The surprising impact of mask-head architecture on novel class segmentation精讲
 这篇文章的主要工作是探究了不同的网络结构以及不同的训练方式对Mask RCNN的Mask分支泛化性的影响,同时这篇论文没有较多的数学公式,因此理解起来比较简单。
这篇文章的主要工作是探究了不同的网络结构以及不同的训练方式对Mask RCNN的Mask分支泛化性的影响,同时这篇论文没有较多的数学公式,因此理解起来比较简单。
大家好,这是我今天要讲的论文,它是2021年发表在ICCV上的一篇文章,这篇文章的主要工作是探究了Mask分支不同的网络结构以及不同的训练方式对以Mask RCNN为例的网络的Mask分支泛化性的影响,同时这篇论文没有较多的数学公式,因此理解起来比较简单。
Mask RCNN
我们需要先回顾一下MASK RCNN的工作流程,因为这篇论文的工作与此息息相关。
下面我将从MASK RCNN的测试,训练两个阶段来说一下。
-
测试
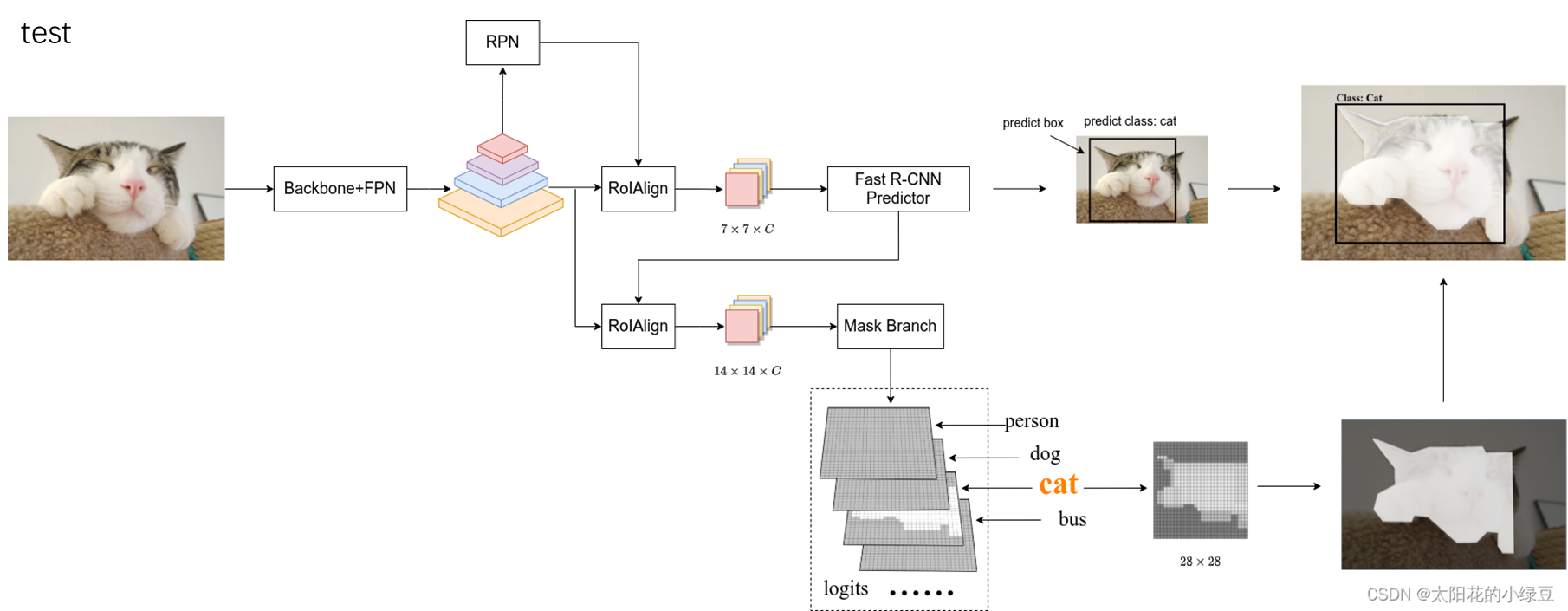
先看上面这个分支:
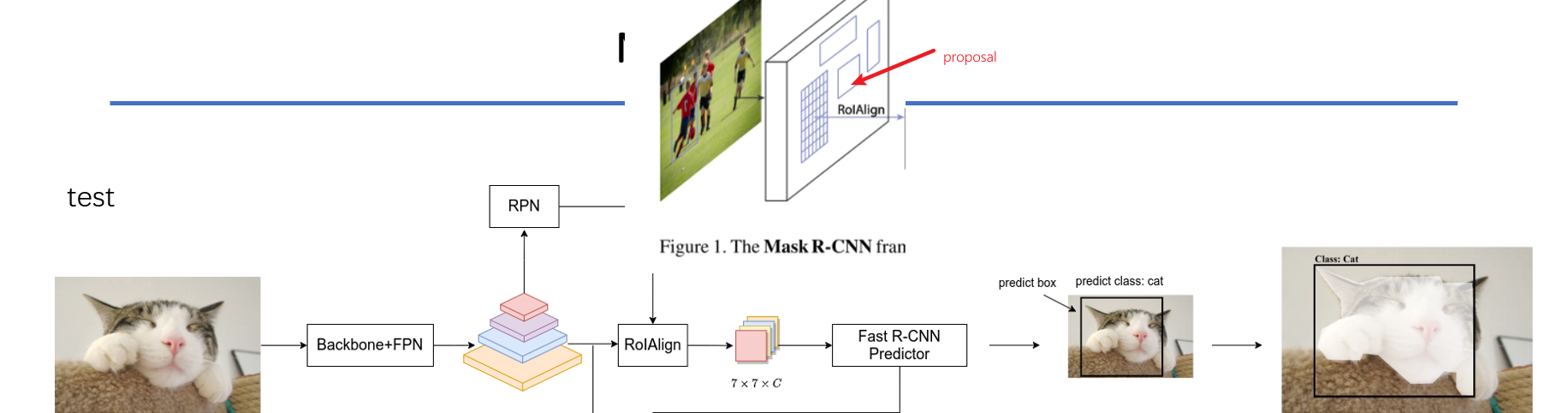
对于一张输入图片,我们先使用一个Backbone+FPN提取出这张图片的特征图,然后通过RPN去生成一些Proposals。RPN是一个神经网络,能够在特征图上提取出一些候选框。
然后再通过RolAlign。RolAlign将每个proposal对应的特征图采样成固定的大小,我们可以看后面的预测部分,类别预测,bonding box偏置预测(全连接),要求输入是固定的size,但proposal的尺寸都是不一样的,因此需要将他们变换成统一的大小。之后我们便可以通过这个特征图去预测出类别和bounding box偏置。
而对于Mask的预测,则需要Fast RCNN predictor分支预测出的bounding box和分类的传入,然后同样是在特征图上进行投影,通过RolAlign采样成固定的大小,然后预测出类别相关的MASK。