Visualizing and Understanding Convolutional Networks论文复现笔记
 Visualizing and Understanding Convolutional Networks论文复现笔记,文章包含论文的各结构内容总结和几个自己总结的启发点
Visualizing and Understanding Convolutional Networks论文复现笔记,文章包含论文的各结构内容总结和几个自己总结的启发点
Visualizing and Understanding Convolutional Networks 论文复现笔记
Abstract
大型的卷积神经网络已经在图像分类上面取得了令人印象深刻的成果,但是现在对它是如何运行的,或者如何提升网络的性能还没有一个清晰的理解。这篇论文对上面两个问题提出了一些想法和方法。
Introduction
- 使用了一个 Deconvolutional Network,把特征激活投影到像素空间
- 对CNN做遮掩的灵敏度分析,观察图像的哪些部分对分类重要
Approach
Visualization with a Deconvnet
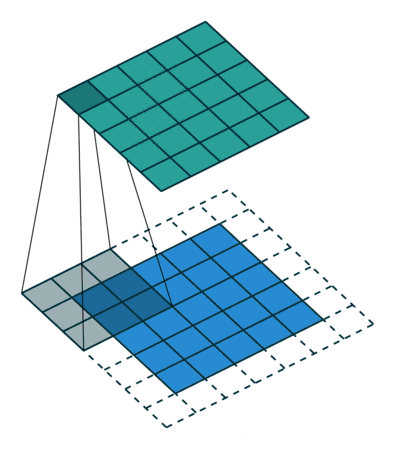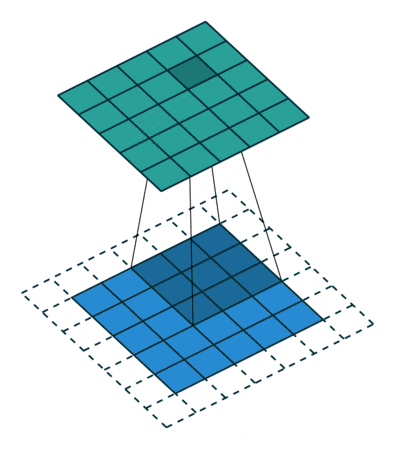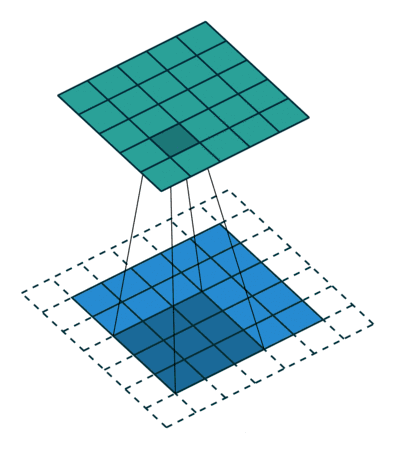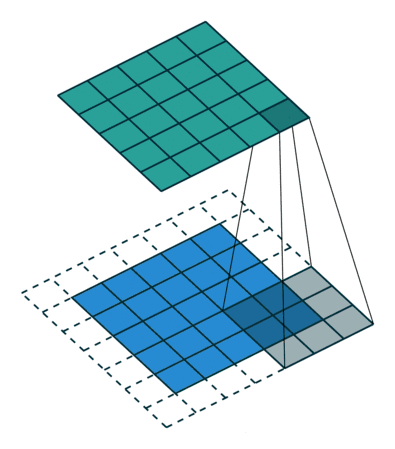
这是一个将特征图投影到像素空间的方法。涉及到两个概念,特征图是将输入图像进行卷积,激活,池化后得到的,像素空间是将特征图输入到Deconvnet得到的图像。更多细节可以可以参考原图。
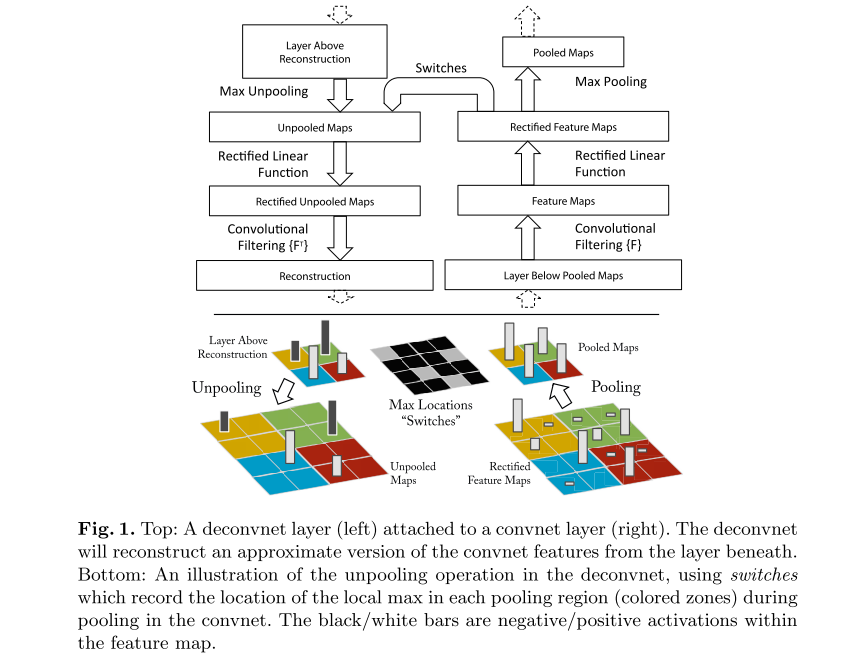
关于Deconvnet的实现
这个是另一篇论文中提出的方法,反卷积的相关数学运算过程参考了CSDN上的一篇博文。
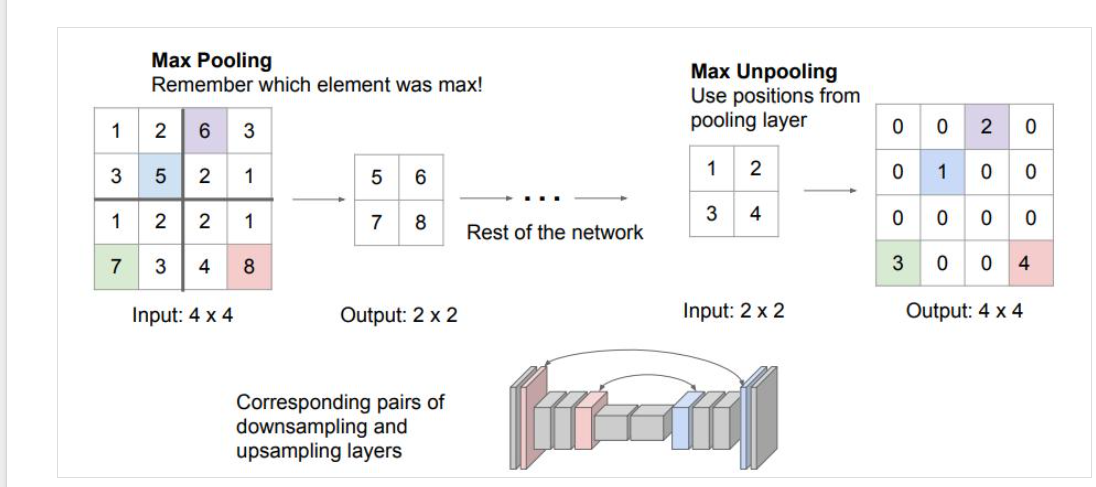
Max Unpooling用一个switches记录最大值的位置,然后将输入放置到扩大后的矩阵对应位置。
Convnet Visualization
对于一个给定的Feature map,论文中展示了最高的9个激活,并把每个激活投影到像素空间,同时对于可视化的像素空间,论文同样展示了相关的图片区域。

