SuperPoint: Self-Supervised Interest Point Detection and Description 论文笔记
 SuperPoint论文阅读
SuperPoint论文阅读
Introduction
这篇文章设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子。相比于patch-based方法,本文提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子。本文提出了一种单映性适应(Homographic Adaptation)的策略以增强特征点的复检率以及跨域的实用性(这里跨域指的是synthetic-to-real的能力,网络模型在虚拟数据集上训练完成,同样也可以在真实场景下表现优异的能力)。
SuperPoint Architecture
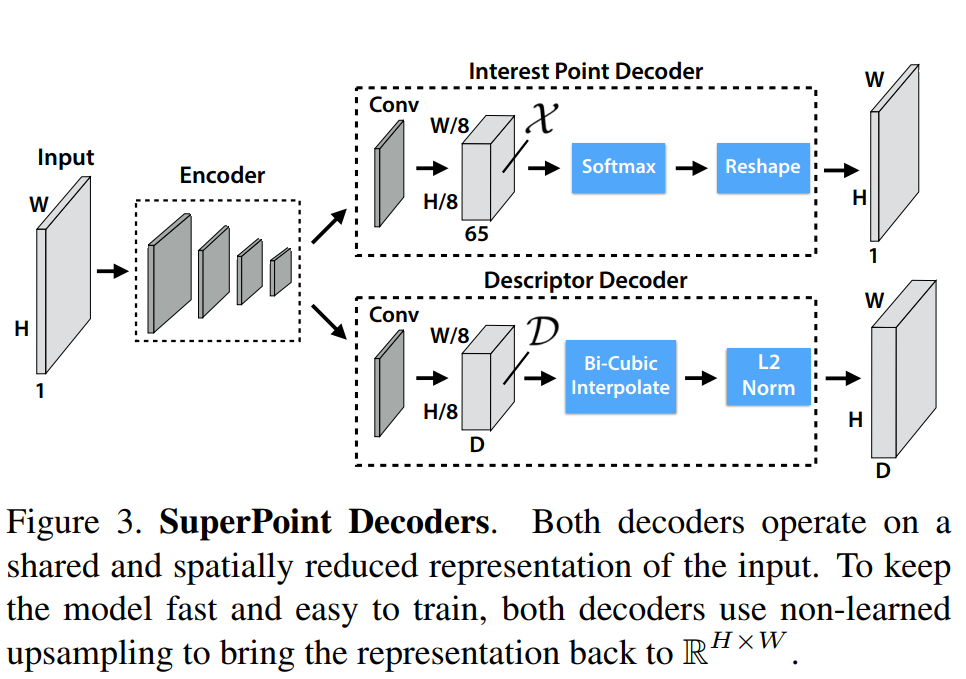
1 Shared Encoder
这是一个VGG-style的网络层,将原始输入图片进行一系列的处理后,将原始输入图片的尺寸变成\(H_c=H/8,W_c = W/8\)
2 Interest Point Decoder
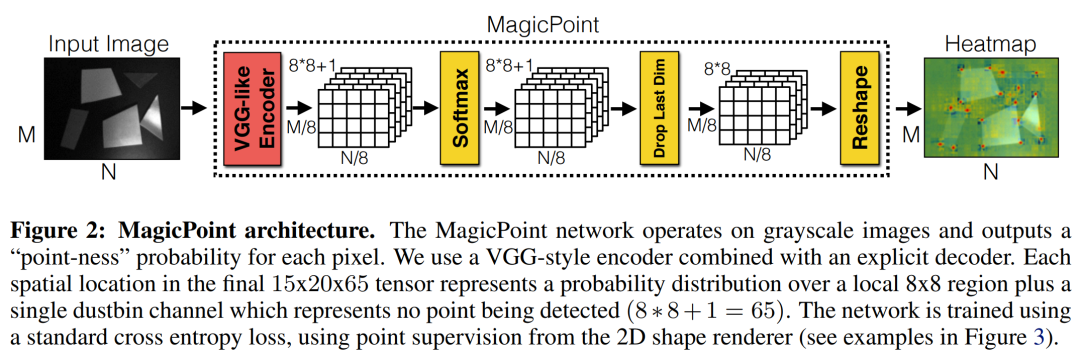
The 65 channels correspond to local, non-overlapping 8 × 8 grid regions of pixels plus an extra “no interest point” dustbin.
After a channel-wise softmax, the dustbin dimension is removed and a RH c ×W c ×64 ⇒ RH×W reshape is performed.