备注:此处也正是因为这一步不是并行的,所以Mask RCNN的实时性不是很好,后面有人提出过新的模型比如 Yolact,去实现一个并行的预测,但这不是今天要讨论的内容。
-
训练
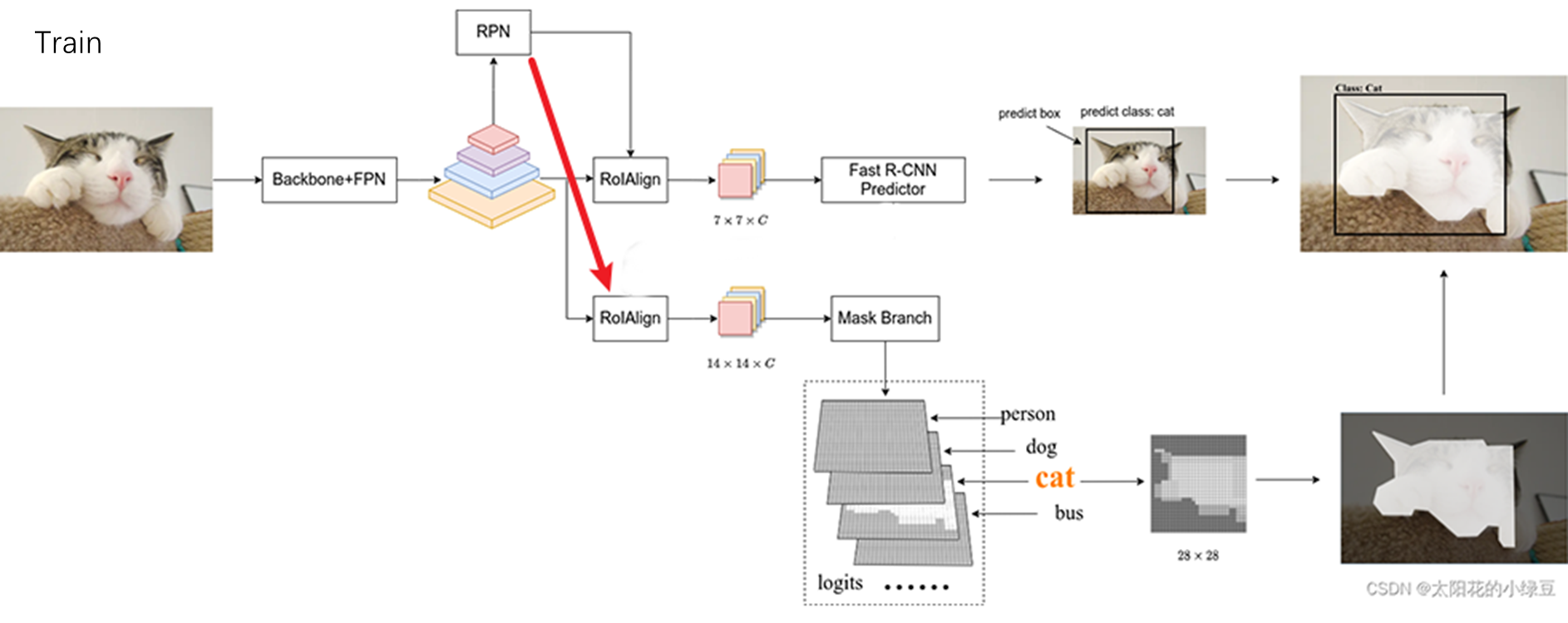
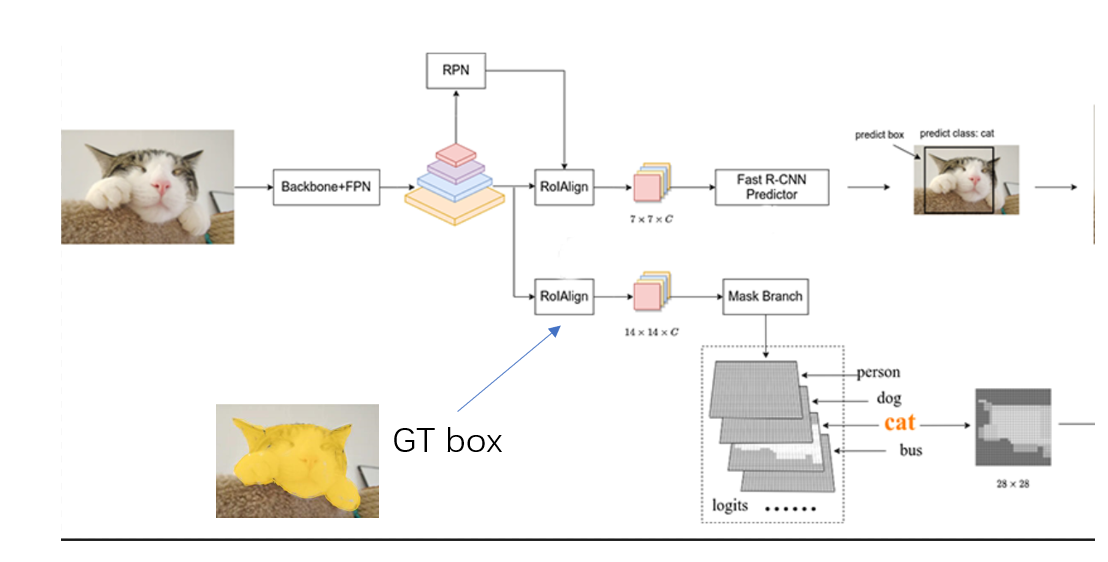
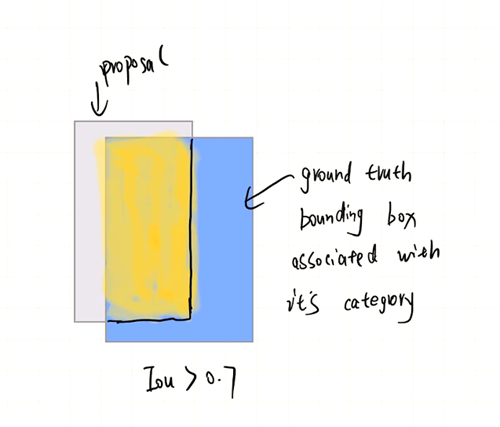
那么模型是怎么训练的呢?同样,RPN生成了很多的候选框,这些候选框和 ground truth bounding box会存在一个重叠,这个重叠程度的指标叫做Iou,我们假设有一个proposa与某一个ground truth bounding box重叠程度比较高。
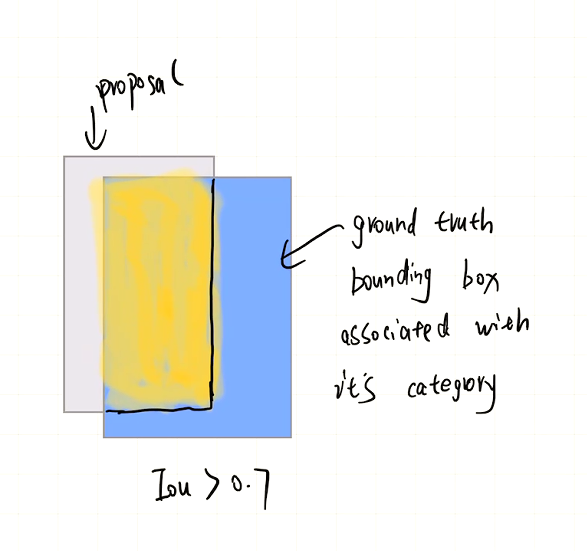
