目标检测论文泛读
目标检测论文泛读
最近的任务可能会用到目标检测里的proposal,我目前对proposal这个词的理解是潜在的可能是检测物体的bounding box。因此本篇博文大致介绍一下各种方法的工作方式之后,会着重介绍proposal的生成。同时还要注明一点,这是一篇笔记文章,论文中的一些名词暂且不做详尽的解释,如果有疑惑的地方可以结合原论文阅读。
Fast RCNN
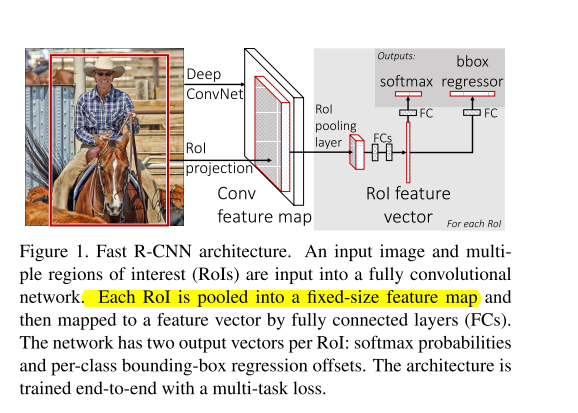
该模型的输入是一张完整的图片 + 这张图片的proposals,图片的proposals是通过Selective Search得到的。
贡献:
1.不需要人为地对图片进行操作(RCNN中的这部分操作一定程度上破坏了图片的结构信息),在过程中通过ROI pooling layer将特征图resize成固定的尺寸,以满足全连接层的输入要求。
2.只对图片进行一次CNN特征提取,然后共享特征图进行多任务操作,也就是共享了卷积操作,大大减少了计算量,减少了运行时间。
