Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读
 Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读
这是2022年发表在CVPR上一篇关于位姿估计的一篇文章。在正式介绍这篇论文之前,我们需要了解一下RAFT,因为要介绍的论文很多地方都受到了RAFT的影响。

关于RAFT的介绍可以查阅原论文:https://link.springer.com/chapter/10.1007/978-3-030-58536-5_24
也可以查看这篇博客:https://www.cnblogs.com/programmerwang/p/16779462.html
论文介绍
Abstract
提出了一个6D multi-object pose的任务:给予一些已知的3D模型的RGB或者RGBD输入图片,去检测,估计每一个物体的6D位姿。然后作者提出了一个方法端到端地去解决这个问题,并且使用了几何信息。方法是去refines both pose and correspondence in a tightly coupled manner。然后作者又通过他提出的BD-PnP方法把位姿估计变成了一个最优化问题。
Introduction
作者介绍了传统的6D位姿估计的一些方法:
(1)通过特征匹配的方法去建立2D-3D的对应关系。然后通过PNP求解6D位姿,这个恰好是我毕设的做的事情。但是这种方法的缺点是无法处理无纹理的物体,遮挡,对称物体,还有关照变化等情况。
(2)最近这些问题通过深度学习的方法得到了一定程度的解决,但是这些方法都是直接建立输入和输出的映射,并没有充分使用像素是3D object的投影这个事实,这句话我其实看得有点莫名其妙,当然作者的确使用到了一些几何知识,我们最后直接看看本文的方法和直接建立输入和输出的映射的对比吧。
(3)一些方法也尝试了使用深度学习和投影几何结合,比如有一种是通过学习的方法建立2D-3D的映射,然后再使用PNP求解;是另一种方法是以隐含层或陈述层的形式施加几何知识,这些工作表明,PnP可以作为一个模块化组件在端到端可微体系结构中实现。然而,这两种方法都是"一次性"的,因为对应关系是预测一次,然后通过一个PnP求解器(可微或不可微)来解决;这使得方法对异常值和对应关系中的错误很敏感。(翻译)
然后作者提出了一个模型结构,使用了几何信息,并且通过迭代的方式去共同更新 pose and correspondence;
作者提到了他们的工作建立在RAFT的基础上,作者的基础思想是估计输入图片与一系列的渲染图片的光流,然后建立2D-3D的对应关系去估计位姿(还记得前面提到的光流的作用吗),作者同样使用了GRU的思想去迭代着更新光流和位姿,并且这二者是紧密连接的。
为了更新位姿,作者然后使用了Bidirectional Depth-Augmented PnP (BD-PnP),这层把通过使用 Gauss-Newton update 来更新pose以最小化投影误差。
然后有意思的地方来了,其实看到Bidirectional这个词,我就意识到了一些事情,在自然语言处理中,以及使用到一些具有时序信息的数据(视频,语音等)把数据正向输入模型的同时,通常会反向再输入一次,因为有前就有后,有后就有前,而且这样做,模型的性能一般都会获得提升。
言归正传,作者是怎么体现Bidirectional的呢?前面我们提到,作者估计了输入图片和一系列渲染图片的光流,然后这个光流可以是双向的,也就是input->render,render->input。具体是怎么用的,且待稍后揭晓。之后,作者还使用了depth-augmented。不过由于我的几何基础比较差,不太能看懂,直接放原文吧。
Second, our layer is “depth-augmented”: the optimization objective also includes the reprojection error on inverse depth, which we show to be important for improving accuracy.