那么我们就可以默认这个proposal对应的ground truth是与它重叠的bounding box及其对应的类别和Mask。之后第一个分支的训练就比较好说了,预测出的bounding box 和类别与ground truth求一个loss。而对于Mask分支的训练,同理,对于每一个proposal,找到对应的Mask Ground truth,就是重叠部分对应的那些,然后据此模型获得训练。
训练跟测试的区别就是Mask Head传入的proposal来自哪里?测试是来自Fast R-CNN preditor,而训练则是来自RPN,也就是这个候选框生成网络。
Problem Definition
回顾了MASK RCNN的,我们看一下这篇论文试图解决一个什么问题:
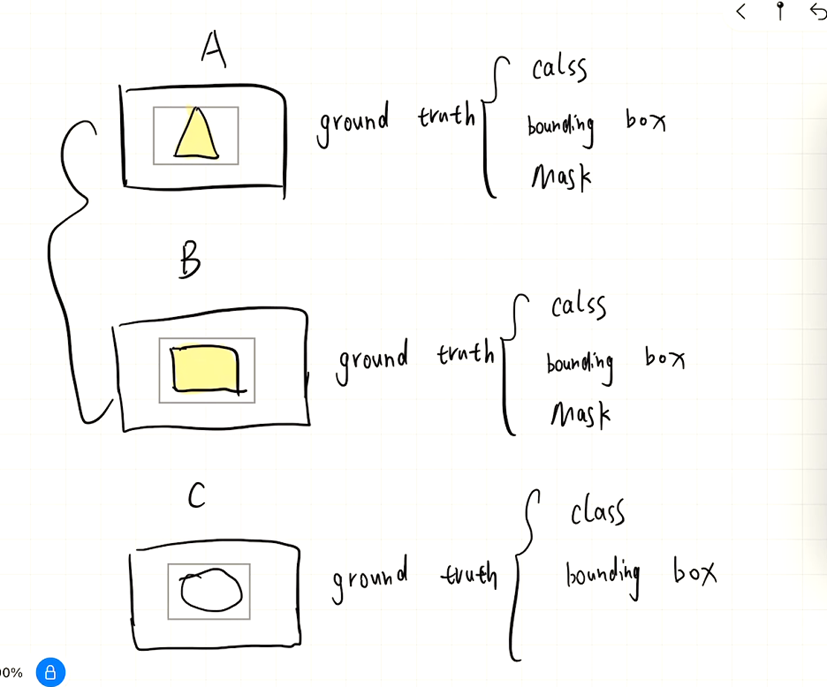
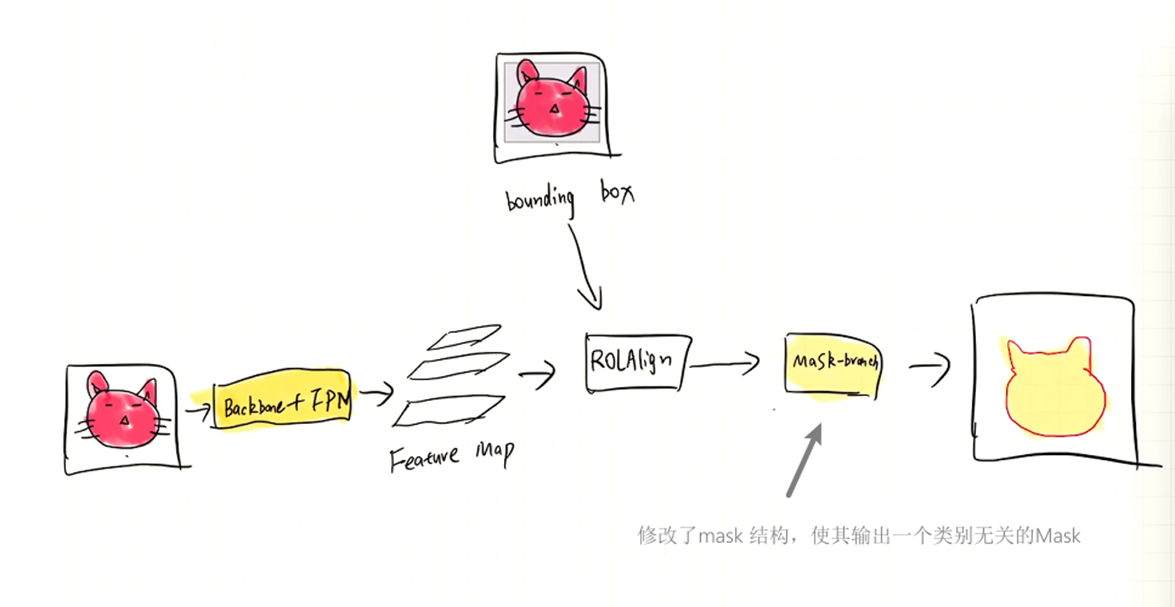
