Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
 Grad-CAM论文笔记
Grad-CAM论文笔记
Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
1.Abstract
我们提供了一种方法(Grad-CAM)高亮图片中对预测产生影响的重要区域:
1.在CNN的模型家族里适用范围广:image classfication,image captioning,VOA。
2.提供对CNN失败样例的观察(显示看似不合理的预测的合理解释)。
3.在 ILSVRC-15弱监督定位任务上比以往的方法表现更好。
4.更忠实于底层模型。
5.通过辨认数据集的偏移来实现模型泛化。
6.帮助未经训练的用户成功地区分“更强”的网络和“更弱”的网络,即使两者做出的预测完全相同。
2.Introduction
-
卷积神经网络在很多的任务中以及取得了重大突破,但是对于解释它们为什么这么预测,预测了什么是必须的是很有必要的。Consequently, when today’s intelligent systems fail, they fail spectacularly dis-gracefully, without warning or explanation, leaving a user staring at an incoherent output, wondering why. 摘选自原论文。
-
Class Activation Mapping(CAM)这个方法提供了一种在图像分类任务上识别 discriminative regions的方法(我的理解是将图片中对分类发挥作用的区域找出来),但是这个方法移除了CNN网络的全连接层( Section Approach会介绍这个方法)。论文中提出的方法Grad-CAM并没有修改模型结构,是CAM的泛化,并且能够应用在更大范围的CNN模型家族(mage classfication,image captioning,VOA)。
-
进行了几种可视化方法的优缺点介绍对比
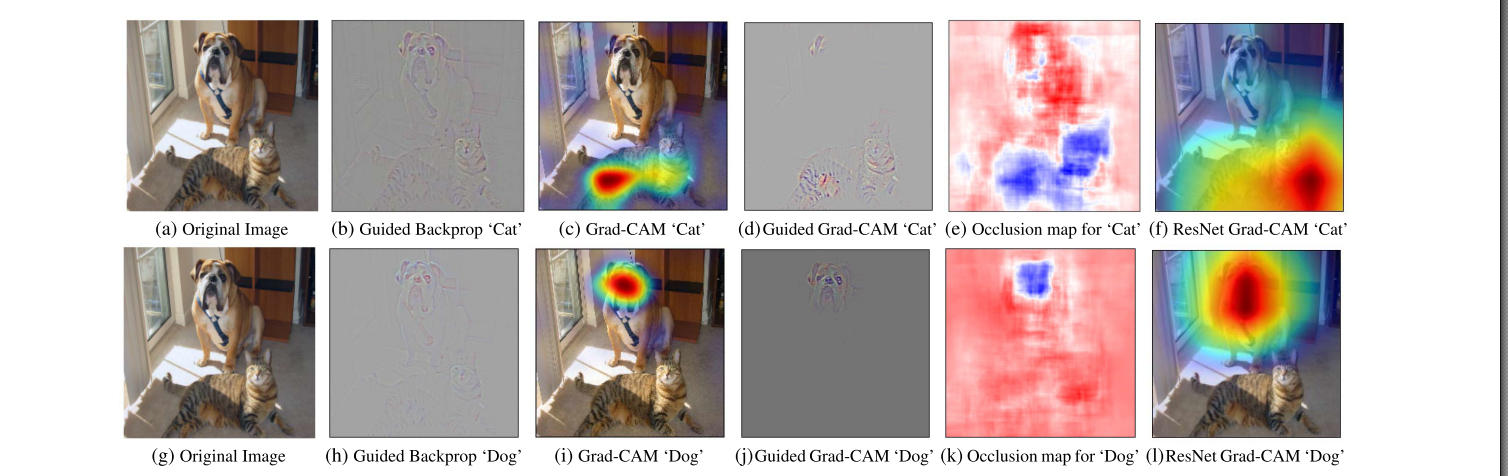
-
Guided Back-propagation 和 Deconvolution是高分辨率的并且高亮了细粒度的细节,但是并不能区分类别。如图1b,1h,Guided Backprop只提取出了图片中的猫与狗的所有纹理。
-
CAM,Grad-CAM具有很高的类别区分性。如图1c,1i and 1f,1l。其实这里也能看出来,ResNet比VGG16更优一些,以猫为例子,1c(VGG16)的注意力在身体上,1f(ResNet)在头部区域,ResNet关注的位置要比VGG16更符合人类的直觉。
-
将上面二者的优点进行结合,得到了Guided Grad-CAM,如图1d,1j,
-
论文还指出了,Grad-CAM得到的结果,与遮挡敏感性的实验结果非常类似。
-
