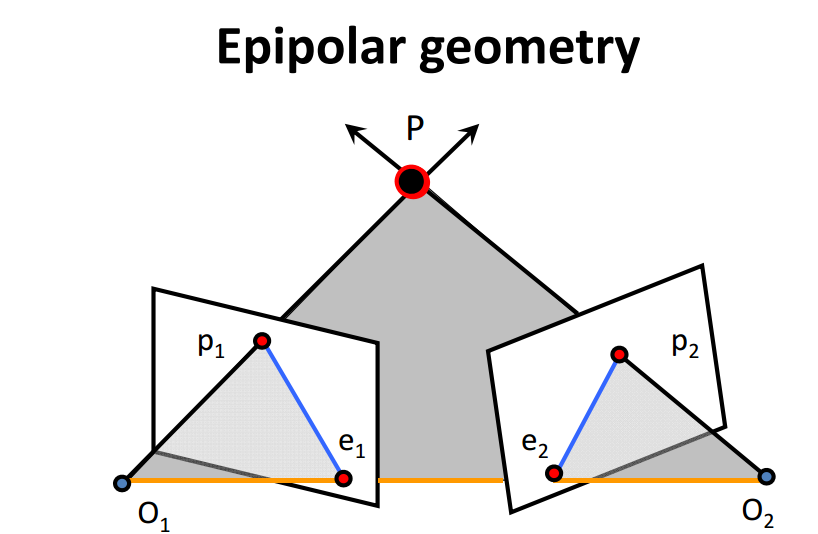
假设第一帧的相机坐标系下的一点:
根据针孔模型,其投影到两个相机像素坐标系下的像素坐标\(p_1,p_2\)分别是:
它们之间存在一个约束关系:
在这个式子中,\(R,t\)是我们要求解的变量。设\(E = t^{\wedge}R\)被称为基础矩阵,\(F = K^{-T}E K^{-1}\)被称为本质矩阵。
2.1.2 PnP
PnP描述了知道n个世界坐标系下的3D点\(P\),以及他们对应的投影像素坐标\(u\)的情况下,如何求解相机位姿的问题。
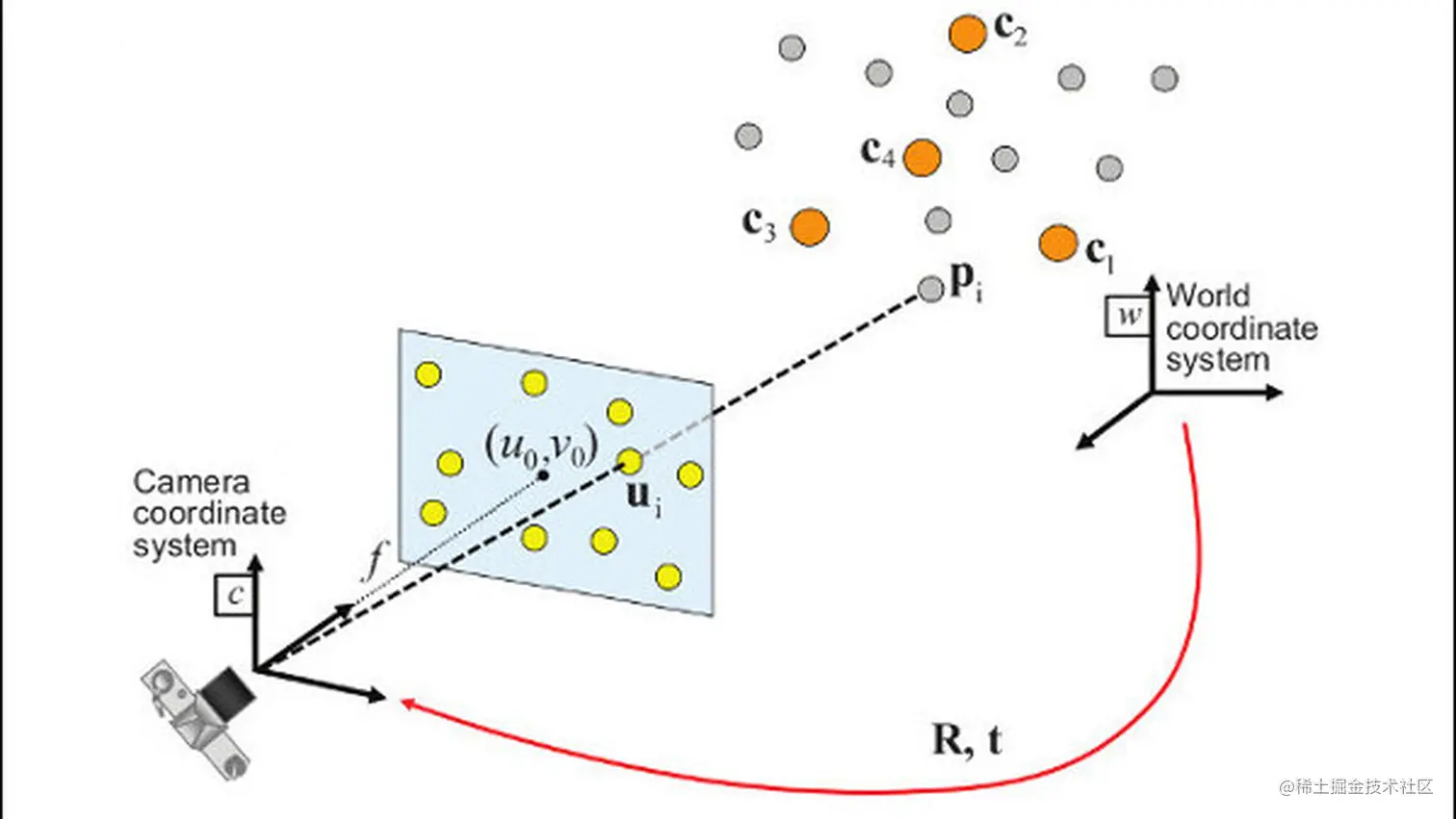
求解方法主要有P3P,DLT,EPnP等,这里我们介绍一下利用非线性优化的方法是如何求解的。
这个误差就是重投影误差,我们希望去不断地优化位姿T,使得观测值和理论值的误差减小。公式的右侧是相机模型。
2.1.3 ICP
假设我们有一组匹配好的3D点,比如利用了RGBD图像进行了匹配:
现在,需要找到一个欧氏变换 \(R, t\), 使得 :
求解方式主要有SVD方法(代数求解),同样也有非线性优化方法:
以迭代的方式去找最优值。该方法和我们前面讲 述的 \(\mathrm{PnP}\) 非常相似。以李代数表达位姿时, 目标函数可以写成
于是,在非线性优化中只需不断迭代,就能找到极小值。而且,可以证明, ICP问题存在唯一解或无穷多解的情况[2]。在唯一解的情况下, 只要能找到极小值解,这个极小值就是全局最优值一因此不会遇到局部极小而非全局最小的情况。这也意味着ICP求解可以任意选定初始值。这是已匹配点时求解ICP的一大好处。
需要说明的是,我们这里讲的ICP是指已由图像特征给定了匹配的情况下进行位姿估计的问题。在匹配已知的情况下,这个最小二乘问题实际上具有解析解[3,4,5],所以并没有必要进行迭代优化。ICP 的研究者们往往更加关心匹配未知的情况。那么,为什么我们要介绍基于优化的ICP呢?这是因为,某些场合下,例如在RGB-D SLAM中,一个像素的深度数据可能有,也可能测
量不到,所以我们可以混合着使用PnP和ICP优化:对于深度已知的特征点,建模它们的3D-3D误差;对于深度未知的特征点,则建模3D- 2D的重投影误差。于是,可以将所有的误差放在同一个问题中考虑,使得求解更加方便。
3. 后端
后端我们将主要围绕Bundle Adjustment和滑动窗口展开讨论,他们作为一个全局的位姿和三维点优化,相较于视觉里程计会看得更加长远。
未完待续~
4. Refer
[1] 视觉SLAM十四讲
[2] T. Barfoot, State estimation for robotics: A matrix lie group approach, 2016.
[3] O. D. Faugeras and M. Hebert, The representation, recognition, and locating of 3-d objects, The Intermational Jourmal of Robotics Research, vol. 5, no.3, pp. 27- -52, 1986.
[4] B. K. Horm, Closed-form solution of absolute orientation using unit quaternions, JOSA A, vol. 4, no. 4, pp.
629- 642, 1987.
[5] G. C. Sharp, S. W. Lee, and D. K. Wehe, Icp registration using invariant features, IEEE Transactions on Pattern
Analysis and Machine Intelligence, vol. 24, no. 1, pp. 90- 102, 2002.
5. Summary
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/17305420.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号