假设我们的数据集中有两种数据,一种是和a,b一样的,具有ground truth category,bounding box,mask,,另一种是c,只有ground truth category,bounding box,没有 Mask。解释一下为什么会出现这种情况,是因为Mask的标注很昂贵,但是bounding box的标注相对便宜。我们将这两种数据送入一个Mask RCNN进行训练,能否使得网络求解出C类数据的Mask(泛化性)。我们可以浅看一下下面这张图,它展示了Mask RCNN的Mask-head结构对泛化性的影响。

Key idea
然后就是本文的核心了。作者提出了两种如何去解决Mask head泛化性问题的途径:
-
Train Mask head only with only ground truth box
Croped GT box and proposals GT only 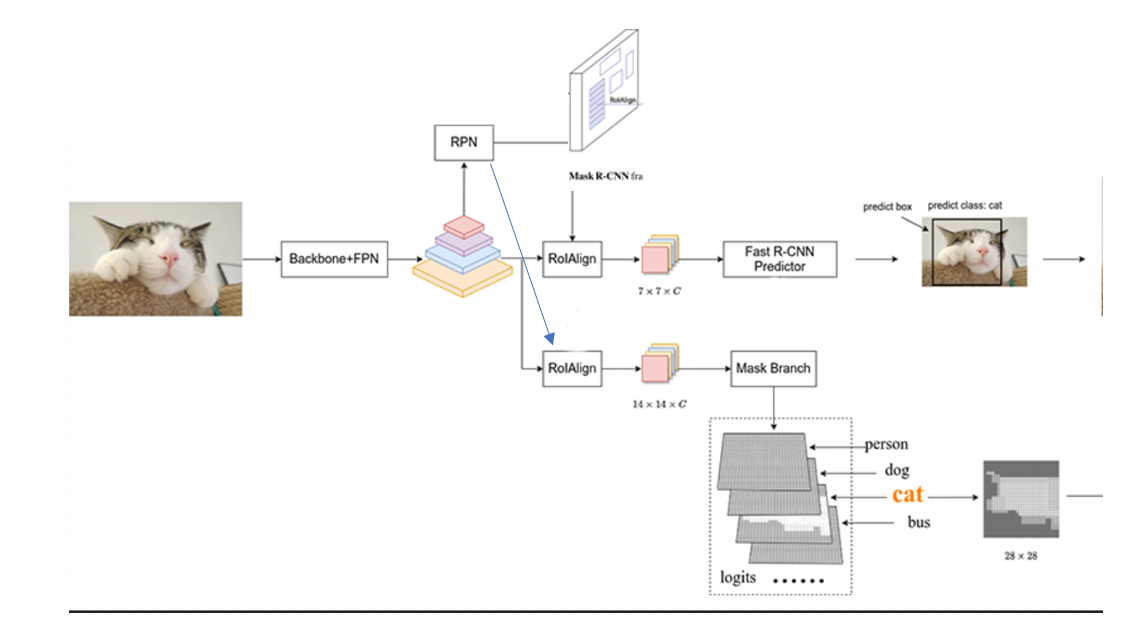