需要额外指出的是:Grad-CAM, CAM得到的localization map的尺寸与最后一个卷积层得到的feature maps的高宽相同,小于原始输入图片的分辨率。因此1c,1i,1f,1l是localization map进行上采样(双线性差值)并且与输入图片叠加得到的。在 Section Approach有Grad-CAM, CAM的实现方法介绍。
-
3.Approach
- Grad-CAM实现方法,
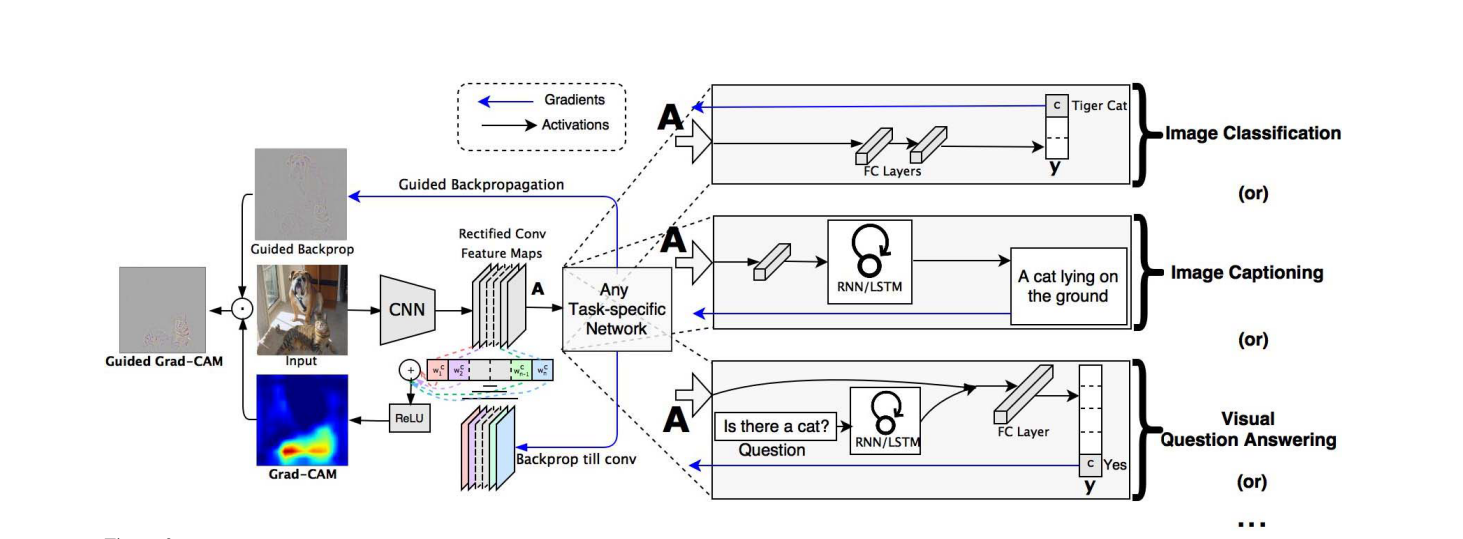
论文中给出的图是这样的,笔者单独把Image Classification的实现方法画了出来,可以结合原论文去理解。当然也可以自行忽略我画的,,,,
将Localization Map上采样(双线性差值)之后,再与Guided Backprop得到的结果点乘,就得到了Guided Grad-CAM。
同时,论文指出Deconvolution得到的高分辨率图片有伪影,Guided Backprop得到的结果具有更少的噪声。
-
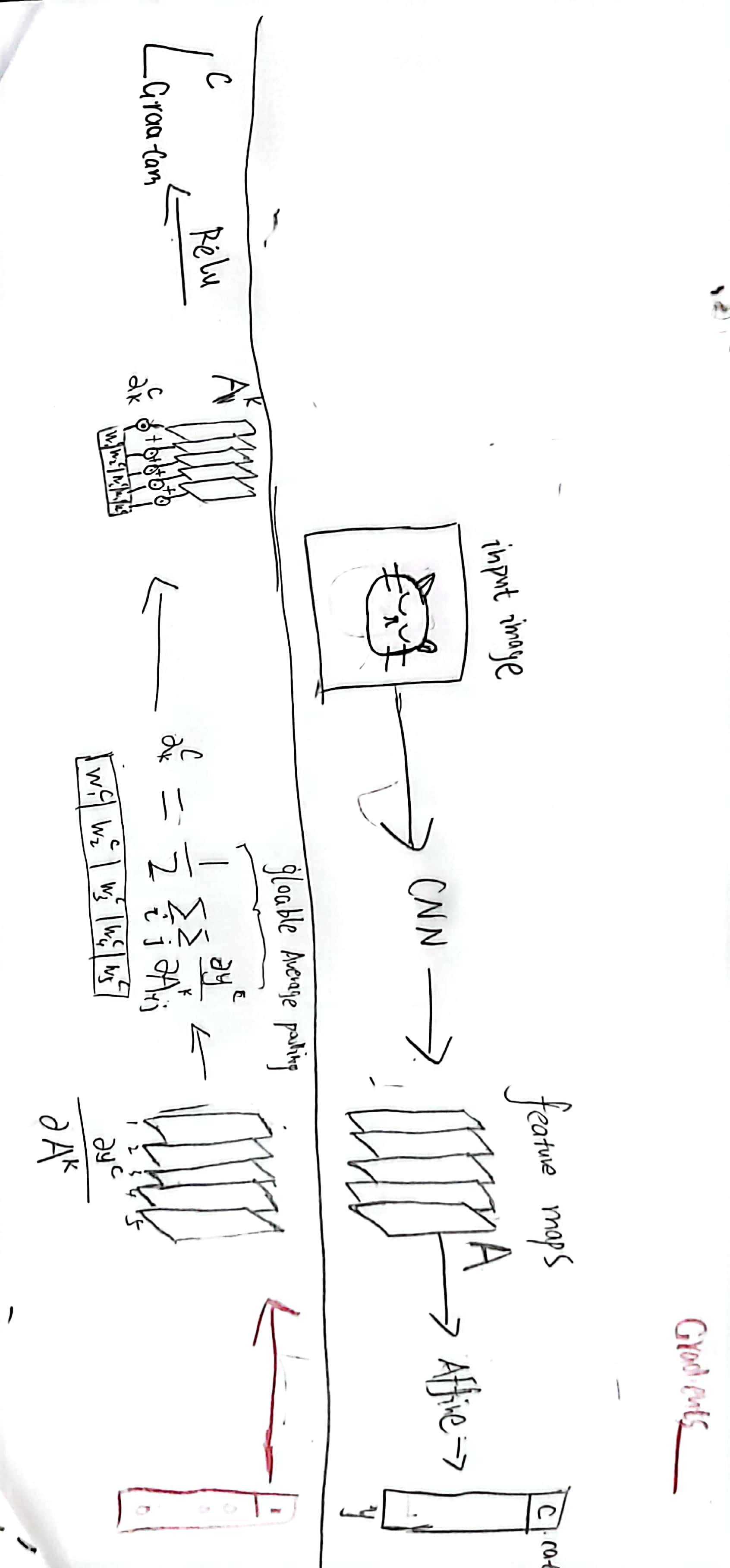
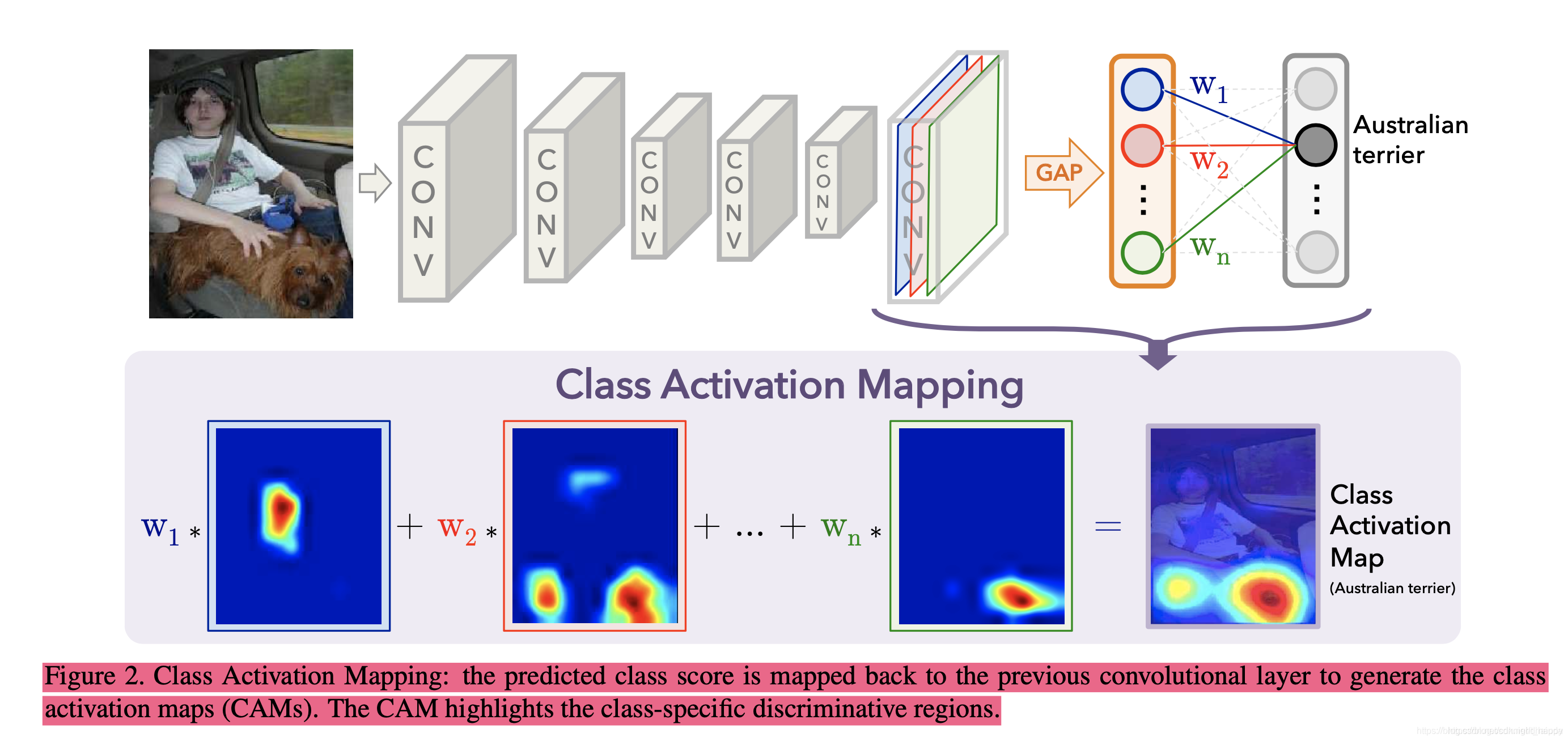
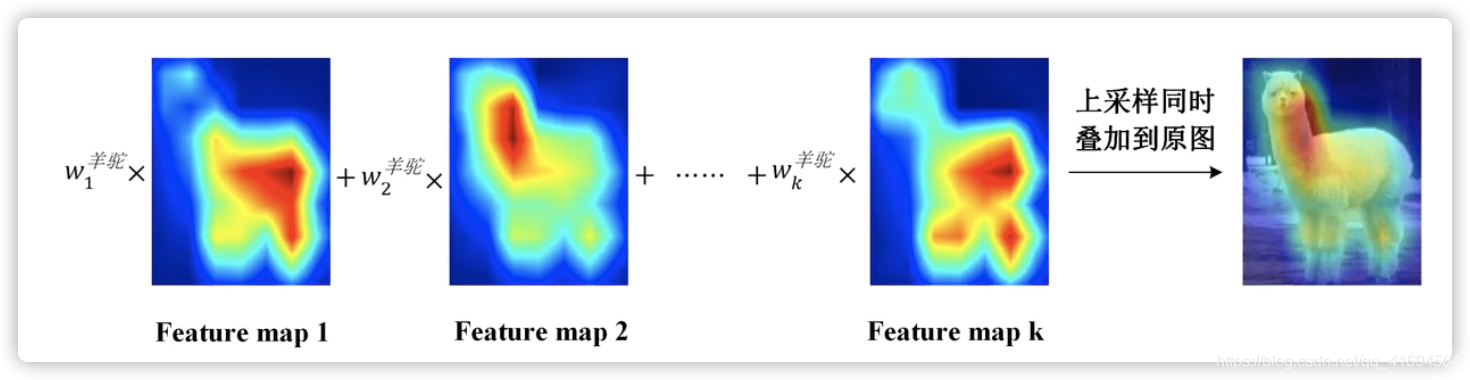
CAM实现方法
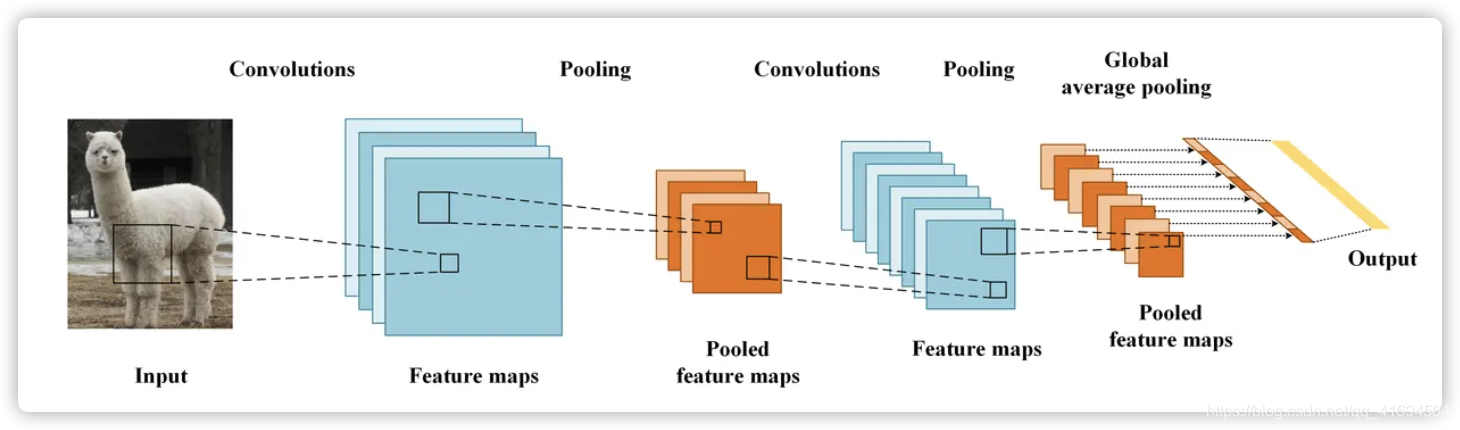
CAM的思想是去掉全连接层,加一层GAP,然后通过论文中的这个公式:
求出每个类别对应的分数。模型训练完之后,又可以通过论文中的这个公式得到\(L^c_{CAM}\)
