Momentum Contrast for Unsupervised Visual Representation Learning论文精读
 介绍一下大名鼎鼎的MoCo
介绍一下大名鼎鼎的MoCo

本篇博文将要介绍大名鼎鼎的MoCo,不过在正式开始介绍MoCo之前,我想先介绍一下MoCo诞生的背景,方便对MoCo精髓之处的理解。
Birth of MoCo
Supervised Learning
在MoCo诞生之前,CV界的研究依然是以监督学习(Supervised Learning)为主,举个简单的例子,图像分类任务,我们在许多标注好标签的数据上(如下图),训练一个分类器(ResNet)。

| ResNet | 去除Affine层 |
|---|---|
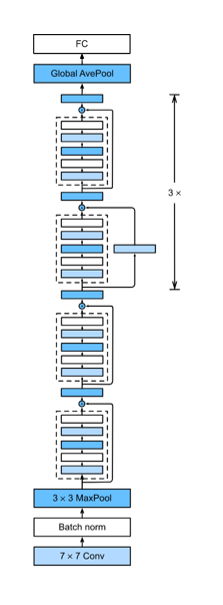 |
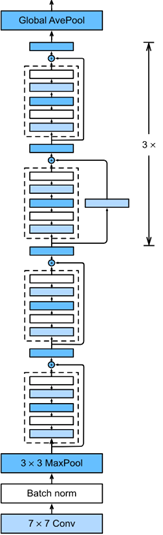 |
训练好这个分类器之后,我们可以去除掉最后一层的Affine层,这样就得到了一个特征提取器,就拿ResNet-18举例,去除Affine层之后,得到的输出是一个512维的向量。我们可以用这个预训练好的模型,当做一个特征提取器,在很多的下游任务(Downstrem Task),比如检测、分割、人体关键点检测中使用。
Contrastive Learning
如何使得这个特征提取器提取到的特征更加具有代表性(discriminative),对比学习应运而生。在这里,简单解释一下对比学习。
-
朴素的
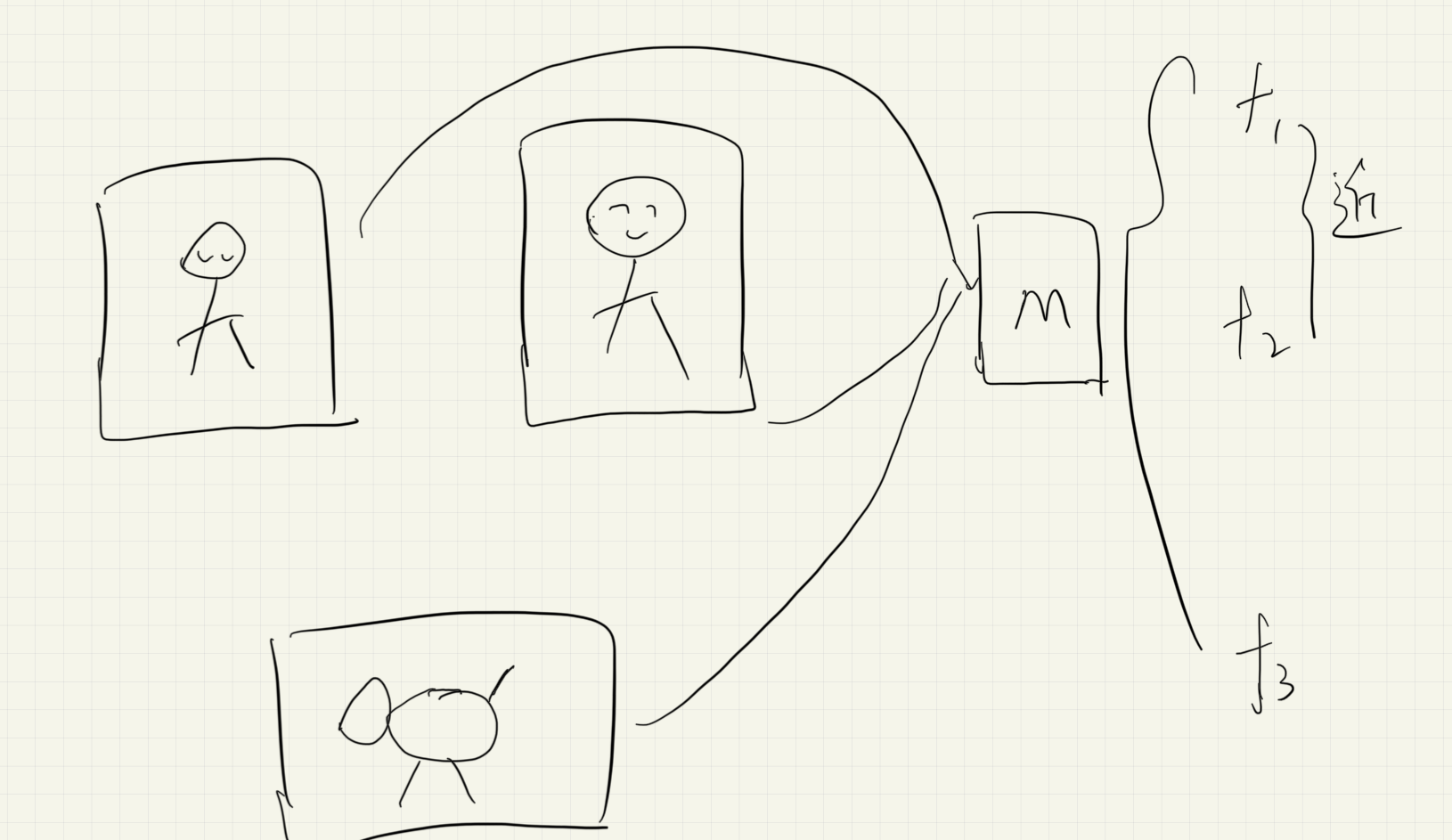
