SIFT Learing records
 花了一周时间去了解了SIFT算法。图像的特征点具有的一些特性。
花了一周时间去了解了SIFT算法。图像的特征点具有的一些特性。
花了一周的时间去读了一下SIFT的原论文,相关的一些视频还有文章,大体了解了其思想和步骤,在这里记录一下吧。
SIFT是一种提取图像中具有尺度不变性的关键点的算法。举个例子,一个鼠标,对其拍摄远端,近端两张照片,然后用SIFT分别提取这两张图片的关键点,然后计算特征点的描述符,用描述符进行匹配。类似的这些描述符也可以用于图像检索。

SIFT算法的步骤
-
构建高斯差分金字塔,寻找可能的关键点。
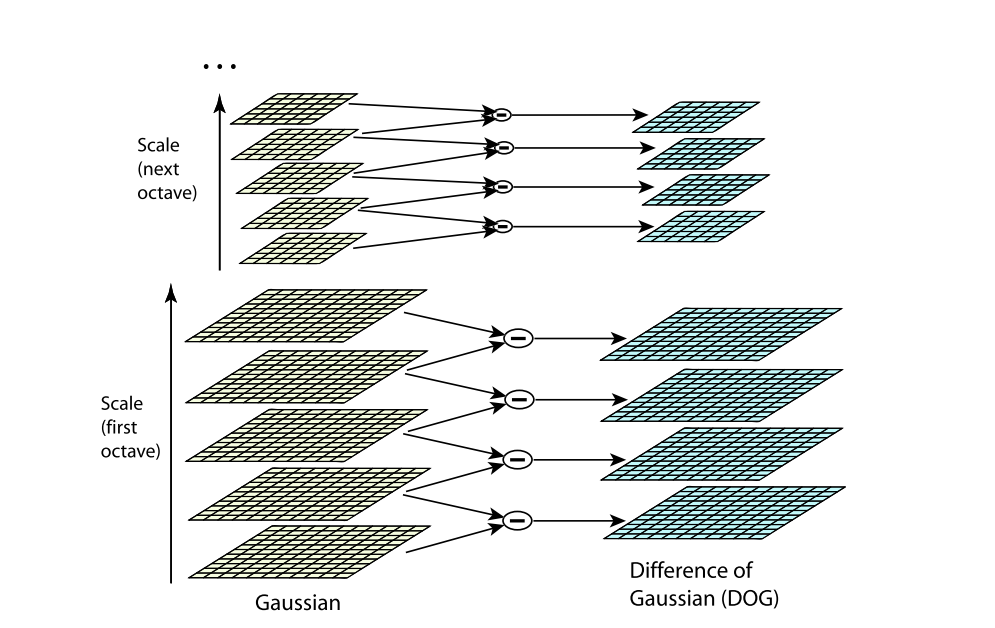
-
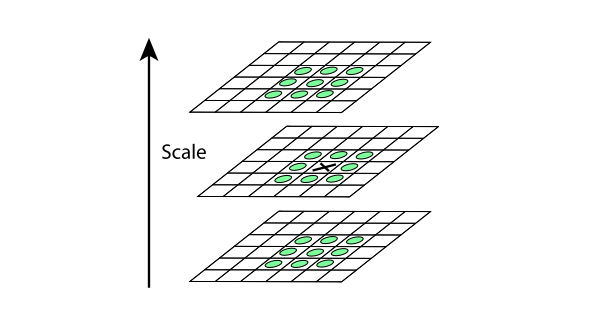
因为上一步找到的极值点都是离散的,不一定是真正的极值点,对此可以在检测到的极值点处做三元二阶泰勒展开,
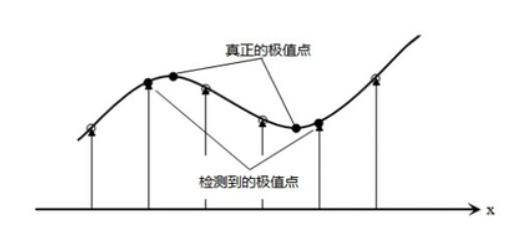

通过有限差分法求偏导,代入原方程,求导,并让方程等于零,我们可以得到极值点的偏移量为:

将(10)代入(9)可以得到对应的极值点:

同时舍去对比度低的点。
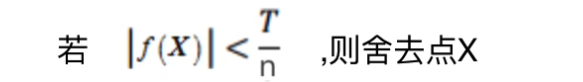
