任务进展.....
任务进展.....
任务目标
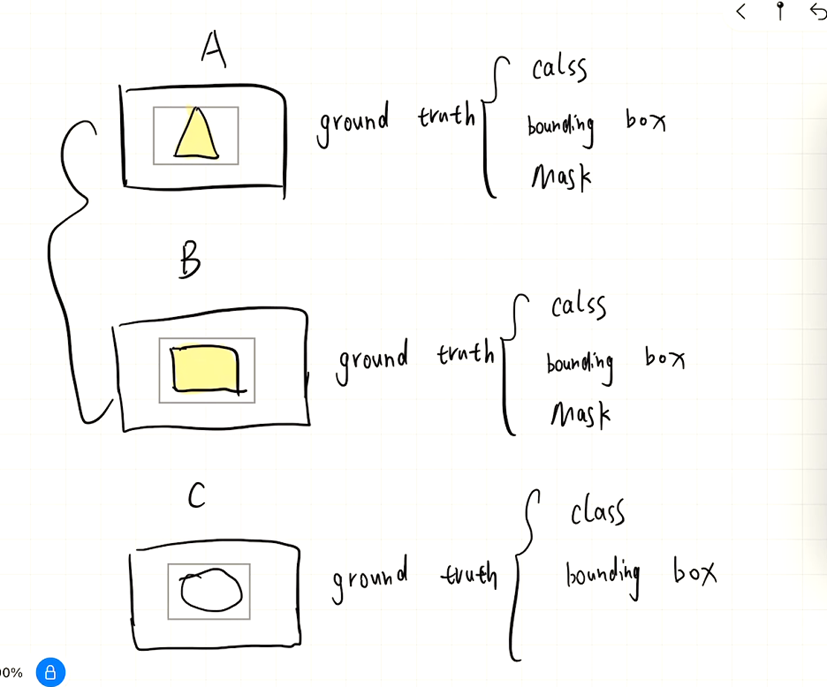
任务目标1:对于一张图片,在人为给定一些检测框的前提下,去提取出检测框内的mask。
任务目标2:对于一张图片,提取出图片中潜在物体的bounding box,及其mask。
这两个任务目标的唯一区别就是,目标1物体的bounding box是人为给定的,目标2是算法生成的,不过这不是本篇文章讨论的重点,此篇博文着重介绍Mask RCNN以及DeepMAC在Mask预测上的质量。
两类方法简介
Mask-RCNN
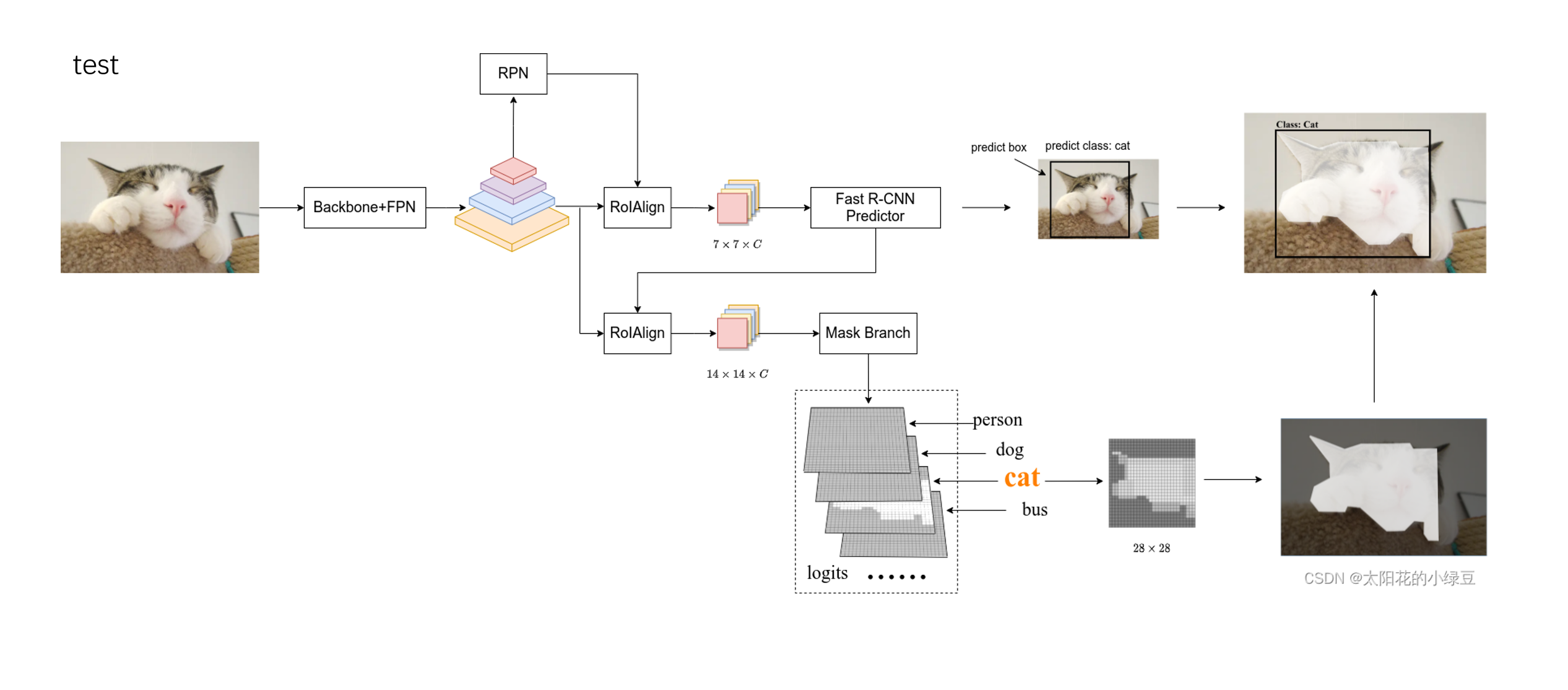
大体回顾一下,在测试阶段代码的运行逻辑:
对于一张输入图片,我们先使用一个Backbone+FPN提取出这张图片的特征图,然后通过RPN去生成一些Proposals。RPN是一个神经网络,能够在特征图上提取出一些候选框;
然后再通过RolAlign将每个proposal对应的特征图采样成固定的大小,之后我们便可以通过这个特征图去预测出类别和bounding box偏置;
而对于Mask的预测,则需要Fast RCNN predictor分支预测出的bounding box和分类的传入,然后同样是在特征图上进行投影,通过RolAlign采样成固定的大小,然后预测出类别相关的MASK。