回忆起之前的Mask分支的训练方式,Mask head的训练数据来自大量的 noisy proposals and cropped GT bounding box,论文指出这种训练方式会损坏Mask head的泛化性。而只使用GT box的训练方式意思是:只使用GT box 在特征图上投影,然后通过ROlAlign采样成固定大小的 Feature map,然后预测出特征图,在结合GT box 对应的 GT Mask求loss进行训练。
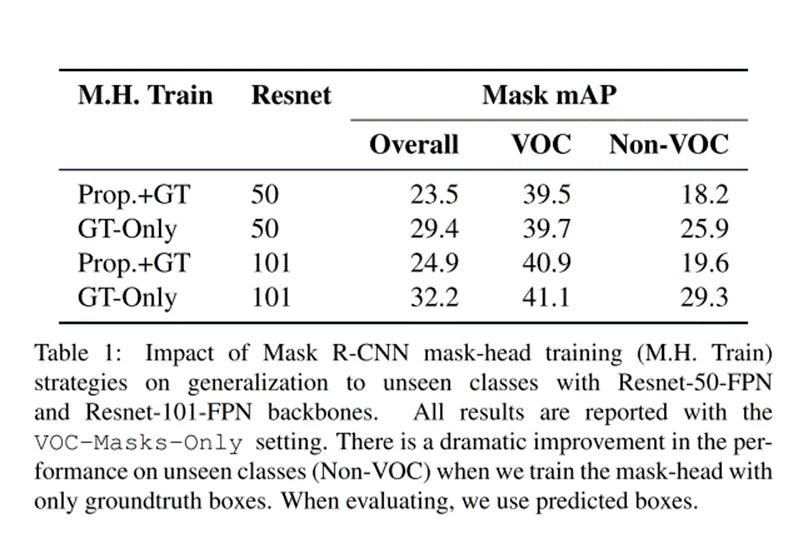
我们可以看一下论文给出的实验数据,第一列是不同的方式训练出的Mask RCNN,第二列是不同的backbone,第三列的第二个子列是AB类上的表现,相差不大,第三列的第二个子列是c类数据上的表现,相差很大,GT only提升了8个百分点。
- Mask head architecture become deeper
回到图1,作者修改了Mask branch部分的深度,来证明网络深度对模型结果的影响。这里值得注意的是,如果我们的数据集只有AB类数据,并且不追求在新的类别上的Mask的泛化性,则不需要较深的Mask head的网络结构。