同时仅仅舍去对比度低的点,是不够的,又使用了一个Heesian 矩阵 来消除边缘效应。
- 为关键点赋方向
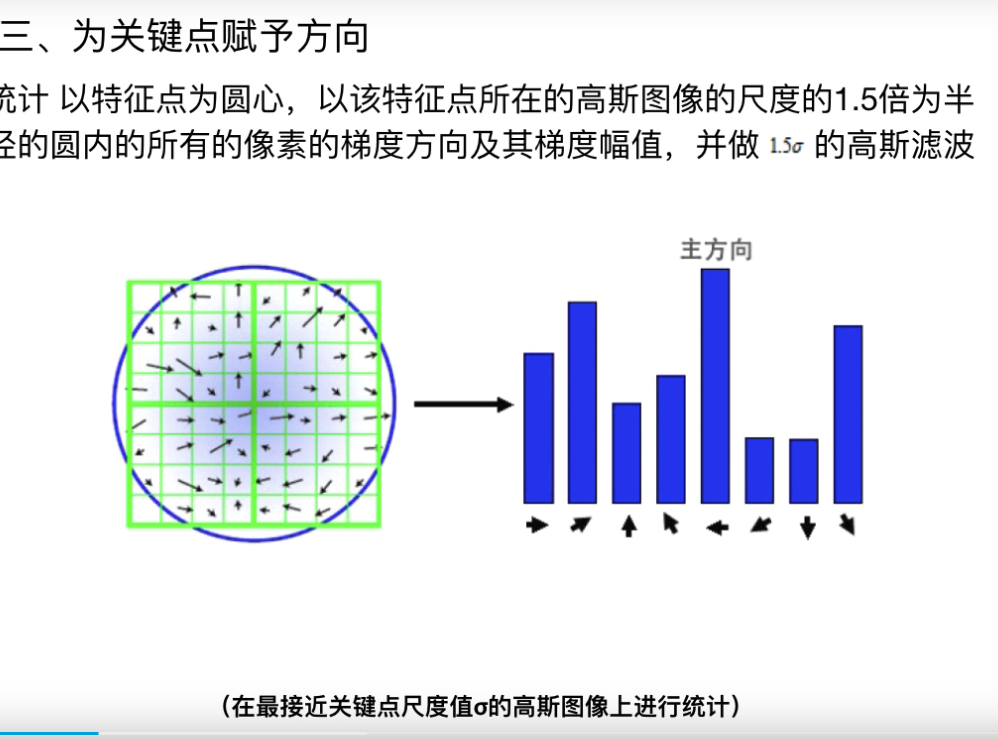
-
构建关键点描述符
通过我们上边步骤,每个特征点被分配了坐标位置、尺度和方向。在图像局部区域内,这些参数可以重复的用来描述局部二维坐标系统,因为这些参数具有不变性。
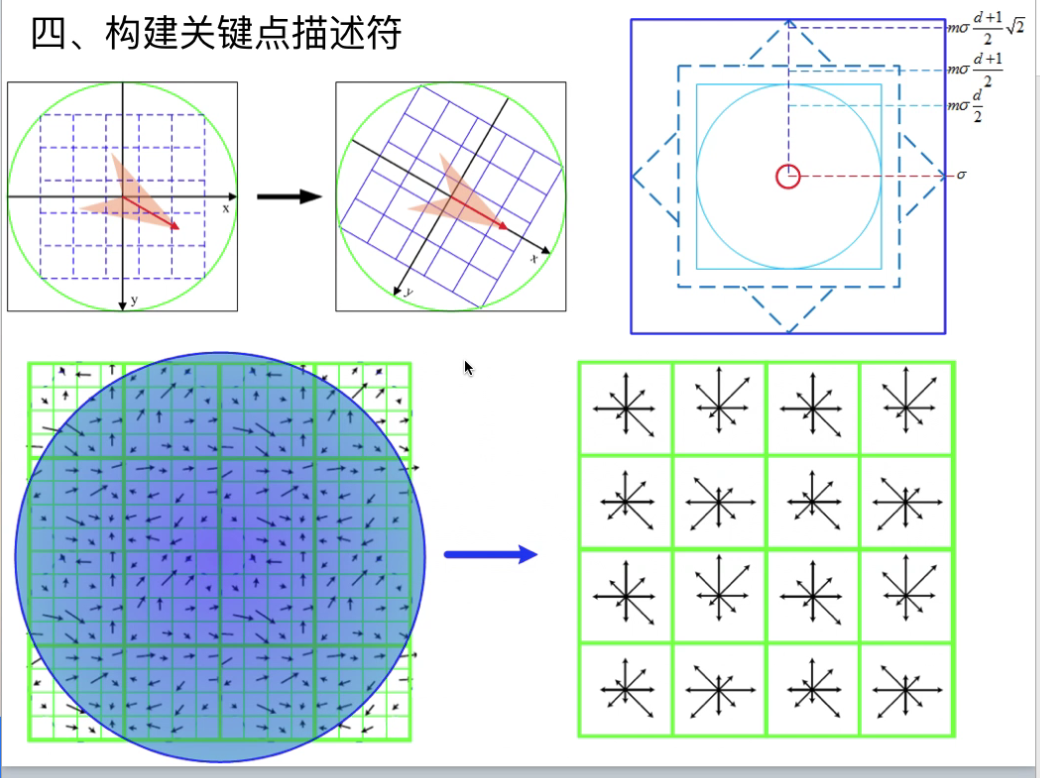
可以使用描述符进行关键点匹配。
小结
SIFI是真的难理解,刚开始去查阅了很多关于图像处理的基本知识,才能勉强理解每一步的作用。这个算法很经典,但是,整个研究过程真的挺难的,很多知识点论文中没有提到,论文本身又是英文写,读起来难免有些困难,限于自己目前的知识以及编程能力,仍有一些问题还没有想通,可能随着时间的推移,会有另一种层面的理解。
附录代码
from __future__ import print_function
import cv2 as cv
import numpy as np
import argparse
parser = argparse.ArgumentParser(description='Code for Feature Matching with FLANN tutorial.')
