RAFT光流估计
RAFT Introduction
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow;观其名便知道这是一篇关于光流估计的论文。
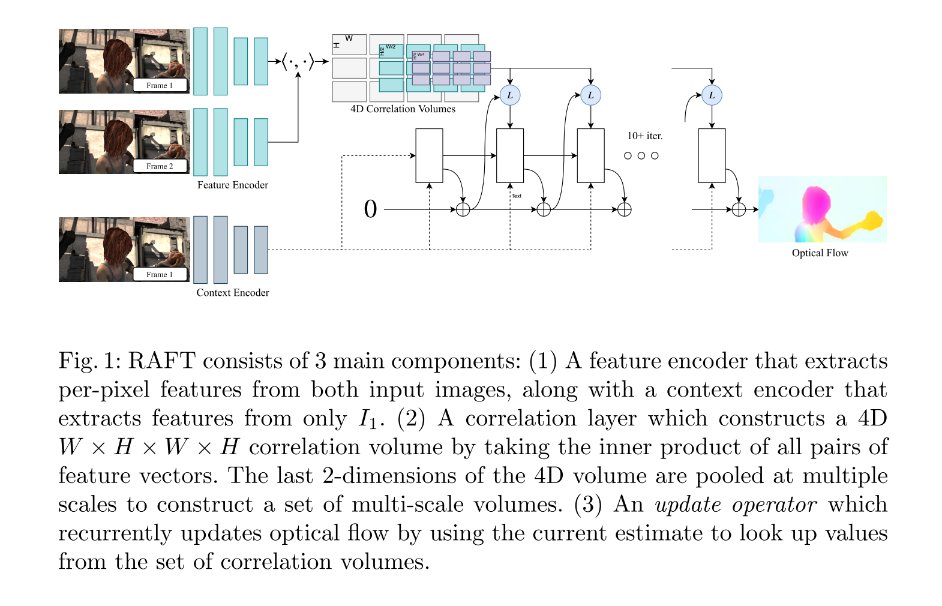
模型介绍
为了方便理解和阅读,我写了两个版本:
-
先是一个网络\(Net_1\)提取两张输入\(I_1,I_2\)的特征(左上角),还有另一个网络\(Net_2\)再提取一次\(I_1\)的特征(左下角),然后通过一个
correlation layer接收\(Net_1\)的输出并建立两张图片的相似度向量。最后作者使用了自然语言处理中GRU的思想,把相似度向量,每一次迭代预测出的光流,以及\(Net_2\)的输出三者作为输入去迭代着更新光流。 -
RAFT由三部分组成:(1)一个
feature encoder提取两张输入图片\(I_1,I_2\)在每个像素点上的特征。这里我们假设\(I_1,I_2\)的尺寸是\(H \times W\),那么经过feature encoder之后得到的特征维度就是\(H \times W \times D\);此外还有一个context encoder提取\(I_1\)的特征,也就是图片的左下角。(2)一个correlation layer负责把\(I_1,I_2\)的特征向量通过点乘的方式连接起来,那么最终输出的是一个\(H \times W \times H \times W\)的向量,此向量表示\(I_1\)每一个像素点与所有\(I_2\)像素点的相关度。然后作者也考虑到这样的表示可能比较稀疏,因此在这个输出之后做了四层的池化,并将每一层池化的输出连接起来做成了一个具有多尺度特征的相似性变量。(3)一个update operator,通过使用一个look up方法(查看4D Correlation Voulumes的值)迭代着去更新光流。当然第三点需要下面的详细介绍。
将模型拆解一下:
- 两次特征抽取
这个比较好理解,就不多说了。
-
Correlation Layer
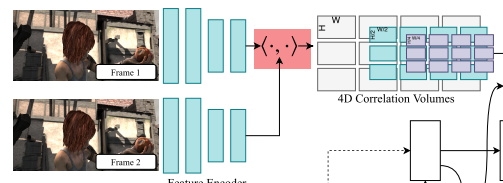
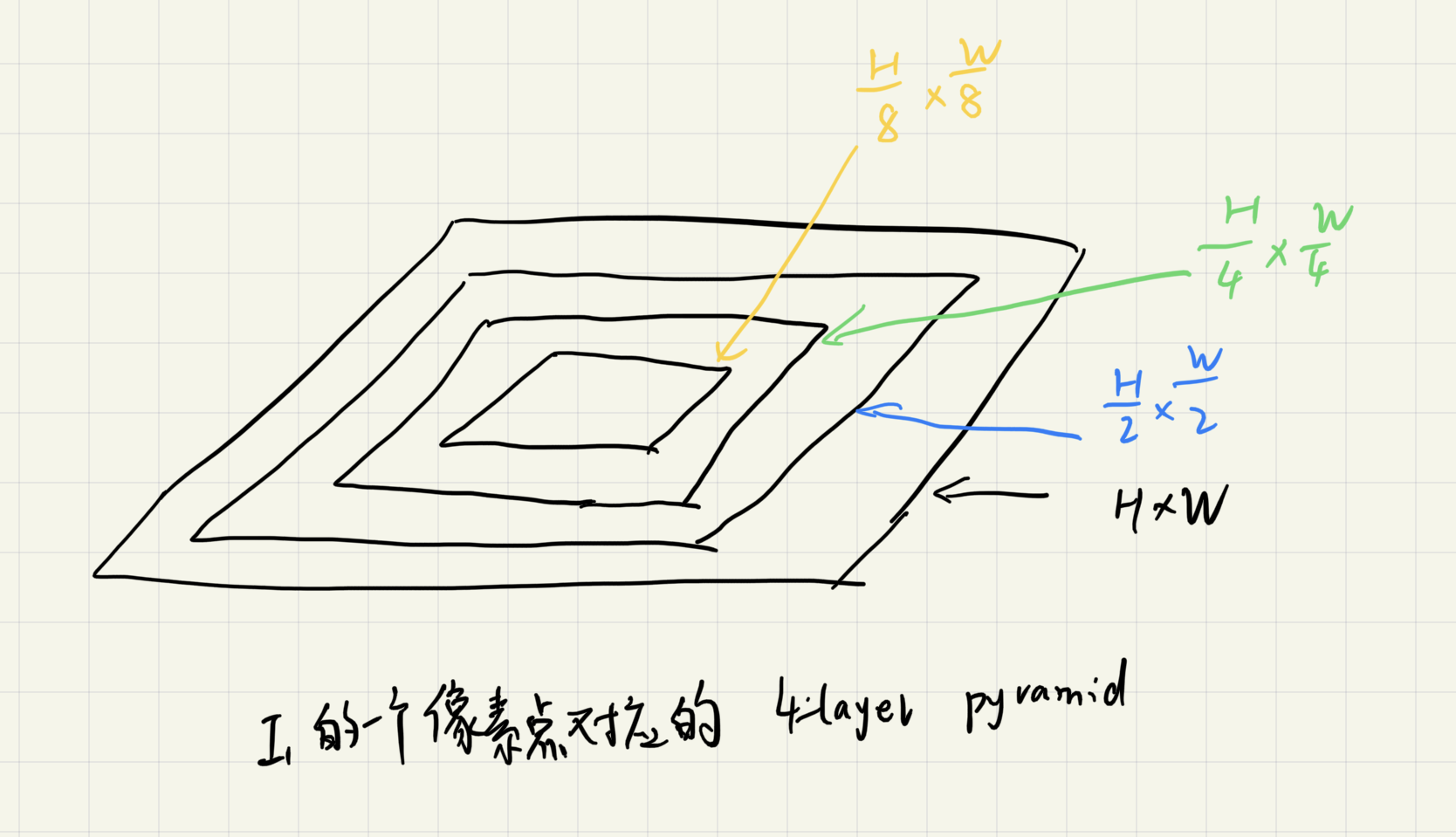
这里我们得到了\(I_1\)对\(I_2\)上的多尺度4D Correlation Voulumes,那么这个值是怎么得到的,又代表什么意义呢?前面我们提到过,我们得到\(H \times W \times H \times W\)的向量之后,作者觉得这样比较稀疏,因为\(I_1\)不可能与\(I_2\)所有的像素点相关,所以作者又将这个向量进行了四层池化:

得到了如图所示的3层向量(第四层没画出来,也就是\(H \times W \times {H\over8} \times {W\over8}\)),将他们叠在一起,就构成了一个多尺度的相似性向量的金字塔。
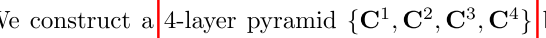
- Look up
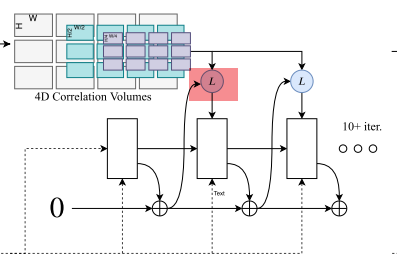
在这个L里,作者做了一件有趣的事情,我们知道,光流\((f^1 , f^2 )\)表达了这样一件事情, 它可以把\(I_1\)上的每一个像素\(x(u,v)\)通过$ x'=(u+ f^ {1} (u),v+ f^ {2} (v)) $与 \(I_2\)上对应像素\(x'\)建立映射。然后作者在\(x'\)附近构造了一个网格:
\(r\)超参数是超参数,有点类似于圆的半径,\(d_x\)是整数,通过这个公式把\(x'\)附近的值拿到,同时这个操作会在每一层的金字塔上取值,最后将这些得到的值串联成一个向量。这个向量也就是 Look up的输出。总结一下就是光流建立了\(I_1\)的像素点到\(I_2\)像素点的映射,然后使用对应的\(I_2\)点的坐标,在对应的相似性向量的金字塔上采样得到一个输出向量。那么大胆猜测一下,对于快速移动的物体,\(r\)设置的偏大一些,效果应该更好;对于移动较慢的无题,\(r\)设置的应该偏小一些。当然这个也是Coupled Iterative Refinement for 6D Multi-Object Pose Estimation,标题中论文沿用的一个方法。
-
update operator
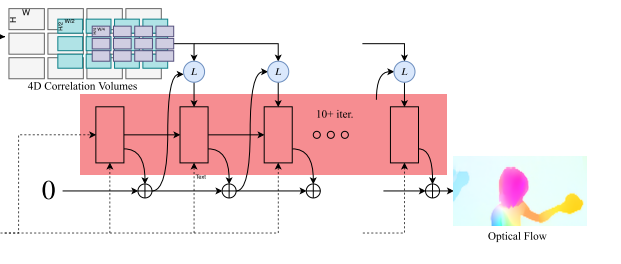
这个类似于GRU模型的结构,把context features以及Look up输出的向量(通过flow和correlation pyraid得到)作为输入\(x_t\),以及hidden state作为 \(h_{t-1}\)作为输入,然后输出\(\Delta \mathrm{f}\)和更新后的的hidden state\(h_t\)。GRU的内部结构是这样定义的:
- loss function
作者使用的并不只是最后的输出,而是update operator每一次迭代的光流输出\(\left\{\mathbf{f}_1, \ldots, \mathbf{f}_N\right\}\),去跟\(f_{gt}\)求loss。
\(gamma=0.9\)
最后再简单看一组对比结果:

至此我们介绍完了RAFT的相关方法。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16779462.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号