Related Work
这里就是介绍了其他人的一些方法,就不过多展开了,感兴趣的读者可以去阅读原论文。
Approach
作者先是假定了,RGB-D输入,然后说明方法分为三部分:(1)object detection, (2) pose initialization, and (3) pose refinement.前两部分作者沿用的方法是CosyPose的方法,由于本文重点书写的内容是第三步,前两步我就不过多展开了,感兴趣的读者可以看一下CopyPose;或者假定我们检测到了输入图片中的物体,并且给予了初始位姿,看看作者是怎么去做 refinement的。
Preliminaries
给予了3D object还有相机内外参数,可以生成一系列的渲染图片还有深度图。
我们让\(G_0\)作为object pose,也就是后期要进行迭代优化的对象。\(\left\{\mathbf{G}_1, \ldots, \mathbf{G}_N\right\}\)
作为系列渲染图片的pose。那么可以建立这两者之间的点的映射关系。就是\(G_0\)渲染图片的像素点到\(\left\{\mathbf{G}_1, \ldots, \mathbf{G}_N\right\}\)渲染图片的像素点可以通过一些计算建立映射关系,(嗯,的确是可以的,但是需要一定的几何知识才好理解),反之亦然。
- \(\left\{\mathbf{G}_1, \ldots, \mathbf{G}_N\right\}\) image points to \(G_0\) image points
- \(G_0\) image points to \(\left\{\mathbf{G}_1, \ldots, \mathbf{G}_N\right\}\) image points
我们的目标就是求解\(G_0\),使得方程(2)能够正确的建立起input image crop和renders的像素点的映射关系。
更多定义的细节:

总之,作者通过几何的方法,使用公式(1),(2)建立了\(G_0\)渲染图片的像素点到\(\left\{\mathbf{G}_1, \ldots, \mathbf{G}_N\right\}\)渲染图片的像素点互相的映射关系,并且是Bidirectional。
然后就是\(G_0\)作为后续不断地Refine的基础,它的初始化自然也是十分重要,作者是基于CopyPose的方法做的。

Feature Extraction and Correlation
得到了初始位姿之后,作者在这个位姿的基础上做了一些pitch, yaw or roll方向上旋转,最后得到了7个render views。然后作者采用了RAFT的方法,建立了每个render和输入图片的image crop的correlation pyramids,然后注意,这个是双向的。correlation pyramids在前面RAFT介绍过,遗忘的读者可以回顾一下。
Coupled Iterative Refinement
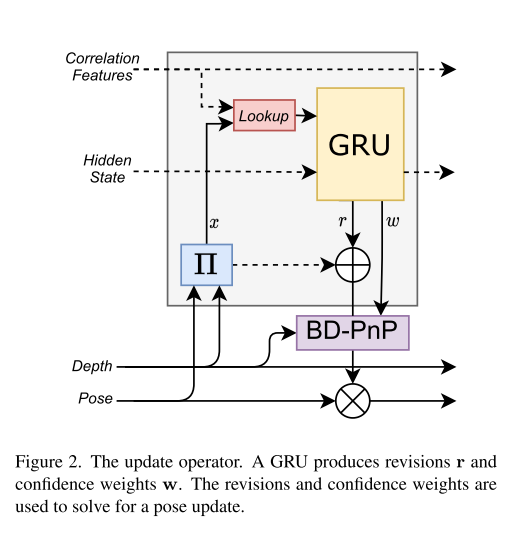
作者先是使用公式(1)(2)分别求解renders到\(G_0\)以及\(G_0\)到renders的\(\mathbf{x}_{i \rightarrow 0}\),\(\mathbf{x}_{0 \rightarrow i}\)的映射,其实我感觉\(\mathbf{x}\)像是是光流,因为建立了图像间点的映射,但又不完全是光流,因为\(\mathbf{x}\)还与inverse depth有关。但总之是像素点之间的映射。

这里的inverse depth我不太明白具体的作用,以后遇到的时候再来回顾吧。
之后又通过这个映射加 Correlation Features输入到 Look up方法,得到一个correlation features \(\mathbf{s}_{i \rightarrow 0} \in \mathbb{R}^{H \times W \times L}\).最后作者将这个向量 + 上一时刻的 hidden state 以及 additional context and depth features输入到GRU,得到下一时刻的 hidden state + r(represents a new flow estimate) + w(a dense map of confidence in the predicted revisions,是r的一个置信度)。
Bidirectional Depth-Augmented PnP (BD-PnP):
BDPnP layer 把上面预测出的校正值 \(\mathrm{r}\) 和confidences \(w\) 转换成 a camera pose update \(\Delta \mathbf{G}_0\).