3.用softmax取代SVM分类器,将原来分步处理合并成一个连续的过程,避免了特征存储、浪费磁盘空间等问题,降低了过程的复杂度。
4.处理图片速度大大提高。
缺点:
Fast R-CNN中采用selective search算法提取候选区域,而目标检测大多数时间都消耗在这里,selective search算法候选区域提取需要2~3s,而提特征分类只需要0.32s,这无法满足实时应用需求。
Faster RCNN
这篇论文读起来挺酣畅淋漓的,它是对前文Fast RCNN的一个升级,主要做的工作就是将生成Proposal的工作整合到一个网络中了,这样输入就是一张单独的图片。
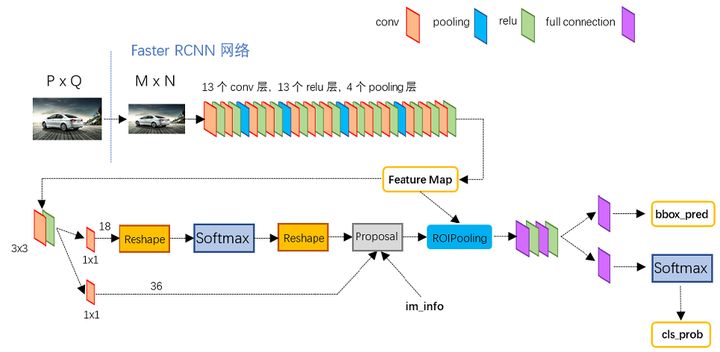
其结构如图,图片引自知乎大佬白裳。
结合原论文介绍一下Region Proposal Networks(RPN)是如何实现的。
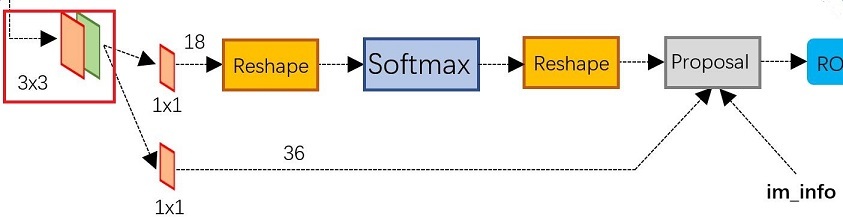