65个通道对应原始图片\(8\times 8\)的网格,加上一个非特征点dustbin,通过在channel维度上做softmax,非特征点dustbin会被删除,同时会做一步图像的reshape (使用的是一个叫做\(子像素卷积^{[1]}\)的方法),得到一个和输出图片size相同的概率图。
3 Descriptor Decoder
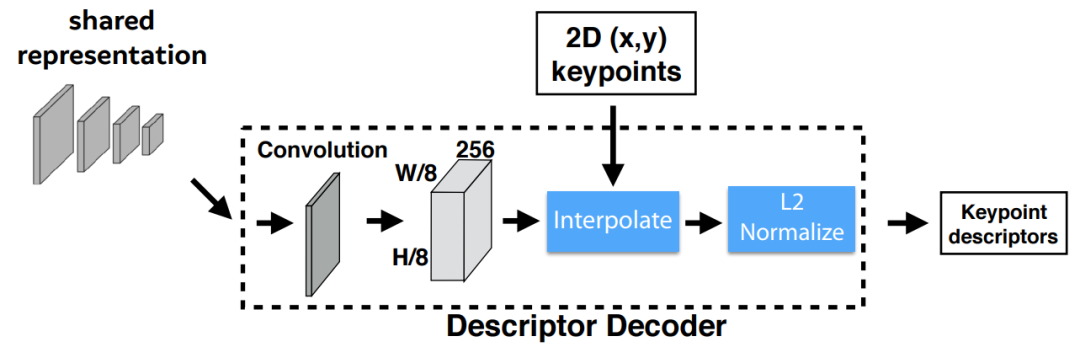
首先利用类似于UCN的网络得到一个半稠密的描述子(此处参考文献\(UCN^{[3]}\) ),这样可以减少算法 训练内存开销同时减少算法运行时间。之后通过双三次多项式揷值得到其余描述,然后通过 L2normalizes 归一化描述子得到统一的长度描述。特征维度由 \(\mathcal{D} \in \mathbb{R}^{H_{c} \times W_{c} \times D}\) 变为 \(\mathbb{R}^{H \times W \times D}\) 。
4 Loss Functions
可见损失函数由两项组成,其中一项为特征点检测loss\(\mathcal{L}_{p}\) ,另外一项是描述子的loss\(\mathcal{L}_{d}\)。
前者使用的是交叉熵误差函数:
The interest point detector loss function \(\mathcal{L}_{p}\) is a fully convolutional cross-entropy loss over the cells \(\mathbf{x}_{h w} \in \mathcal{X}\). We call the set of corresponding ground-truth interest point labels \(Y\) and individual entries as \(y_{h w}\). The loss is:
where
描述子的损失函数:
where
其中对应每个cell的s是这样定义的:
Synthetic Pre-Training
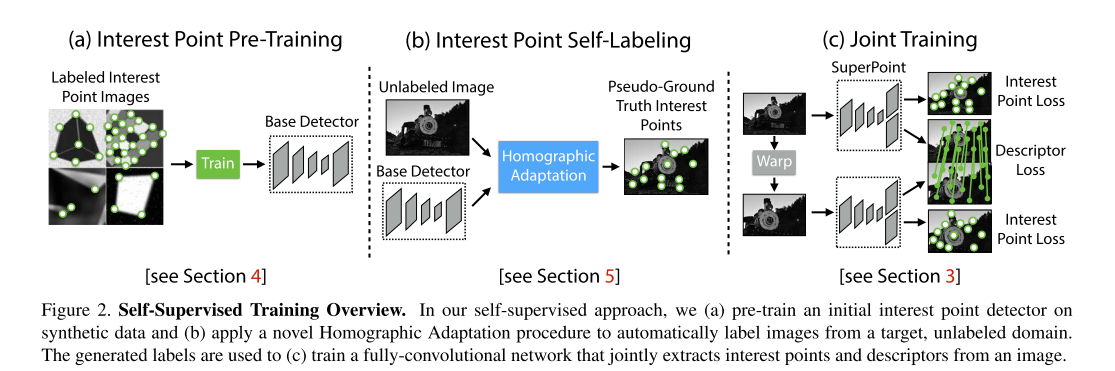
网络的训练分为三个步骤:
-
第一步是采用虚拟的三维物体作为数据集,训练网络去提取角点,这里得到的是
BaseDetector即MagicPoint -
使用真实场景图片(MS-CoCo),用第一步训练出来的网络
MagicPoint+Homographic Adaptation提取角点,这一步称作兴趣点自标注(Interest Point Self-Labeling) -
对第二步使用的图片进行几何变换得到新的图片,这样就有了已知位姿关系的图片对,把这两张图片输入SuperPoint网络,提取特征点和描述子,然后计算loss,进行训练。
这里重点介绍一下Homographic Adaptation
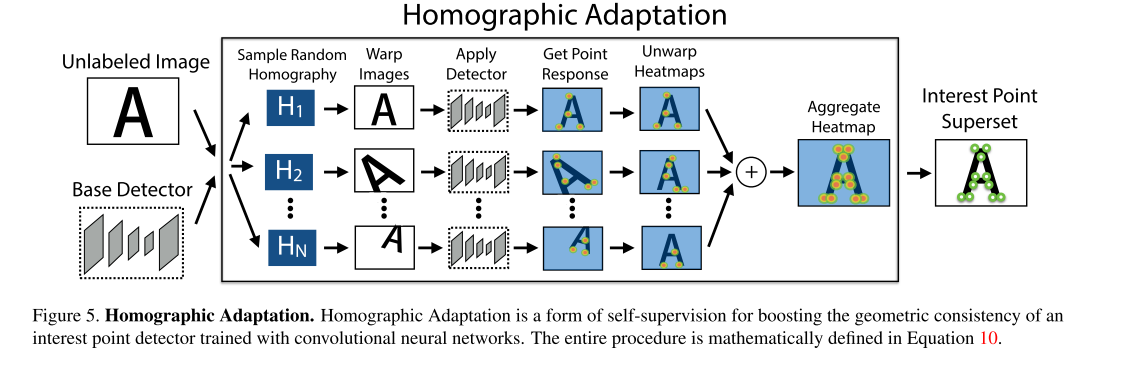
针对Magicpoint在真实数据上的缺点,作者提出了Homographic Adaptation,也就是把真实图片做几次单应变换,将这些单应变换的结果都输入Magicpoint,然后将检测到的特征点投影到原始的图片上,合起来作为最后的特征点真值。这样使检测到的特征点更丰富,也具备了一定的单应不变性。然后将通过这个步骤得到的图片结合原图片送入到SuperPoint进行训练。