校准值\(r\)作用在\(x\)上:
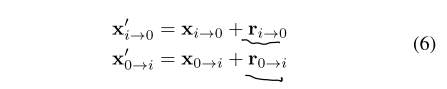
那么这里是怎么得到\(G_0\)的更新的呢:
为了便于理解,请留意一下下面这句话:
其实整个模型在迭代的过程中,其实真正学习到的是对于前面映射关系x的修正r,详细解释一下这句话就是:由于初始x是使用initial pose \(G_0\)和相关的render views求出来的,这肯定是不准的(因为只有当\(G_0\)越接近\(GT_{pose}\),这个映射关系\(x\)才越准确),我们的模型学会了对映射关系的修正,那么修正后的映射基本会是比修正前要好,然后就使用修正前后的距离来迭代着更新\(G_0\),也就是公式(10)
一言以蔽之:这个模型是使用修正前后的距离来更新\(G_0\)的。

Summary
-
Correlation Features是Renders与\(G_0\)计算得到的。
-
Depth + Pose二者可以求出\(x\) ,Renders pose 与 \(G_0\)之间点的对应关系。
-
上述两者通过
Lookup方法得到一个向量。 -
\(GRU\)接收输入,输出针对\(x\)的修正,使\(G{0}\)其更加接近\(G_{gt}\),还有confidence map \(w\),这里算是对光流估计的一个训练。
-
BD-PNP接收参数。输出对Pose的更新值,也就是\(G_{0}\)更新。
-
最后要注意的是,当\(G_{0}\)更新后,相关的7个renders也会在下一次迭代更新,然后重复这个过程。
-