图片描述更加好懂一些:
4.Evaluating Localization
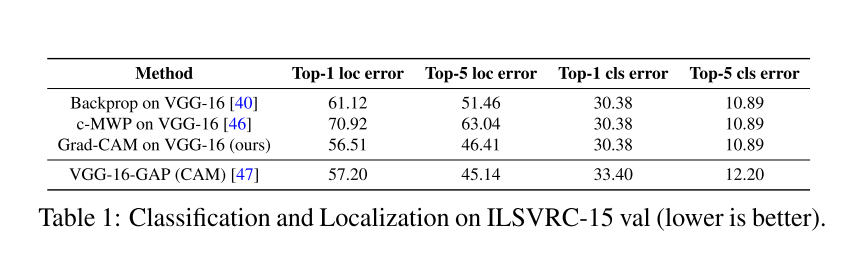
4.1. Weakly-supervised Localization
这小节主要介绍了Grad-CAM在弱监督的定位任务上的表现。笔者对弱监督学习还不是很了解,因此不介绍太多。
4.2 Weakly-supervised Segmentation
使用Grad-CAM作为的弱监督定位种子,在VGG16网络上,达到的IoU(一个指标)比CAM要高。
5.Evaluating Visualizations
5.1 Evaluating Class Discrimination
作者在PASCAL VOC 2007中选择了一部分图像(每个图像包含两个注释的类别)进行验证,他Deconvolution、Guided Backpropagation和Grad-CAM分别结合这两个方法得到Deconvolution Grad-CAM和Guided Grad-CAM一共四个方法去对待测样本进行可视化分析,然后在自己的组织Amazon Mechanical Turk (AMT)抽选志愿者进行人为的识别,通过人和机器的对比观察在前向过程中哪一种方法对于类别分类可解释有较好的结果。其实验结果如下:

这一小节读得有点磕磕绊绊。
5.2 Evaluating Trust
Grad-CAM可以更好地评判模型的可信度。作者让54个AMT workers进行如下图这样的打分,使用Grad-CAM进行的可视化在评判模型的可信度上表现更好。