Only Mask Head
 |
 |
|---|
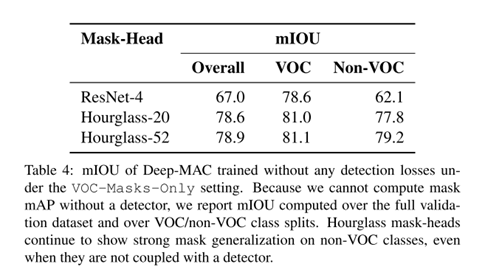
作者训练了一个类别无关的Mask 提取器,证明Mask branch的深度对泛化性的影响。自然是较深的网络泛化性好。
Code
链接:https://google.github.io/deepmac/#code
| 原图 |  |
 |
 |
|---|---|---|---|
| MASK |  |
 |
 |
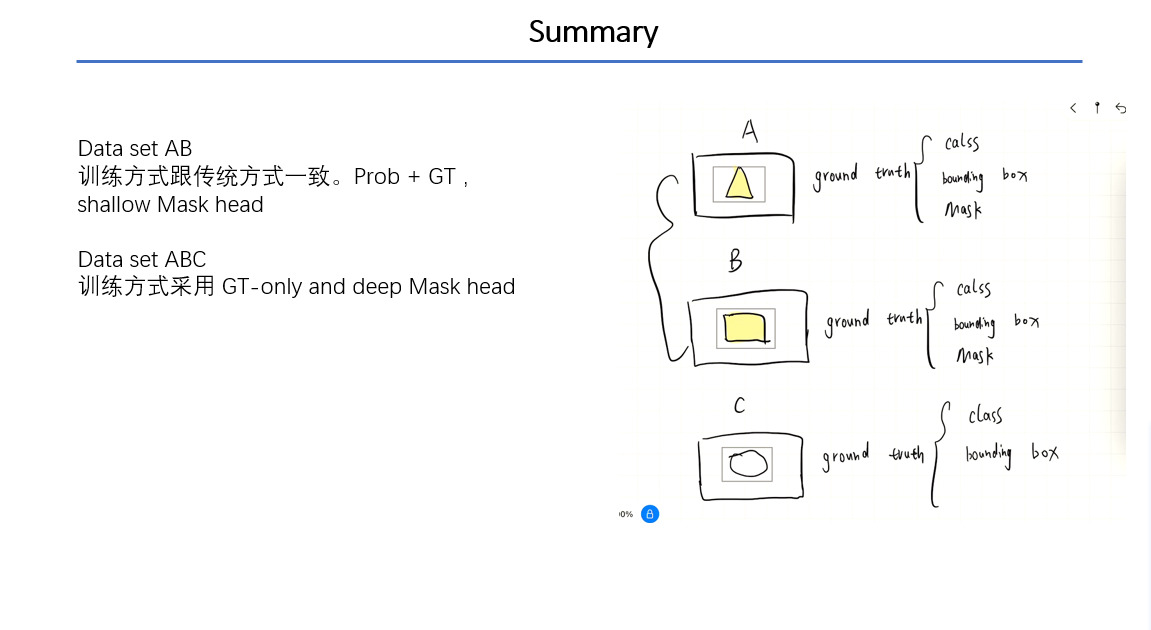
Summary
Refer
欢迎留言讨论
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16348713.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号