Two-Stream Convolutional Networks for Action Recognition in Videos论文精读
 Two-Stream Convolutional Networks for Action Recognition in Videos论文精读
Two-Stream Convolutional Networks for Action Recognition in Videos论文精读
Two-Stream Convolutional Networks for Action Recognition in Videos论文精读
大家好,今天我要讲的论文是一篇视频理解领域的开山之作,这是2014年发表在NIPS的一篇文章。这篇论文理解起来相对简单,但是结合当时的时代背景,我们也许能从这篇开山之作里获得一些启发。
作者一开始先指出,视频是一个很好的数据来源,相对于2D的图片,它有物体的移动信息,有时序信息,有音频信息,也更接近我们人眼看到的世界。
Task
这篇文章应用的领域是视频分类,也就是对于这样一类标注好的数据集,我们希望网络求解出视频中的动作的分类。
Optical Flow

按照维基百科的定义呢,光流是描述观察者与场景中物体相对运动的一种模式。我目前是理解成图片中物体的运动信息,比如这张图:

我们提取监控下的一段视频,使用这一帧,和其下一帧计算光流,就可以得到下面这幅图,我们可以看到,光流很明确地捕捉到了人的运动,并且只关注了人的运动,也就是说人的性别,衣着等信息都是被忽略掉了。

再然后就是光流是有方向的,可以在一个二维平面上拆分成水平和竖直的两个方向。
key-idea
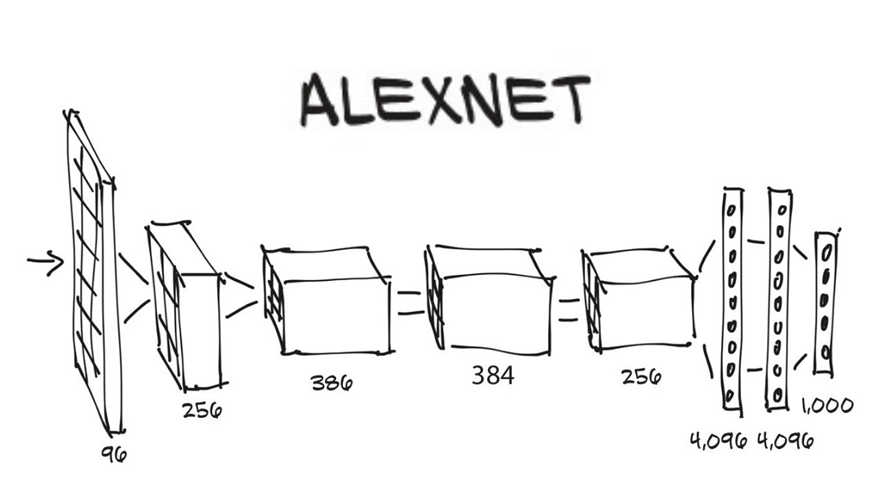
在这之前的基于卷积神经网络的方法是把视频帧堆叠在一起传递给卷积神经网络去做视频分类,当然也尝试对模型的结构做了一些调整试图帮助模型学到时序信息,但并不能取得一个较好的结果,甚至传统的手工设计的方法都没有超越。
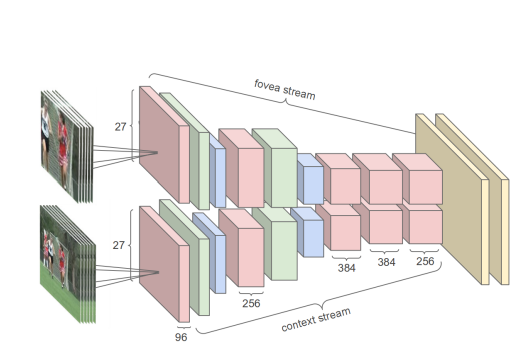