5.3 Faithfulness vs. Interpretability
这一小节是比较可视化方法对模型的忠实度。是通过遮挡实验进行评估的,发现Grad-CAM的可视化区域的遮挡敏感性更高,说明该方法更加忠实于模型。

文中提到了一个 rank correlation(秩相关)。
6.Diagnosing image classification CNNs with Grad-CAM
6.1 Analyzing failure modes for VGG-16
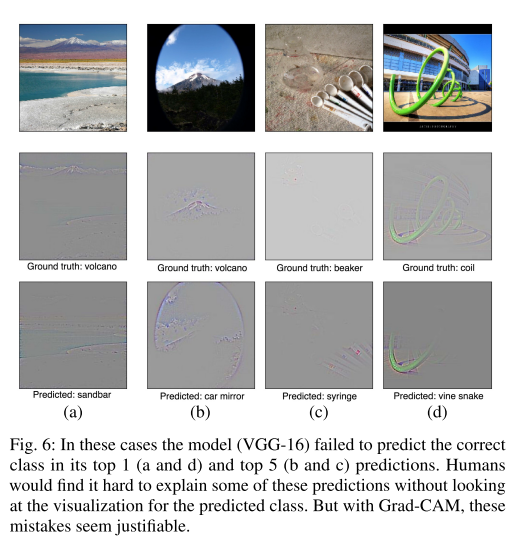
一些错误的预测,通过Grad-CAM进行观察后,似乎有了合理的解释。从上图也可以看出,作者认为CNN模型将样本分类错误是有依据的,比如说对于第一列的样本,CNN模型将其分类成sandbar,但是实际上groundtruth为volcano,因为CNN模型的分类过程他的注意力主要集中在了sandbar的这个目标上,所以对于最终的分类过程显示sandbar更加容易被预测作为结果。
6.2 Effect of adversarial noise on VGG-16

在给神经增添一些不可感知的扰动之后,使得神经网络预测出现失误,但是以类别cat或者dog进行Grad-CAM时依然可以很好地标记出二者的位置,关于神经网络在对抗样本的脆弱性方面的知识挺有意思的好像,读者想了解更多https://cloud.tencent.com/developer/article/1119884