对于前面卷积神经网络得到的特征图,我们以原文使用的VGG16为例,网络最后的feature map的维度是\(58 \times 38 \times 512\),首先通过一个\(3 \times3\)的卷积,得到的仍是\(58 \times 38 \times 512\)的输出,这一步相当于每个点又融合了周围\(3 \times3\)的点的信息
-
第一条线
再通过一个\(1 \times 1\)的卷积,卷积核个数是18,因此输出一个\(58 \times 38 \times (9 \times 2)\)的向量,之后通过一个Softmax函数输出特征图每个点对应的每个anchor的
is object or not object的概率。 -
第二条线
再通过一个\(1 \times 1\)的卷积,卷积核个数是36,因此输出一个\(58 \times 38 \times (9 \times 4)\)的向量,之后通过一个Softmax函数输出特征图每个点对应的每个anchor的四个坐标。
至此 RPN网络生成了对应的proposals。其损失函数是:

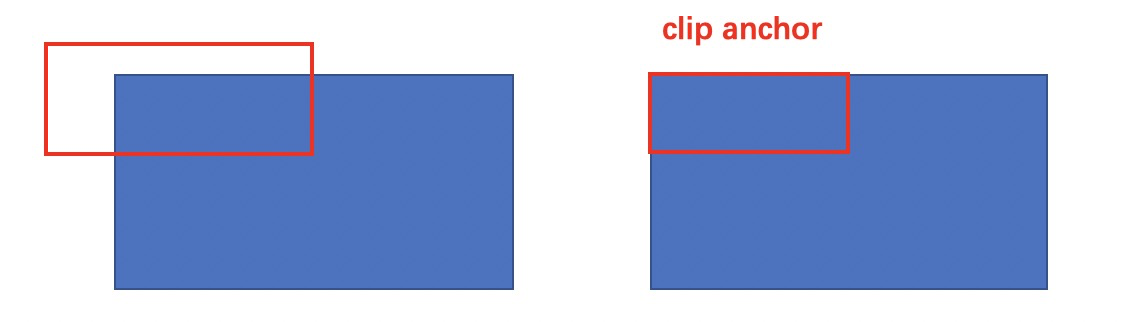
