Learning local feature descriptors with triplets and shallow convolutional neural networks 论文阅读笔记
 Learning local feature descriptors with triplets and shallow convolutional neural networks
Learning local feature descriptors with triplets and shallow convolutional neural networks
题目翻译:学习 local feature descriptors 使用 triplets 还有浅的卷积神经网络。读罢此文,只觉收获满满,同时另外印象最深的也是一个浅(文章中会提及)字。
1 Contribution
这篇论文主要做的贡献有:
- 提出了一种复杂度更小的triplets,更浅,计算度复杂小,表现也很好。
- 并且借助一种 in-triplet mining的训练方法,降低了挖掘hard negatives的复杂度提高了表现。
- 论文还介绍了两种不同的loss function在不同的任务下的表现。
下面将围绕这些贡献展开说明:
2 Learning with pairs
这一小节作者介绍了一下孪生神经网络的训练方法。
\(\ell=1\)代表\(x_1,x_2\)是positive pairs,反之则是negative pairs。同时当模型训练到一定程度,negative pairs所产生的loss就是0了,对模型的训练不起作用,因此之前[4]提出了mining hard negatives的方法来应对,具体可见我的上一篇博文,同时这种方法代价很高。
3 Learning with triplets
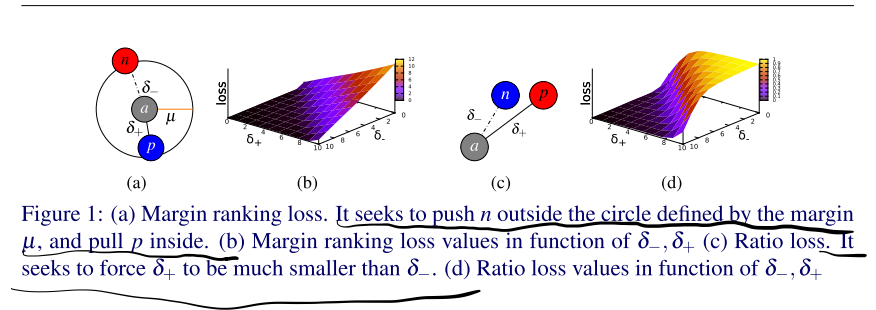
我们假设取样有\(\{a,p,n\}\),\(a\)和\(p\)来自同一个关键点的不同视角,\(a\)和\(n\)则来自不同的关键点,那么训练的目的是尽量使得\(a\)和\(p\)得到的特征描述更近,\(a\)和\(n\)得到的特征描述更远。因此我们可以定义\(\delta_{+}=\|f(\boldsymbol{a})-f(\boldsymbol{p})\|_{2}\) and \(\delta_{-}=\|f(\boldsymbol{a})-f(\boldsymbol{n})\|_{2}\)。
3.1 Two loss functions
-
Margin ranking loss
\[\lambda\left(\delta_{+}, \delta_{-}\right)=\max \left(0, \mu+\delta_{+}-\delta_{-}\right) \]我们可以观察到,当\(\delta_{-}>\delta_{+}+\mu\)时,\(loss>0\),模型得到训练。
-
Ratio loss
模型得到训练当 \(\frac{\delta_{-}}{\delta_{+}} \rightarrow \infty\).训练目标是尽可能让 \(\left(\frac{e^{\delta_{+}}}{e^{\delta_{+}+} e^{\delta_{-}}}\right)^{2}\) to 0 , and \(\left(\frac{e^{\delta_{-}}}{e^{\delta++e^{\delta}}}\right)^{2}\) to 1。
3.2 In-triplet hard negative mining with anchor swap
这篇论文的第一个令人拍手称快的点在这里!

类似的思想对Ratio loss同样适用。
3.3 Implementation details
这一小节主要介绍了,训练上的一些细节,模型结构很简单。

同时引用原文里的一句话,阐述了为何把模型设置的尽量简单。
Our motivation for such shallow network is to develop a descriptor for practical applications including those requiring real time processing. This is a challenging goal given that all previously introduced descriptors are computationally very intensive, thus impractical for most applications.