6.3 Identifying bias in dataset

对于一个判断是医生还是护士的任务,有偏置的训练集里医生主要是男性,护士主要是女性,模型学会了关注hairstyle,face去进行预测。而当把训练集进行调整之后,医生类别里添加更多的女医生,护士类别里添加更多的男护士,模型学会了从服饰,听诊器来进行预测。同时论文作者还提了一句对于科学和社会公平的思考:“ This experiment demonstrates a proof-of-concept that Grad-CAM can help detect and remove biases in datasets, which is important not just for better generalization, but also for fair andethical outcomes as more algorithmic decisions are made in society.”
7. Grad-CAM for Image Captioning and VQA
这一节作者又介绍了Grad-CAM在 Image Captioning and VQA 上的良好表现,笔者在这个方面知识不是很全面,因此只通读了一下,暂不做总结。
What if
首先需要记住的是,这个方法最本初的用途是:找到图片中使得神经网络做出预测的区域。
当我理解了Grad-CAM的实现方法之后:
有了一个疑惑一直萦绕在心头,为什么不直接反向传播,然后得到预测分类c的分数score关于输入图片的像素值pixel的导数 $\partial score^c \over \partial pixel $,这样不就找到了哪些像素最能影响神经网络做出这个决策。但实际上,这个叫做Vanilla backpropagation的方法可视化效果不好:
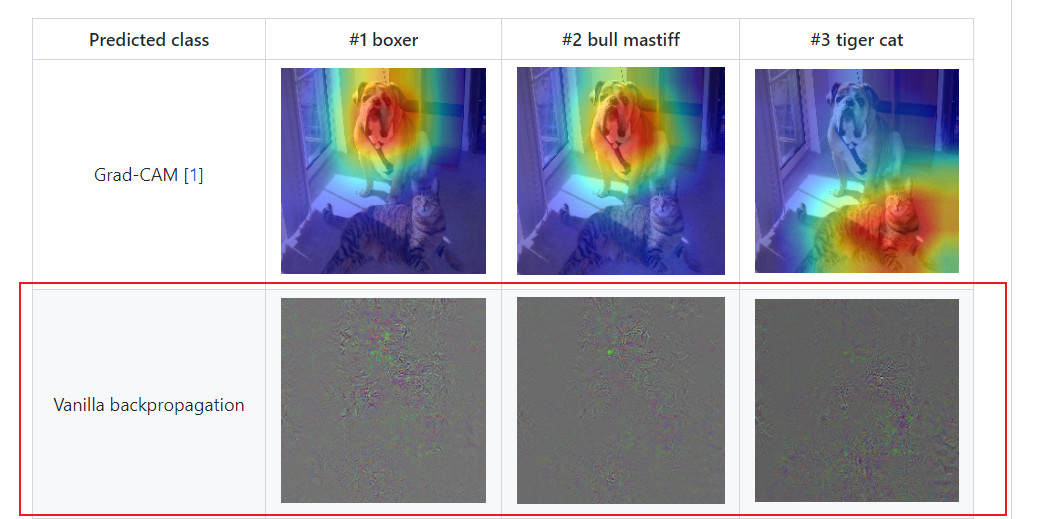
图片引自:https://github.com/kazuto1011/grad-cam-pytorch
那为什么这个原始的方法效果不好呢?问题似乎出现在relu函数这里,引用了这篇博客里的示意图,\(f\)是前向传播时经过relu函数的矩阵,\(R^{l+1}_i\)是上游传下来的梯度值,\(R^{l}_i\)是经过relu函数反向传播得到的梯度值。
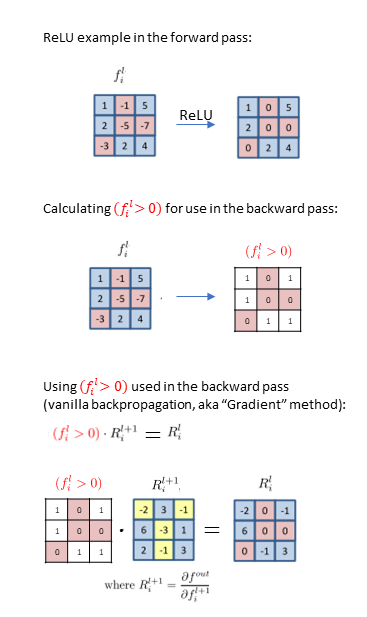
可以看到,反向传播时,上游梯度很多的正值丢失了,同时一些负值传了下来。但正值是对最终结果做出“促进”作用的,反之亦然。或许是因为这个原因吧。
所以出现了Guided Backpropagation,这个方法对梯度反向传播通过relu节点时的计算方法做了修改:
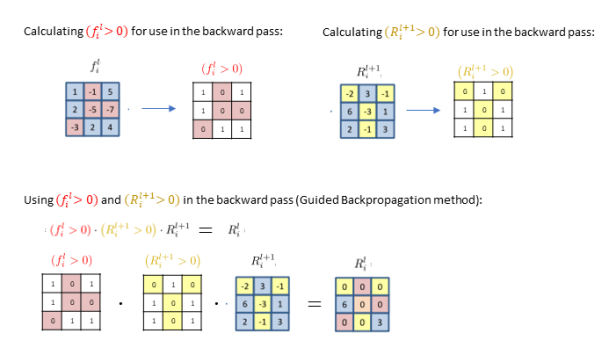
得到的可视化结果好了许多:

图片引自:https://github.com/kazuto1011/grad-cam-pytorch