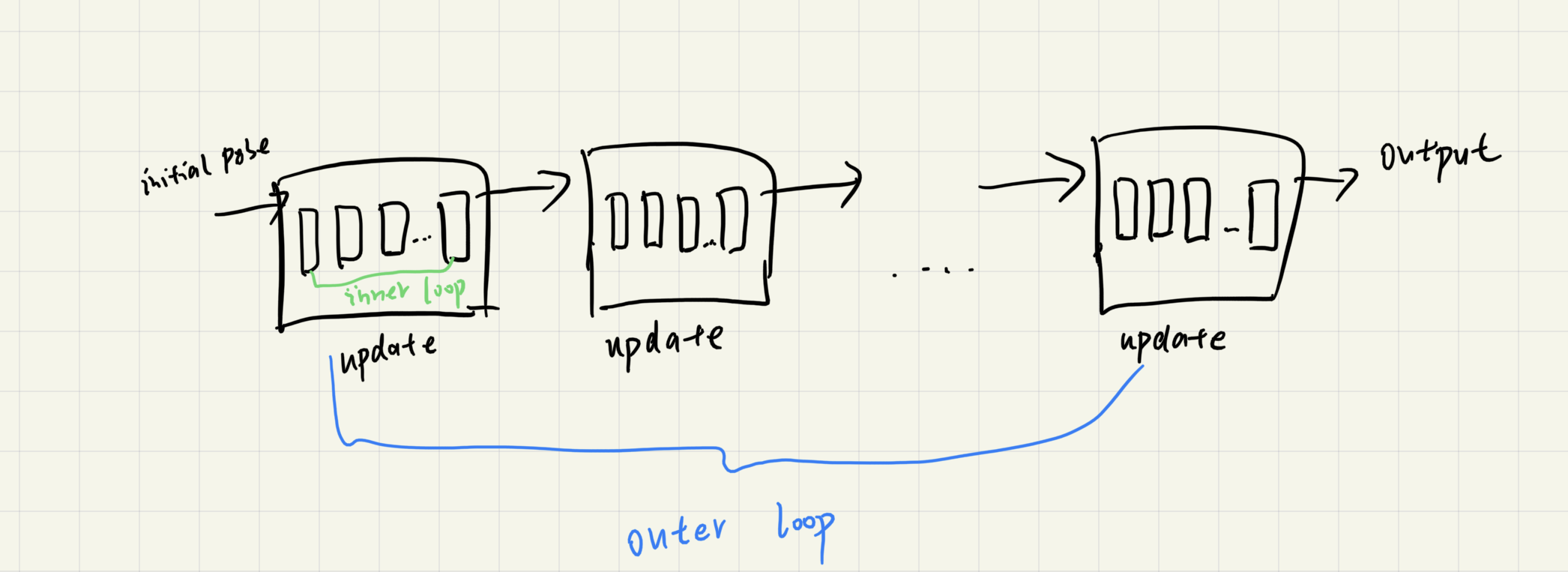
innerloop就是模型内部update operator的迭代次数,Outloop就是这个模型整体上迭代多少次,大概是下图的意思:
Experiments
Conclusion
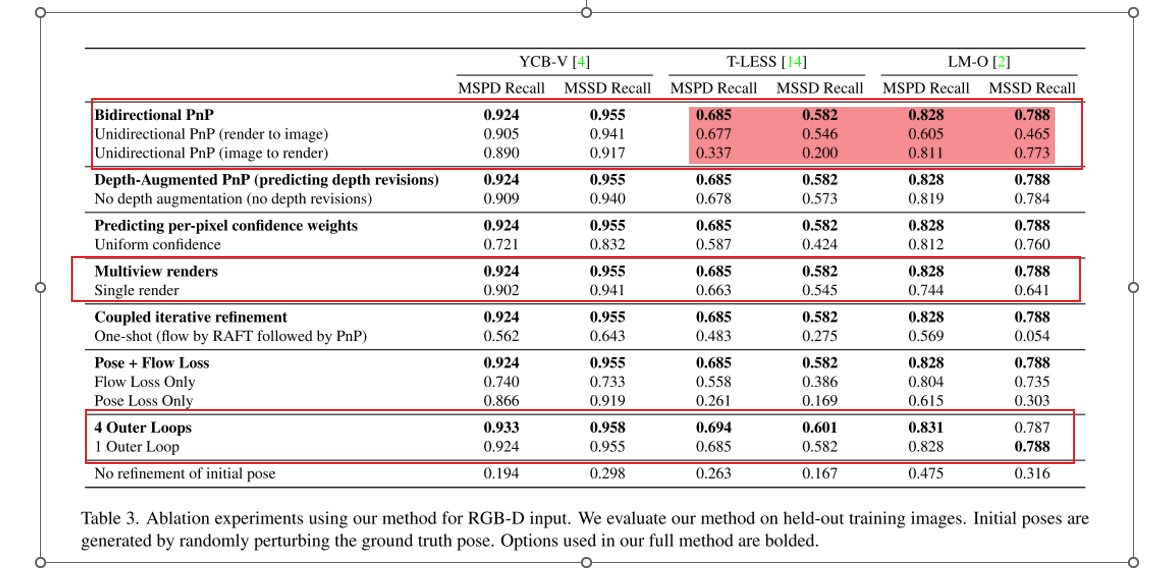
这篇论文的方法其实是比较复杂的,也需要很多的先验知识,RAFT, CopyPose,投影几何等,而且一些地方我看得也不是特别清晰。还有就是整个文章的代码效率我觉得比较低,运行一张4个物体的照片甚至会需要20s,不知道在实际应用中会有什么意义。还有就是之前实验的代码跑的是RGB的,但是这篇论文整体上是假设以RGBD为输入进行优化的,所以看起来RGB可能效果没那么好,作者是把RGB的深度值看成一个定值去处理的。
如果要总结一些收获的话,我觉得可能有以下几点:
-
自然语言处理中一些方法开始进入视觉了,从 RAFT光流估计到这篇论文,我看到了其中的一些思想的借鉴,比如使用GRU迭代去处理一些信息。
-
Bidirectional思想,对时序信息的双向输入,往往能使模型的性能得到提升。
-
投影几何的一些基础知识,会在用到时继续学习。
-
鉴于个人的局限性,总会有疏忽错误的地方,欢迎留言讨论
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16771556.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号