值得留意的是在训练和测试RPN阶段,二者使用的都并不是所有的anchor,训练阶段采用的是从每个minibatch中随机采样出256个anchor,其中positive和negative的比例是1:1,在测试阶段则是使用了所有的anchor,但是把超出图片范围的anchor裁剪了。
由于这个网络综合来看,是存在两个结构,一个是FAST RCNN,另一个是RPN,至于怎么综合训练这个网络,论文分了四个步骤:

Mask RCNN
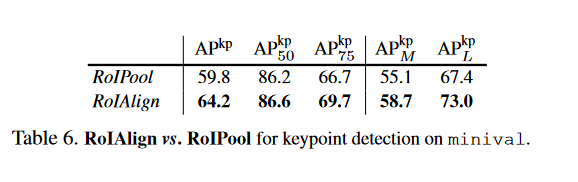
ROL pooling vs RolAlign
这里建议先去了解一下这两个概念,总之就是ROL pooling会忽略特征图的很多信息,而RolAlign通过特定的的方法,去尽可能的保留特征图的信息,后者的准确率会高很多,现在的实现方法也都是RolAlign。
结构
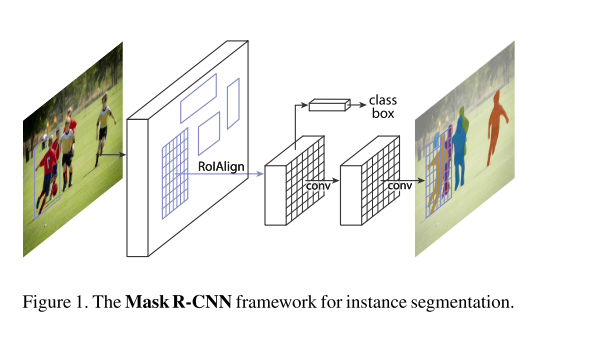