上图中有两个人,一只小狗,分别送入M这个模型中得到他们对应的特征向量\(f_1,f_2,f_3\),我们希望\(f_1,f_2\)尽可能的相近,因为二者的语义信息比较类似,同时与\(f_3\)尽可能的远。
- 专业的
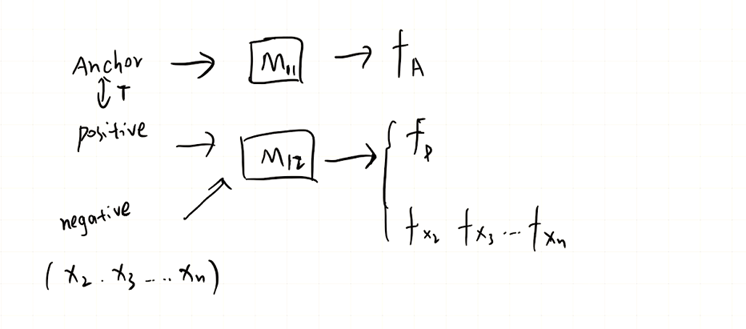
Anchor:基准点,Positive:正样本;Negative:负样本。这里模型的一般步骤是,将Anchor送入\(M_{11}\)这个模型,正负样本都送入\(M_{12}\)这个模型得到对应的特征向量,然后送入一个LossFuntion进行一个惩罚,因此模型得到了训练。论文Related Work中提到的主要有这三类。

不过这也并不是今天介绍的重心,下面要着重介绍MoCo是如何通过无监督的动量对比学习方法去训练一个特征提取器的。
MoCo
Dictionary
首先说明一下,MoCo认为对比学习可以看做是一个构建一个离散词典方法,这个词典是动态的,并且随机采样的。
Momentum Contrast From the above perspective, contrastive learning is a way of building a discrete dictionary on high-dimensional continuous inputs such as images. The dictionary is dynamic in the sense that the keys are randomly sampled, and that the key encoder evolves during training.