parser.add_argument('--input1', help='Path to input image 1.', default='mu.jpg')
parser.add_argument('--input2', help='Path to input image 2.', default='mo.jpg')
args = parser.parse_args()
img_object = cv.imread(args.input2)
img_scene = cv.imread(args.input1)
if img_object is None or img_scene is None:
print('Could not open or find the images!')
exit(0)
#-- Step 1: Detect the keypoints using SURF Detector, compute the descriptors
minHessian = 400
detector = cv.xfeatures2d_SURF.create(hessianThreshold=minHessian)
keypoints_obj, descriptors_obj = detector.detectAndCompute(img_object, None)
keypoints_scene, descriptors_scene = detector.detectAndCompute(img_scene, None)
#-- Step 2: Matching descriptor vectors with a FLANN based matcher
# Since SURF is a floating-point descriptor NORM_L2 is used
matcher = cv.DescriptorMatcher_create(cv.DescriptorMatcher_FLANNBASED)
knn_matches = matcher.knnMatch(descriptors_obj, descriptors_scene, 2)
#-- Filter matches using the Lowe's ratio test
ratio_thresh = 0.5
good_matches = []
for m,n in knn_matches:
if m.distance < ratio_thresh * n.distance:
good_matches.append(m)
#-- Draw matches
img_matches = np.empty((max(img_object.shape[0], img_scene.shape[0]), img_object.shape[1]+img_scene.shape[1], 3), dtype=np.uint8)
cv.drawMatches(img_object, keypoints_obj, img_scene, keypoints_scene, good_matches, img_matches, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
#-- Localize the object
obj = np.empty((len(good_matches),2), dtype=np.float32)
scene = np.empty((len(good_matches),2), dtype=np.float32)
for i in range(len(good_matches)):
#-- Get the keypoints from the good matches
obj[i,0] = keypoints_obj[good_matches[i].queryIdx].pt[0]
obj[i,1] = keypoints_obj[good_matches[i].queryIdx].pt[1]
scene[i,0] = keypoints_scene[good_matches[i].trainIdx].pt[0]
scene[i,1] = keypoints_scene[good_matches[i].trainIdx].pt[1]
H, _ = cv.findHomography(obj, scene, cv.RANSAC)
#-- Get the corners from the image_1 ( the object to be "detected" )
obj_corners = np.empty((4,1,2), dtype=np.float32)
obj_corners[0,0,0] = 0
obj_corners[0,0,1] = 0
obj_corners[1,0,0] = img_object.shape[1]
obj_corners[1,0,1] = 0
obj_corners[2,0,0] = img_object.shape[1]
obj_corners[2,0,1] = img_object.shape[0]
obj_corners[3,0,0] = 0
obj_corners[3,0,1] = img_object.shape[0]
scene_corners = cv.perspectiveTransform(obj_corners, H)
#-- Draw lines between the corners (the mapped object in the scene - image_2 )
cv.line(img_matches, (int(scene_corners[0,0,0] + img_object.shape[1]), int(scene_corners[0,0,1])),\
(int(scene_corners[1,0,0] + img_object.shape[1]), int(scene_corners[1,0,1])), (0,255,0), 4)
cv.line(img_matches, (int(scene_corners[1,0,0] + img_object.shape[1]), int(scene_corners[1,0,1])),\
(int(scene_corners[2,0,0] + img_object.shape[1]), int(scene_corners[2,0,1])), (0,255,0), 4)
cv.line(img_matches, (int(scene_corners[2,0,0] + img_object.shape[1]), int(scene_corners[2,0,1])),\
(int(scene_corners[3,0,0] + img_object.shape[1]), int(scene_corners[3,0,1])), (0,255,0), 4)
cv.line(img_matches, (int(scene_corners[3,0,0] + img_object.shape[1]), int(scene_corners[3,0,1])),\
(int(scene_corners[0,0,0] + img_object.shape[1]), int(scene_corners[0,0,1])), (0,255,0), 4)
#-- Show detected matches
cv.namedWindow("Good Matches & Object detection", 0)
cv.resizeWindow("Good Matches & Object detection", 1024, 1024)
cv.imshow('Good Matches & Object detection', img_matches)
cv.waitKey()
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15656765.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号