4 Experimental evaluation
这一节作者介绍了从两个方面评估模型的方法,一个是 ROC curves,另一个是mean average precision,刚开始不知道这两个指标是怎么来的,做什么的,查阅了参考小节里的文章,有了一个大致的认识,关于这两种评估方法的一些介绍引用原文:
The evaluation is done with two different evaluation metrics frequently found in the literature, patch pair classification success in terms of ROC curves [22], and mean average precision in terms of correct matching of feature points between pairs of images [16]. Note that these two metrics are of very different nature,the former measures how succesfull a classification of positive and negative patch pairs is, and the latter is evaluating the performance of a descriptor in nearest neighbour matching scenario where the task is to find correspondences in two large sets of descriptors.
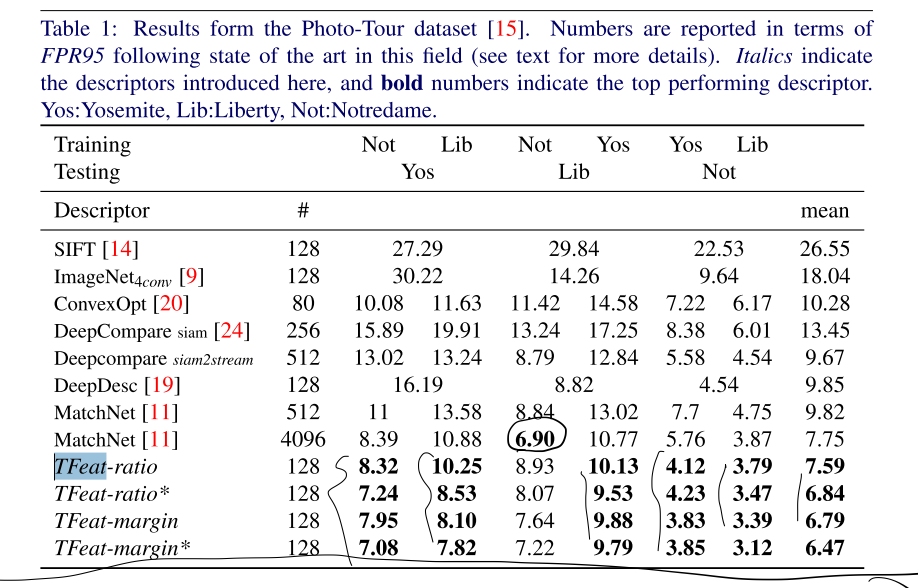
4.1 Patch pair classification
可以看到在相关数据集上的FPR95指数,TFeat(论文模型的名字)要表现更好:
4.2 Nearest neighbour patch matching
这一小节作者介绍了结合数据集的一些采样方法来计算precision-recall cruves,关于Map指标的一些相关介绍,可查阅附录,这里就不过多展开了
-
Ratio loss vs. margin loss
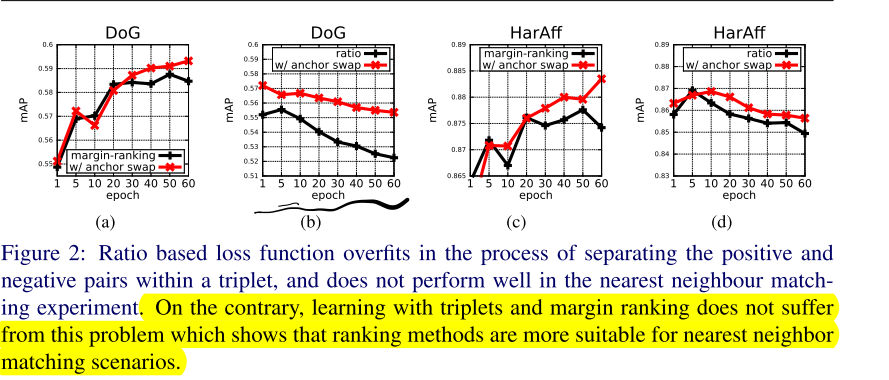
- 大致可以发现map值的变化随epoch的变化是比较缓慢的。
- radio loss 随着训练在Nearest neighbour patch matching上表现会**越来越差**
- 问:那这样说的话,Ratio loss除了在起点处略优于margin loss,在什么方面会比margin loss好呢?