这句话我结合原文的理解大致如下:
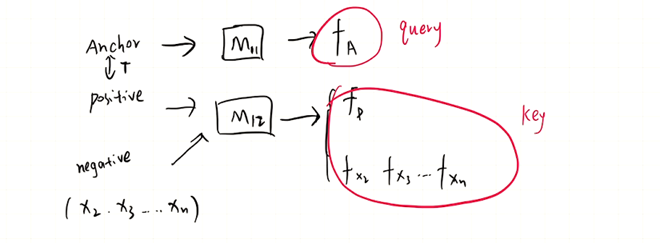
MoCo将\(f_A\)看做是字典的一个query,\(f_p,f_{x_2},f_{x_3}...f_{x_n}\),看做是字典的key。
那么就可以简单地整合成如下的样式:
\(q\)就是\(f_A\),\(k_1\)是正样本对应的特征向量,\(k_2....k_n\)对应负样本的特征向量。下面我们将以字典的视角来介绍MoCo这个方法做了什么,其中公式(1)会反复提及。
如上所述,我们构建了一个字典,同时还记得我们之前最初的愿望吗,我们希望我们的模型提取到的特征能够更加discriminative。
那么正如论文所说,我们对字典的提出了如下两个要求:
1.The dictionary should be Large
2.Consistent: keys in the dictionary should be represented by the same or similar encoder so that their comparisons to the query are consistent.