备注:单纯观察Mask-RCNN目前的运行逻辑,似乎还是一个类别受限的网络(上图的Mask分支),如果一个图片中的物体类别对于Mask-RCNN来说是未知的,那么网络是否还能预测出这个物体的 类别、bounding box、进而得到Mask呢?答案是可以,在下文的实验部分我们可以看出,对于一些未知的物体,尽管物体的种类预测失败了,但是也能得到较好的Mask。
DeepMAC
这篇论文中有部分工作,就是实现了一个class-agnostic的结构:也就是给定一个bounding box,并不关心box内物体的类别,而是直接预测出box内物体的Mask。
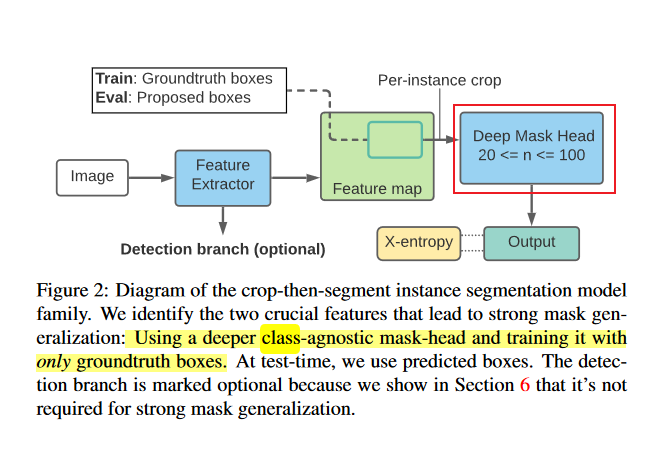
备注:这个地方的class-agnostic在Mask RCNN论文里有提过(如下图),Mask RCNN在尝试了两种不同的方式后,发现class-specific结构在全监督训练的情况下的AP略好于Class-Agnostic,因此Mask-RCNN使用了class-specific。

实验
看一下二者的Mask质量:
| Mask RCNN(RPN生成的bounding box) | DeepMAC(人工给定bounding box) | ||
|---|---|---|---|
| 0 |  |
 |
这个DeepMAC要好一些,比如那个米尺,右边的刀子。 |
| 1 | 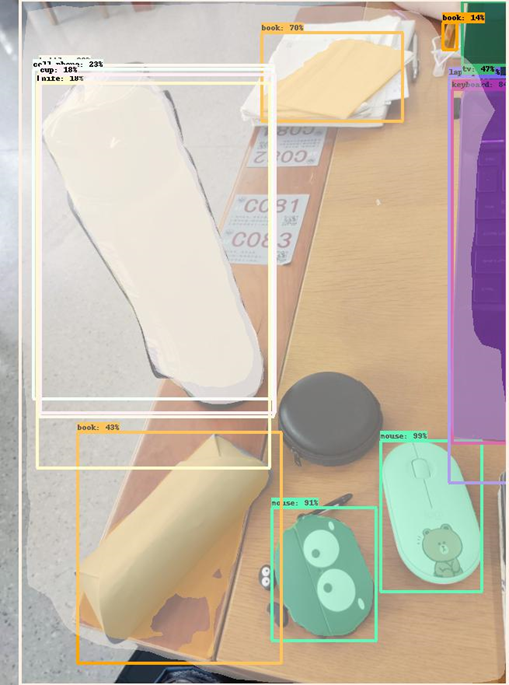 |
 |
二者的眼镜盒都很差,杯子DeepMAC后者好一些。 |
| 2 |  |
 |
没有明显的差距。 |
| 3 |  |
 |
这个是二者都见过的物体,就是训练集出现过。没有明显差异 |