Running
观察到论文的作者在GitHub上开源了SuperPoint的\(代码^{[2]}\),拉下来跑了一下。
| input | output |
|---|---|
 |
 |
 |
 |
真的牛!!!!
Conclusion
作者先使用一个合成的数据集训练MagicPoint,然后再结合Homographic Adaptation使其在真实世界里的表现得到了提升。同时特征点的检测也可以使用深度学习的方法来解决了。并且取得了较传统的方法很大的性能提升。
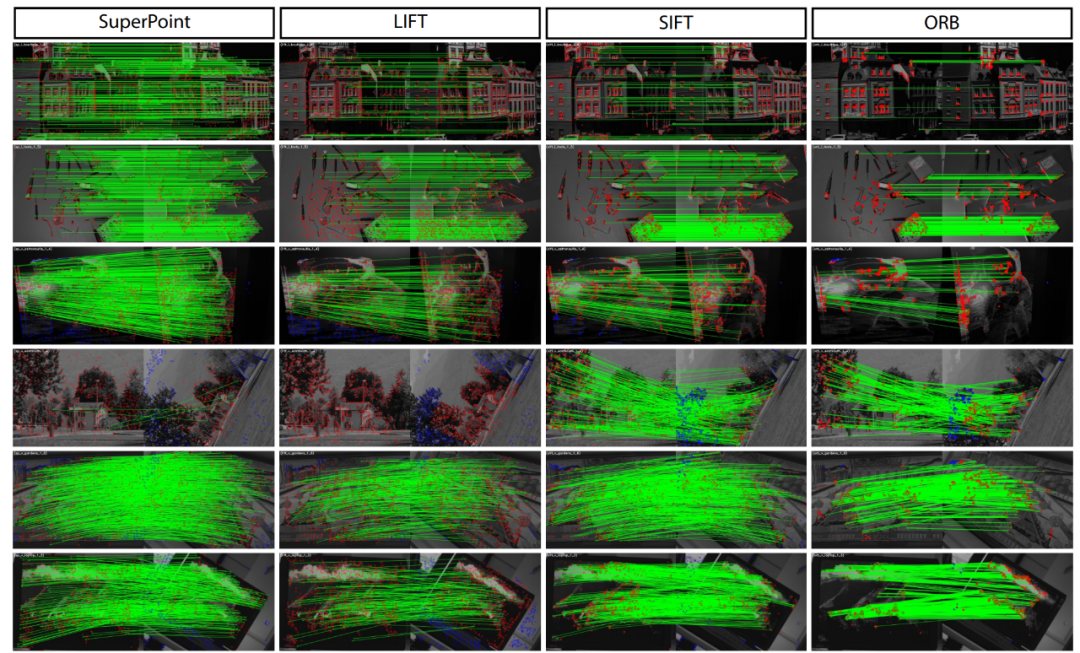
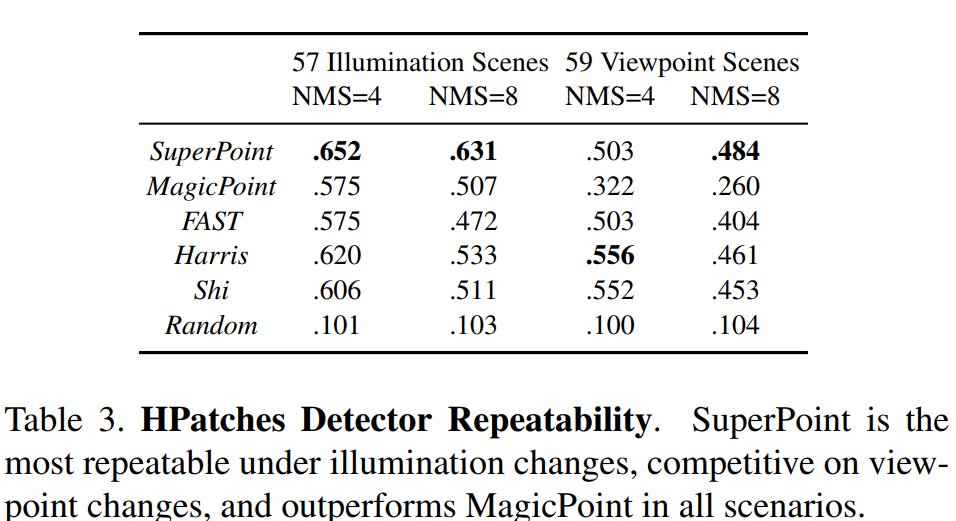
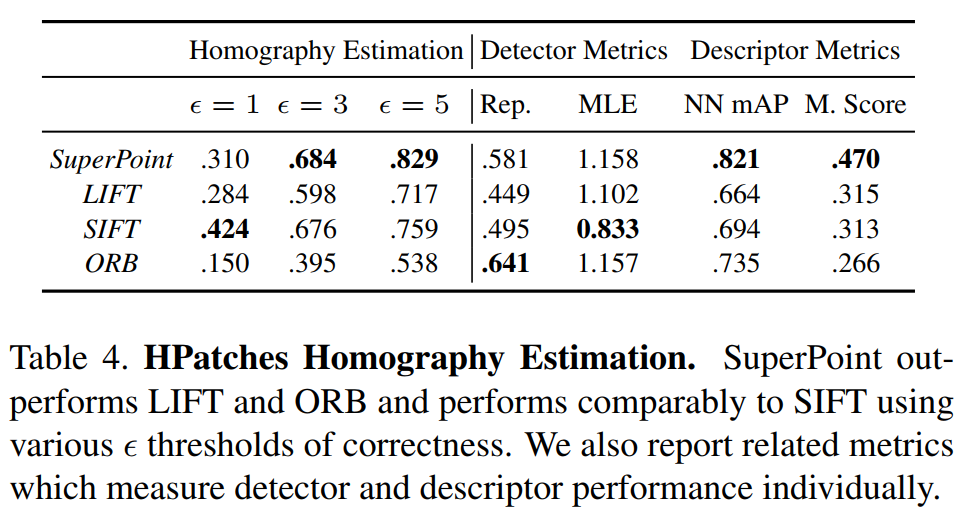
Refer
[1]子像素卷积:https://blog.csdn.net/leviopku/article/details/84975282
[2]superpoint:https://github.com/magicleap/SuperPointPretrainedNetwork
[3]C. B. Choy, J. Gwak, S. Savarese, and M. Chandraker. Universal Correspondence Network. In NIPS. 2016.2, 3, 8
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15708077.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号