之后文中指出,以往的基于对比学习的学习方法,都或多或少地被如上两点限制了。
Limits of the early learning method
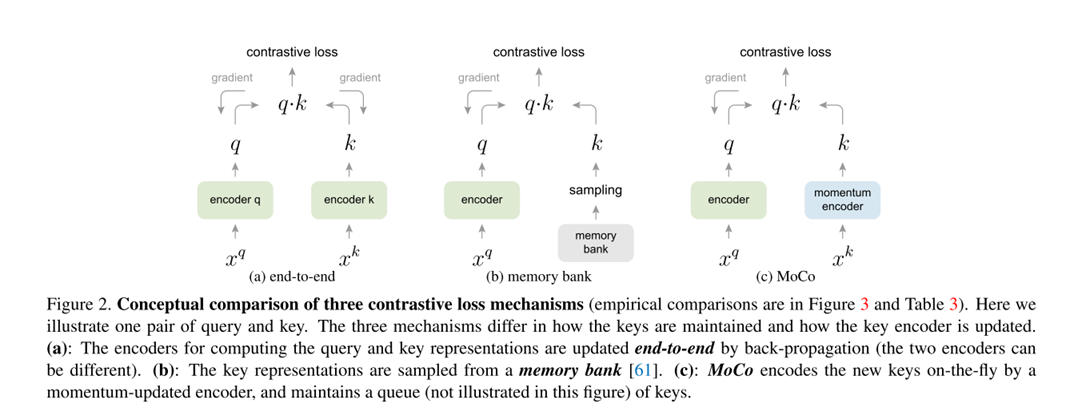
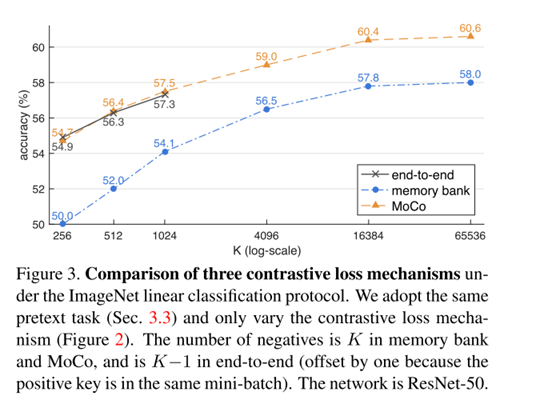
如上图所示,作者将早期的学习方法分为了三类。这里简单介绍一下(a)end-to-end,它保证了字典key一致性,但却无法实现大字典。
\(q \quad \{{k_1,k_2,...k_n}\}\),所有的k都来自同一个编码器(consistent),但是由于显存的限制,使得输入的\(x^k\)的数量无法太多,比如\(x^k\)是图片的时候。(b)memory bank方法与a相反,可以实现大字典,但却牺牲了一致性。
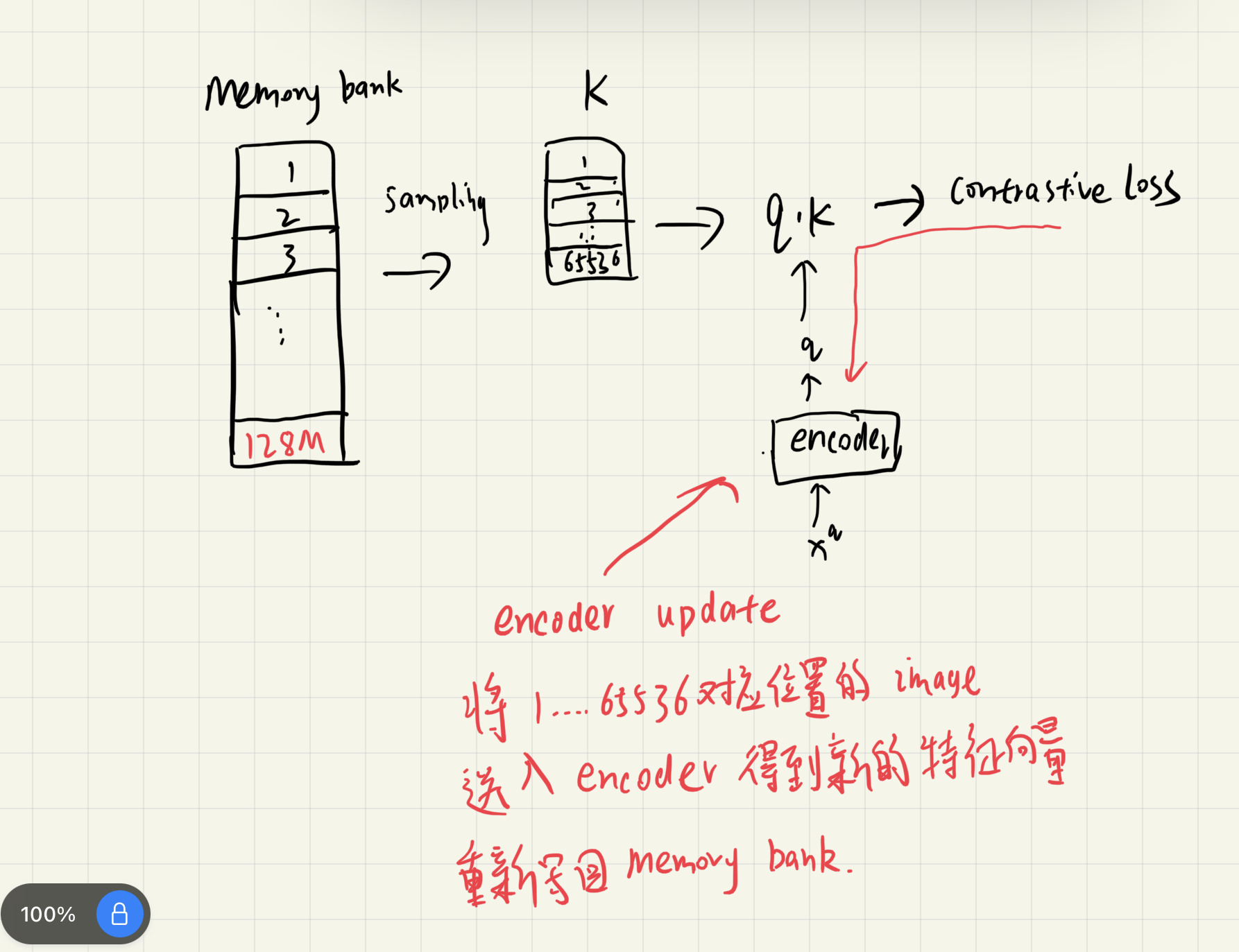
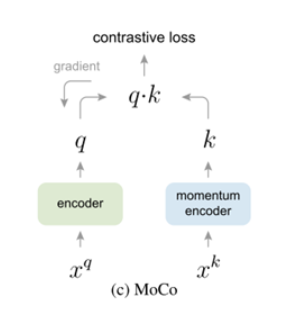
那么基于MoCo对比的学习方法,是如何二者兼得的呢?