但也发现了Guided Backpropagation的类区分性差了一些,比如第二列的猫和狗,不如Grad-CAM,感兴趣的读者可以去上面的github链接查阅更多可视化结果。
至此,从Vanilla backpropagation -->Guided Backpropagation-->CAM-->Grad-CAM介绍完毕。
8.Summary
昨天一篇公众号发了一篇文章,有一句话另外印象深刻:作为一名工科学生,光有天马行空的想法还不够,还得具备实现想法的能力。
这不说的就是我自己,花了一天时间尝试去搭deconvnet,还失败了,接下来准备把pytorch系统学一遍,对里面的各种常用操作有个大致了解,这样做实验应该顺畅一些。
总结的一些点:
-
Grad-CAM的实现方法,及其更好的效果(更高的类区分性,不用修改模型结构等)
-
Grad-CAM可以帮助观察数据集的偏移,6.3护士和医生的例子。
-
论文涉及了到的还不甚了解的概念,需要填坑
- 秩相关
- 双线性差值
- 神经网络关于对抗样本的脆弱性
-
Deconvlution得到的结果有伪影,因此作者使用了Grad-CAM + Guided Backpropagation得到 Guided Grad-CAM
-
Google in English,一些内容,中文网上没有好的阐述,但是有些外国友人的博客写得很明白。
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15438008.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号