| Large-scale video classication with convolutional neural networks | Bag of visual words and fusion methods for action recognition:Comprehensive study and good practice |
|---|---|
 |
 |
这个模型是在一个百万量级的数据集上做的预训练,然后迁移到UCF101上,但是结果都没有超越手工设计的方法(低20%),这在当时的深度学习大火的年代,显然是让人失望的。
所以作者认为:卷积更加擅长去学习一些局部的空间信息,并不擅长去学习一些时序信息。

那么基于此,既然卷积学不到视频中的时序信息,那我直接给你。作者想到的是直接去抽取出视频帧之间的时序信息,传递给卷积神经网络,使这些时序信息与最后的动作分类建立一个映射,建立映射关系是CNN的强项了,这里的时序信息也就是前文提到的光流。
Architecture
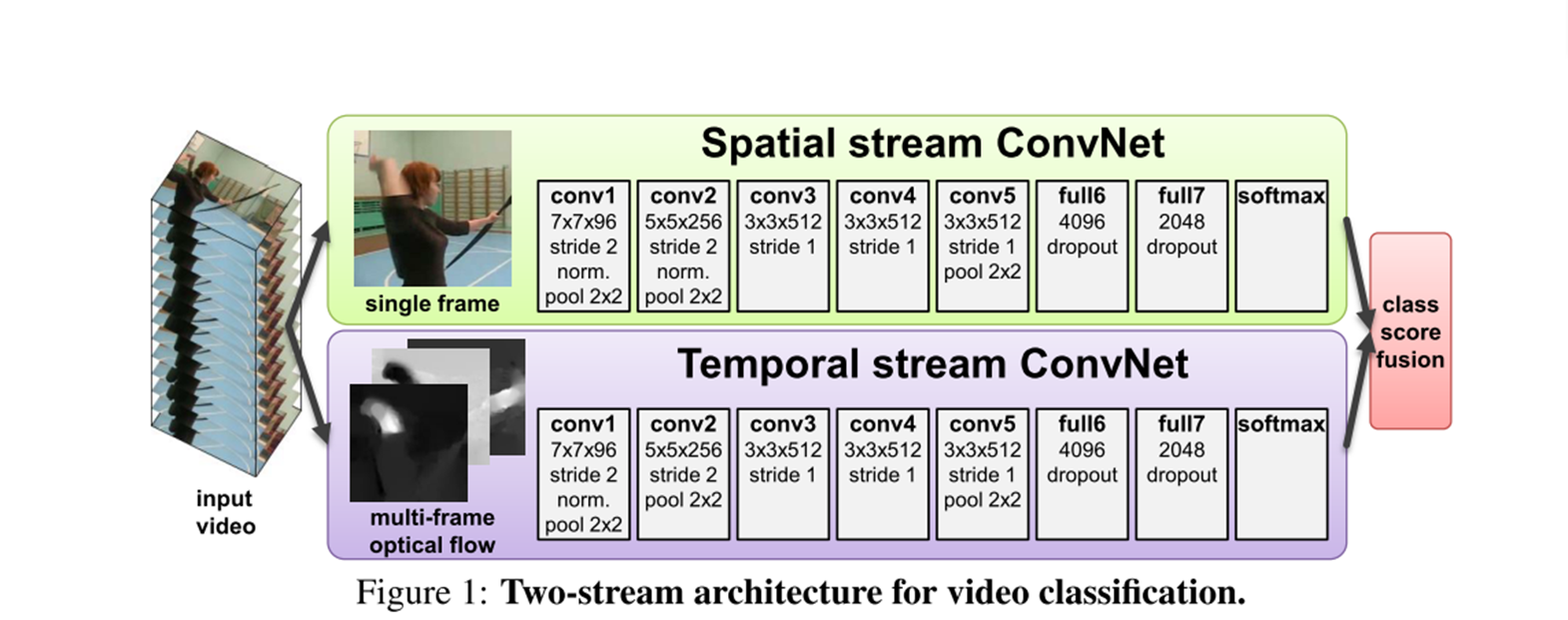
这就是双流神经网络的大体结构,一个是Spatial stream Convnet,另一个是Temporal Stream ConveNet,他们分别对视频中比较重要的两种信息去处理,第一种是空间信息,比如视频中出现篮球,小提琴,这和最后的动作分类是息息相关的,另一种则是时序信息,视频帧与帧之间的光流。再简单提一下输入是怎么构造的,先是抽取一系列的关键帧,对于一个当前帧,假设其尺寸是\(w \times h\),往后去取\(L\)帧,那么一共是\(L+1\)帧,则可以得到\(L\)帧的光流,也就是 \(w \times h \times 2L\)的维度。
Result
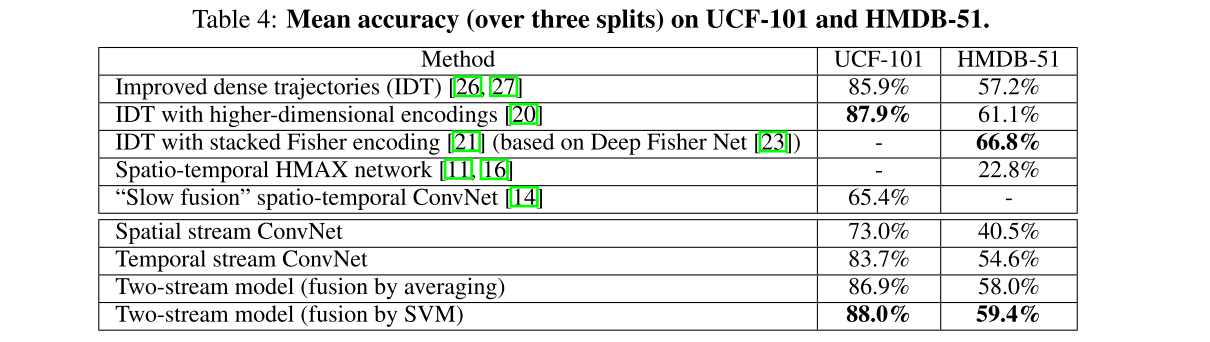
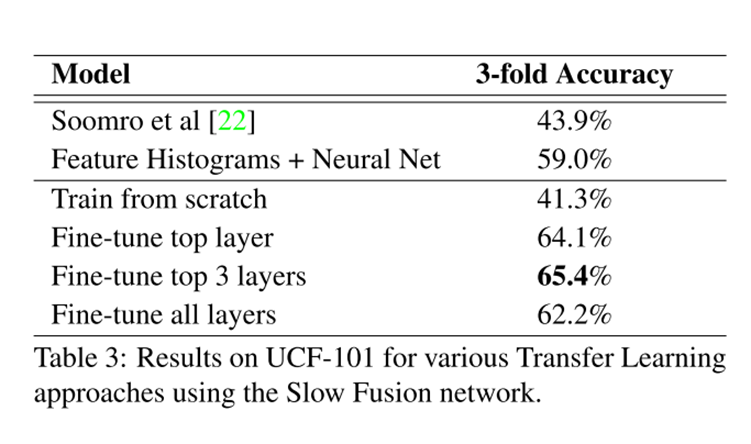
他的结果值得一看,首先是前3行,是人工设计的方法,其中第2,3行是对第1行方法的改进,4,5行是之前传统的卷积的方法,我们可以看到效果很一般,即使是Slow fusion,在一个百万量级的数据集上做预训练,效果也差强人意。但是有意思的是 Temporal stream ConvNet这一行,仅仅使用光流去当作输入,准确率也能达到83.7%,可见视频中的时序信息是多么的重要。至于两个分支的叠加,效果自是不必说。由于这篇论文证明了这种方法视频理解上的有效性,后续的很多研究也跟进,已经在UCF101上把准确率‘卷’到了98%。
Inspire
1.The temporal information is the very important information in videos
2.Although typical convolution is effective, but still has it’s limitation, such as conv the temporal information automatically.
Reference
https://en.wikipedia.org/wiki/Optical_flow
https://stackoverflow.com/questions/28898346/visualize-optical-flow-with-color-model
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classication with convolutional neural networks. In Proc. CVPR, 2014.
X. Peng, L. Wang, X. Wang, and Y. Qiao. Bag of visual words and fusion methods for action recognition:Comprehensive study and good practice. CoRR, abs/1405.4506, 2014.
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16753824.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号