Introduction
MoCo使用一个queue,实现large dictionary;Momentum update实现key encoder的更新。不过由于MoCo本质上是一种学习的方法,所以论文中并没有给出一个结构图,取而代之的是作者给出了MoCo的伪代码去帮助我们理解。
-
loss function of MoCo
是不是有点眼熟?这个和交叉熵损失函数长得差不多。其中\(\tau\)是一个超参数,可以先不用管它。
改写成写成如下形式(便于理解):
再拆分一下,就得到了一个Softmax分类器。
因此这个地方作者最终把问题看做了一个\(K+1\)类的分类问题,损失函数希望\(q\)与\(k_+\)尽可能地接近,转换到分类的视角也就是loss函数希望\(k_+\)对应位置的概率最大。
Pseudocode

动量更新Key encoder
Results
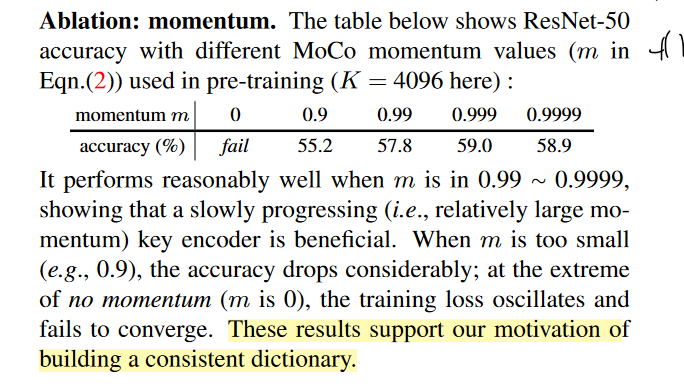
作者做了一些实验,证明了基于MoCo的无监督学习方法效果更好,同时得到的预训练模型在一些下游任务上也能取得不错的效果。
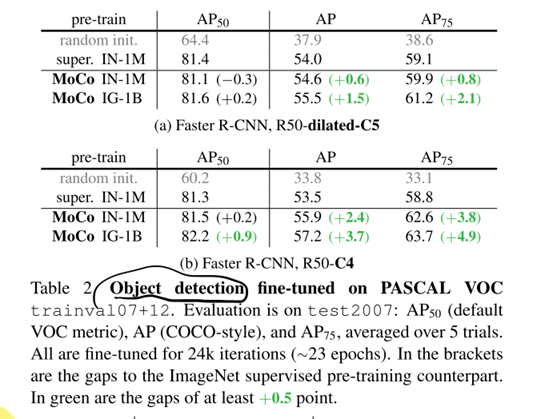
但是MoCo也并不是在所有的任务上都超越了前人,他更像是打通了有监督学习和无监督学习的壁垒。

Summary
-
Use Queue and Momentum update to create a large and consistent dictionary.
-
MoCo largely closes the gap between unsupervised and supervised representation learning in many computer vision tasks.
使用大量的无标签的图片进行无监督训练提供了可能。
-
设置新的代理任务是否能帮助模型性能提升,当图片数量从百万级到千万级时,性能提升不明显。
MoCo’s im-provement from IN-1M to IG-1B is consistently noticeable but relatively small, suggesting that the larger-scale data may not be fully exploited. We hope an advanced pretext task will improve this. Beyond the simple instance discrimination task [61], it is possible to adopt MoCo for pretext tasks like masked auto-encoding, e.g., in language [12] and in vision [46]. We hope MoCo will be useful with other pretext tasks that involve contrastive learning.
-
无监督学习方法与有监督训练得到的预训练模型在参数分布上可能有很大不同,比如当MoCo训练得到的预训练模型在向ImageNet的图像分类任务扩展时,学习率居然要设置为30才能奏效。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/16032269.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号