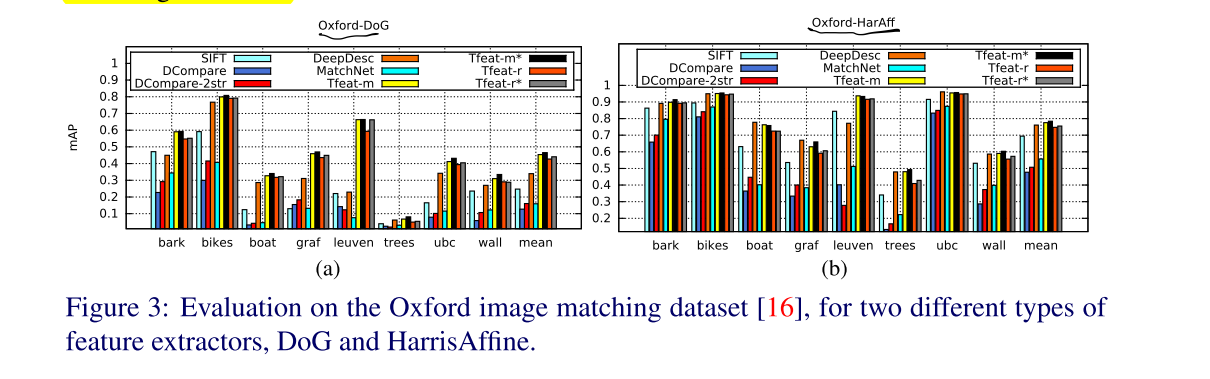
- Image transformations
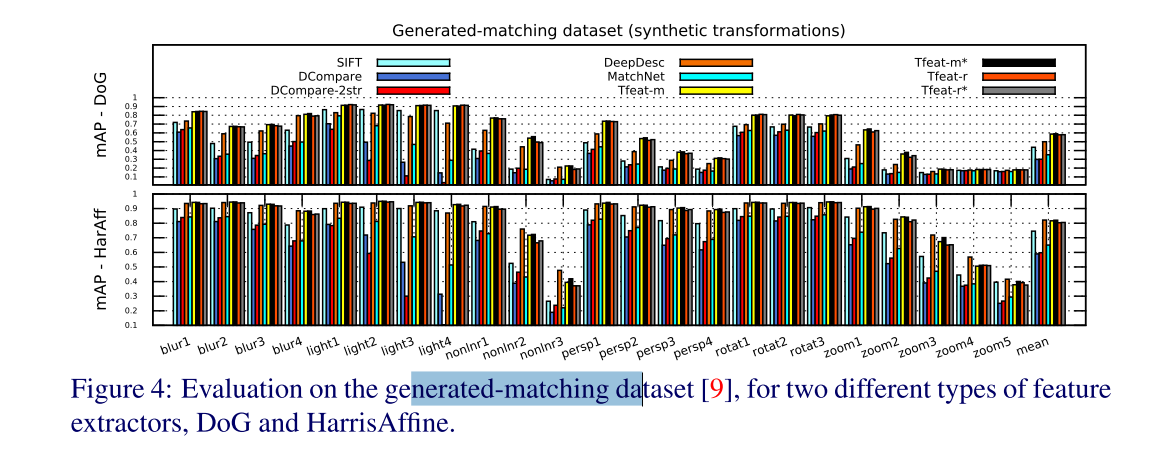
This shows that synthetic deformations are less challenging for descriptors than some real-world changes as the ones found in Oxford dataset.
5 Efficiency
Tfeat,体量更小,运算更快,效果更好。
6 Summary
- 提出了一个体量更小的模型,同时设计了一个方法使得训练结果更好
- 阐述 ratio-loss based methods 更适合 patch pair classification, margin-loss based methods 在 nearest neighbour matching 表现更好。这里我怀疑是作者第一句说错了,因为在ratio-loss的在patch pair classification 测试结果(4.1 Patch pair classification)上,并没有比 margin-loss好,事实上,这篇论文里我没有找到地方证明ratio-loss在哪里优于margin-loss.....
- a good performance on patch classification does not necessarily generalise to a good performance in nearest neighbour based frameworks.
Refer
[1] TPR FPR ROC AUC:https://zhuanlan.zhihu.com/p/100059009
[2] FPR95:https://stats.stackexchange.com/questions/481991/false-positive-rate-at-k-recall
[3] MAP:https://www.zhihu.com/question/53405779
[4] E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-Noguer. Discriminative learning of deep convolutional feature point descriptors. In ICCV, 2015.
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15680148.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号