这篇论文其实挺复杂的,刚开始读起来的时候,涉及到的技术也比较多,比如FPN,FCN,ROIAlign。
-
使用FPN构建特征图
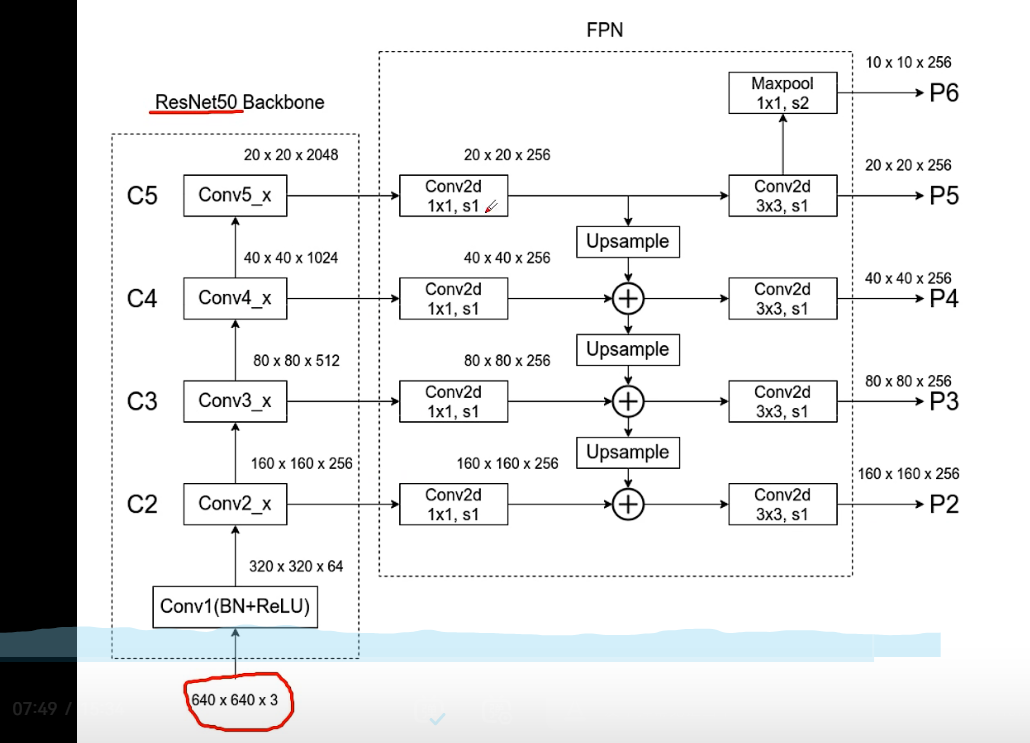
-
Loss Function
\[L O S S=L_{r p n}+L_{{fast\_rcnn}}+L_{mask} \]
前面两个跟之前的Faster_RCNN是一致的。这里重点介绍一下\(L_{mask}\)
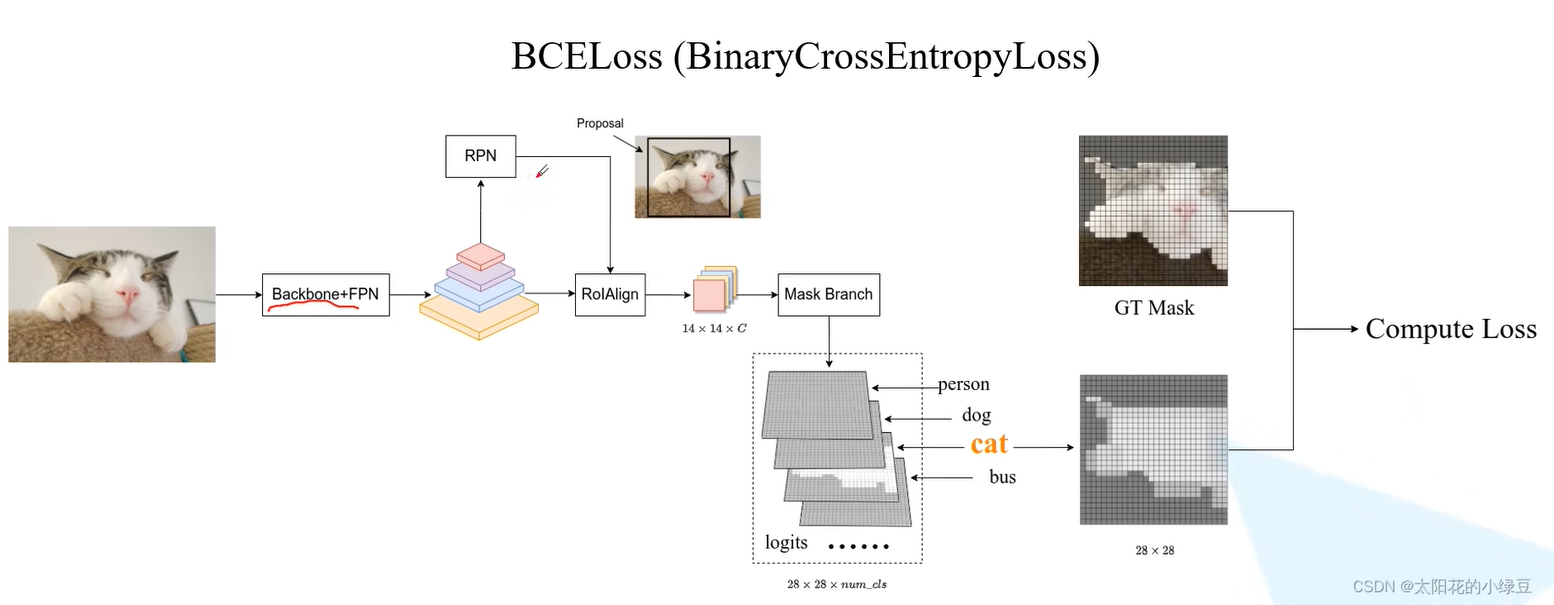
首先通过backbone+FPN生成特征图,然后通过RPN网络生成一系列的Proposals(正样本),对应每一个proposal,将其结合特征图输入RolAlign得到一个向量进入mask Branch得到一个\(28 \times 28 \times num\_cls\)的mask,然后将其映射到原图大小,在将原先的proposal映射到原图,二者去计算一个loss。
我们接着从测试角度去理解一下Mask-RCNN:
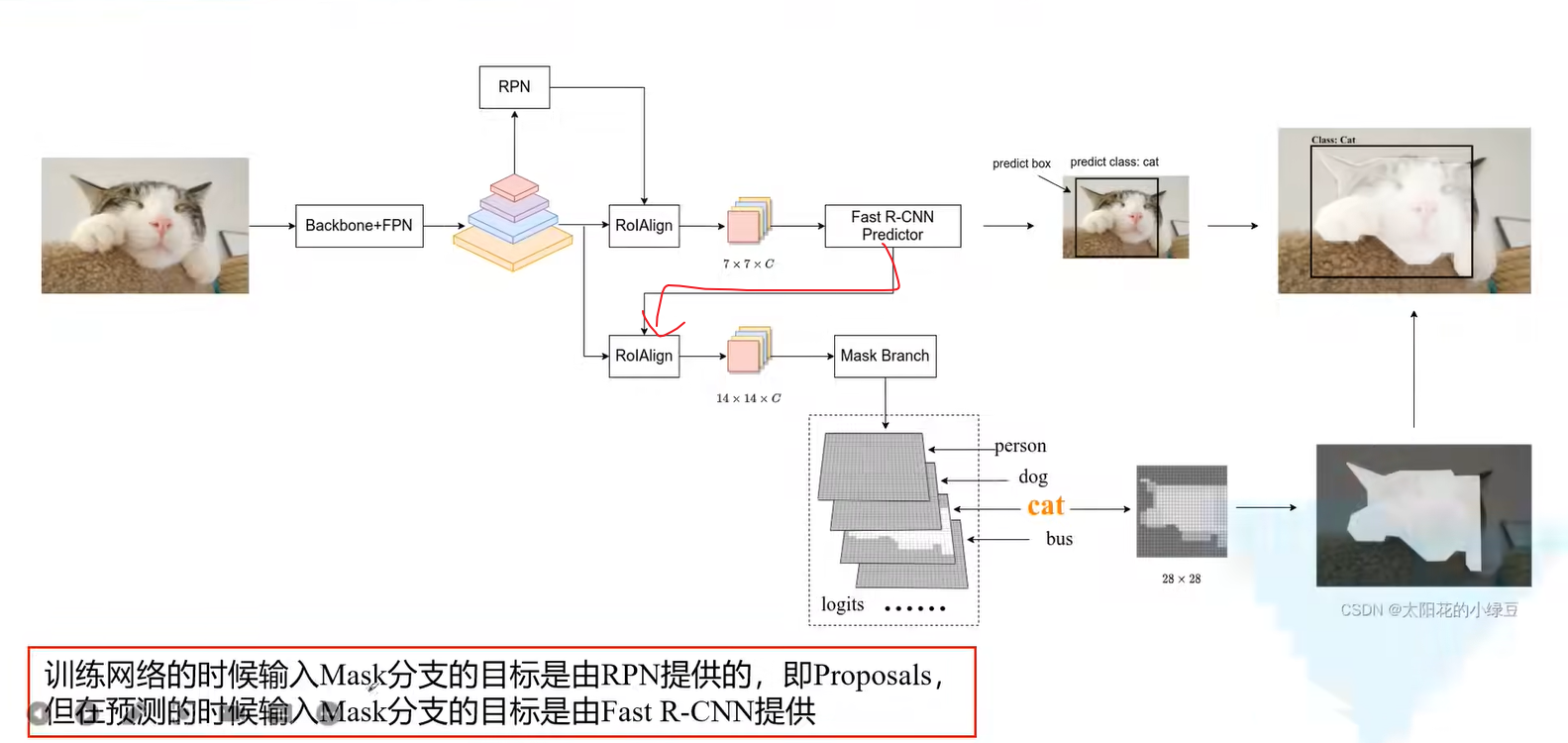
值得注意的是,如图红线部分,先是通过Fast_RCNN Predictor得到一个proposal,然后将其送给Mask branch前面的RolAlign,也就是说,只有一个proposal进入了此branch,但是这也导致了模型的实时性不好(是顺序进行的,没法并行计算)。
由于目前还没有去更新代码部分,这里的记录会有些生硬,后面会结合代码进行更加详细的说明。
Yolact
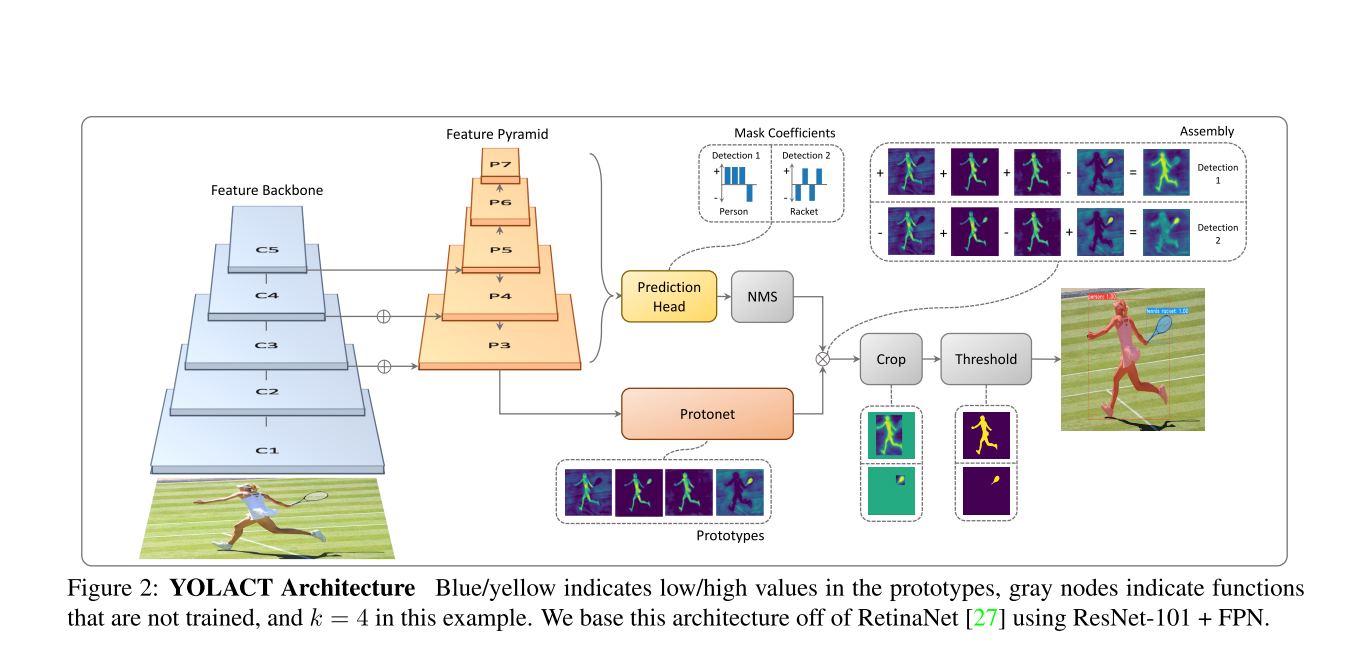
这个方法针对实例分割提出了one-stage方法,具有实时性(30fps)。例如Mask-RCNN这样的two-stage的方法,需要先生成一个预测框然后才能去预测mask。但是Yolact方法采用了一个Protonet的分支先生成32个"prototype Mask",然后再根据Prediction Head预测"prototype Mask"对应的"coefficient"(参数),将二者进行一个线性组合,这个公式对应上图中的Assembly部分:
代码
Yolact
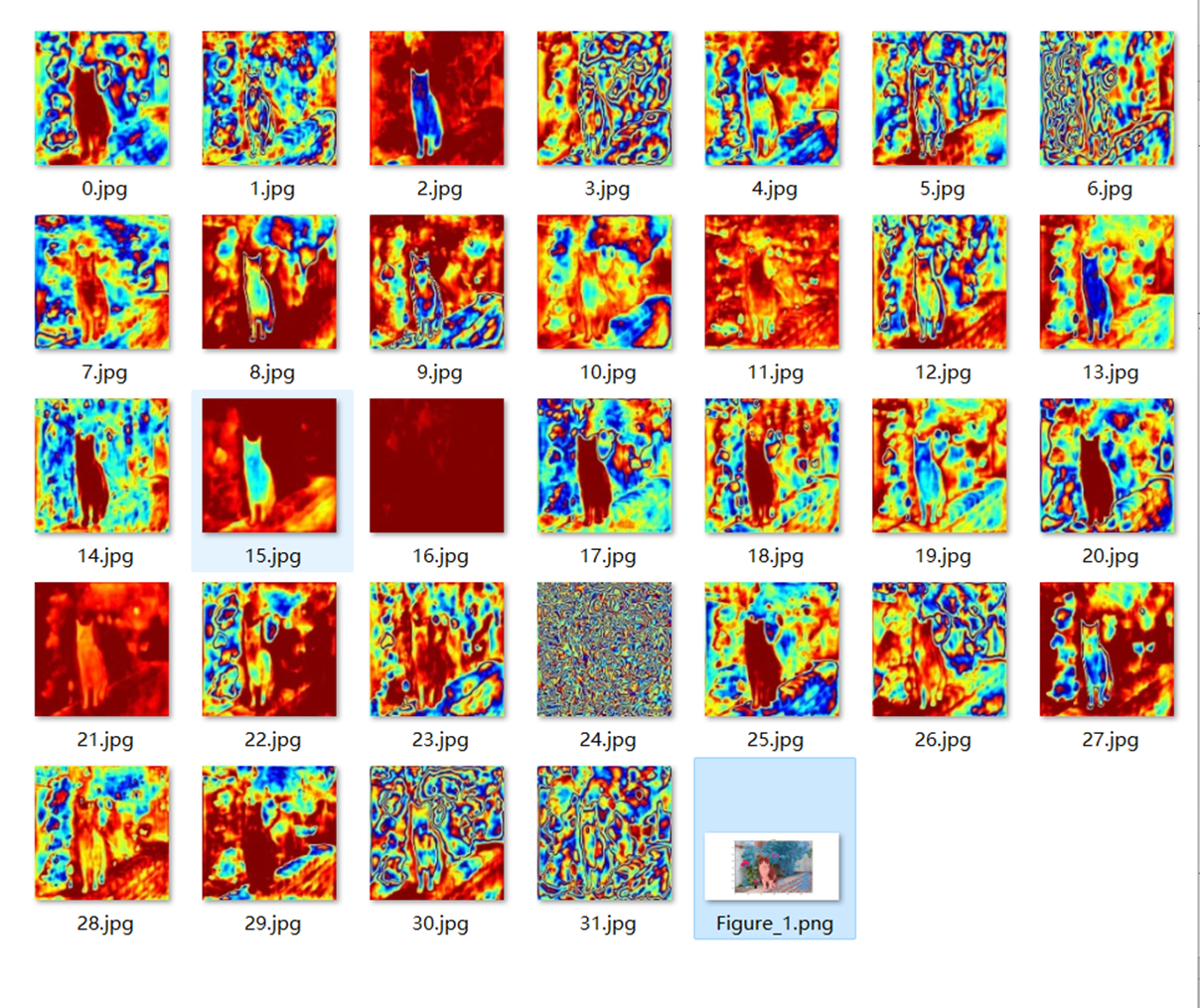
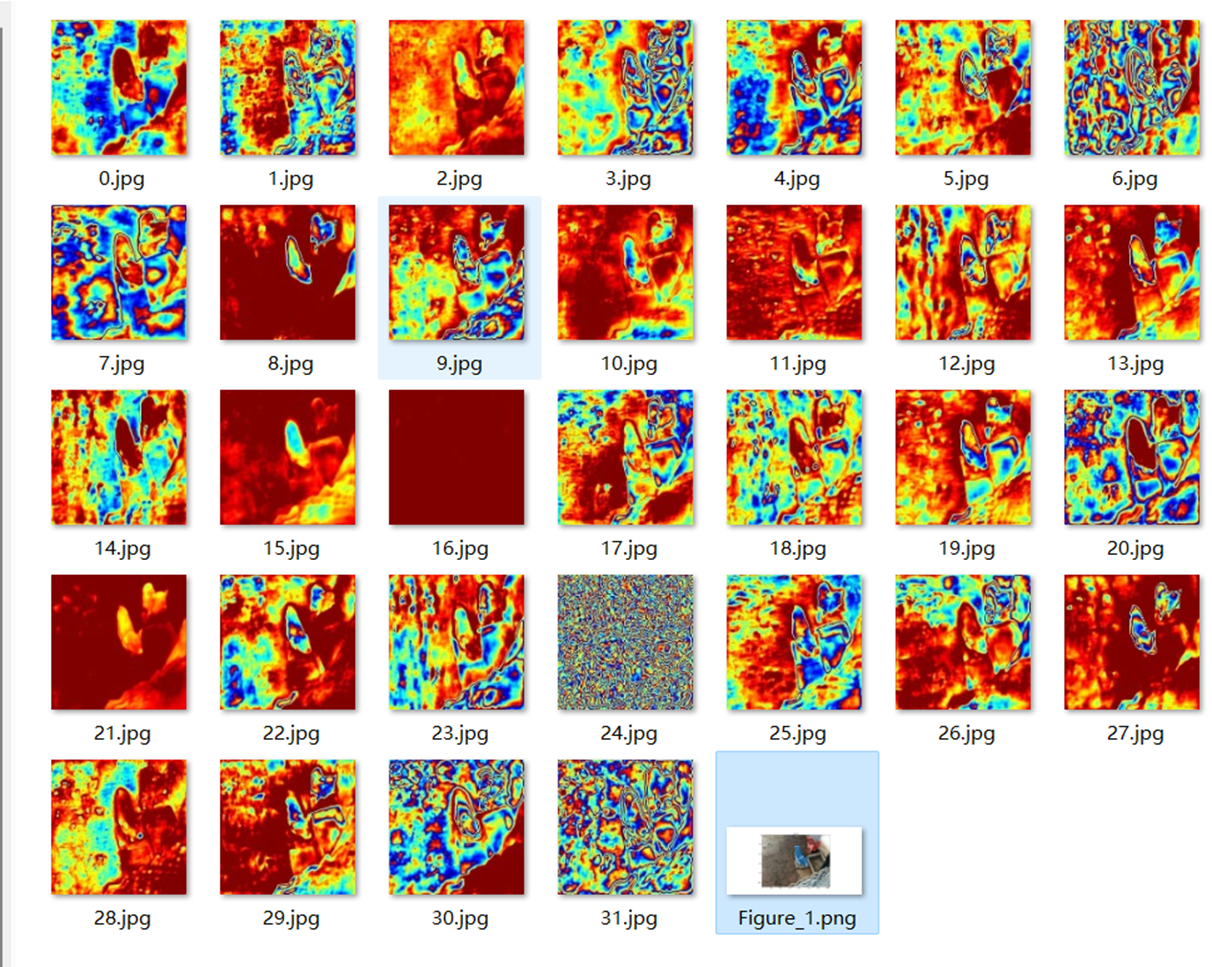
- Protonet网络生成的Prototype Mask
| Output | Prototypes |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Refer
MASK-RCNN详解:https://blog.csdn.net/qq_37541097/article/details/123754766
双线性插值:https://blog.csdn.net/qq_37541097/article/details/112564822
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16363484.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号