| 4 |  |
 |
这个是二者都见过的物体,就是训练集出现过。没有明显差异。 |
为了方便,DeepMAC的框虽然是人工输入,但是尽可能参照了Mask RCNN输出的预测框,保证了实验的一致性。关于泛化性的话,的确是DeepMAC好一点,但是也不是特别明显。
原因推测
当然凭借朴素的直觉,DeepMAC的泛化效果应该是比Mask RCNN好很多的,但是具体的代码却没有明显的差距,这是为什么?
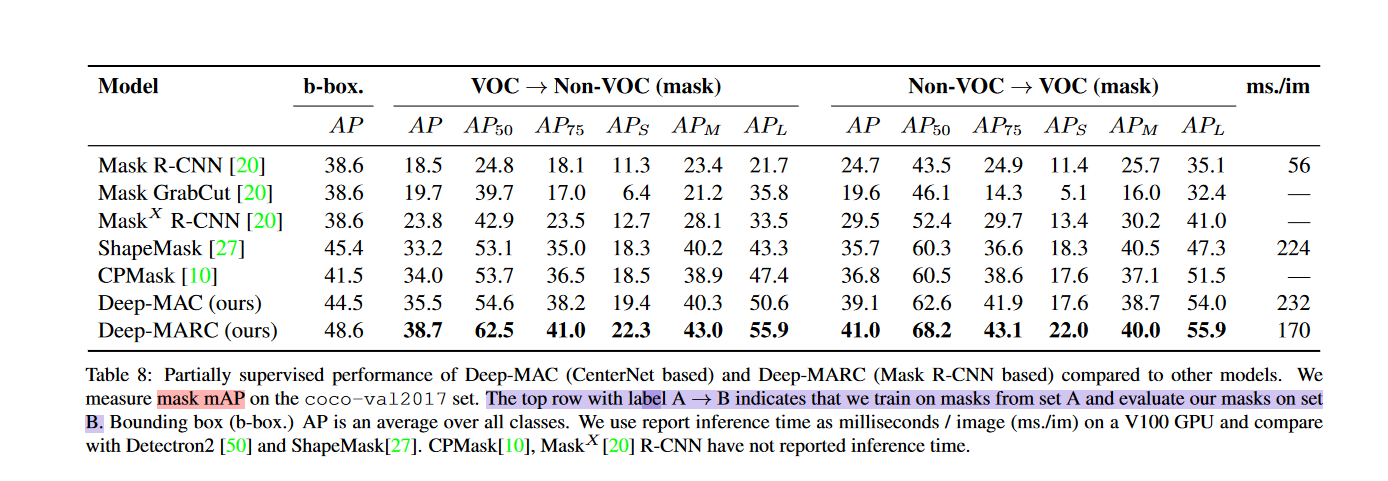
应该是实验任务的不同,DeepMAC要解决的问题是对于一个数据集,我们希望获得模型在C类数据上的泛化性:
然后作者提出了他的方法,Deep Mask branch + GT only,也因此取得了本小节第一张图的实验结果。
而此时对于Mask RCNN来说,经过官方不断地训练,迭代,其Mask-branch的泛化性也得到了较好的保证。
回到我们最开始的任务:
任务目标1:对于一张图片,在人为给定一些检测框的前提下,去提取出检测框内的mask。
任务目标2:对于一张图片,提取出图片中潜在物体的bounding box,及其mask
目前来看,Mask的质量已经有了比较好的保证,比较关键的问题应该是检测框的生成。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16452368.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号