一些阐述,对于layer 5, row 1, col 2,相关的图片看起来没有相关性,但是这个feature map对背景中的草地敏感,而不是前景中的物体。
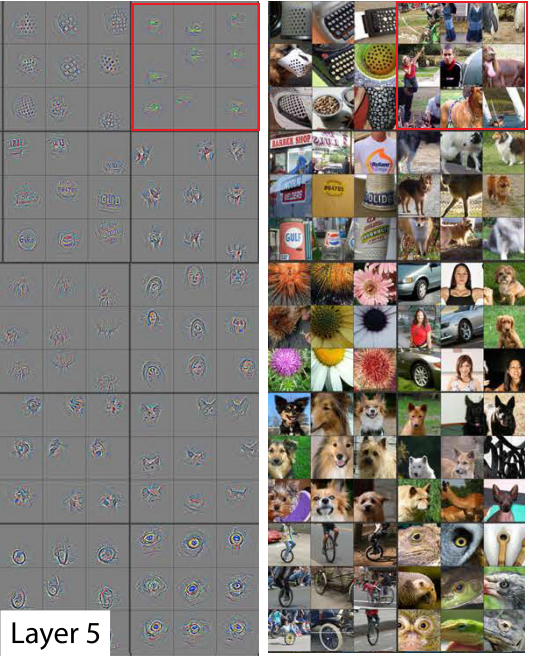
同时说明layer2 -- layer5,feature map对图像的识别是从纹理逐渐到具体的物体。
这个地方挺有意思的,也可以算是一个启发点,可以发现,layer比较小的feature map经过较少的epochs就可以收敛,而比较大的layer的feature map却需要较大的 epochs才能收敛(layer 5需要40-50个epochs)

模型的优化

- 通过卷积核可视化可以看到alexNet模型中第一层和第二层(下图中的a和c)存在一些问题,比如第一层有一些 dead features(偏灰色的那些小方块),第二层有一些重叠和黑色的混乱。
- 通过把第一层的11x11卷积核变成7x7,然后stride从4变成2,得到的结果如图c和e所示,得到了更多的独特的特征。
- 这样的改动也提升了模型的效果。
为什么标红色的小方块认为是 “dead features”?
- a中的灰色方块,我们可以从卷积的数学运算来理解,由于这本质上是卷积核的可视化,第一层的kernel size是(\(3 \times 11\times 11\))呈现为均匀的灰色说明在数值主要是128(RGB),当这个卷积核去进行卷积,实际上提取不出什么特征。因为这只是一个线性变换。
- c中黑色方块,黑色说明在RGB上的数值主要是0,卷积后也会使得大多数输入神经元被置0,因此也提取不出什么特征。
遮挡敏感性
-
b图的定义是:首先确定在未遮挡的情况下,激活最强的那个feature map的位置,然后这个feature map的值的和是关于灰色遮挡位置的函数,由此形成了一个热力图。
-
c图的定义是:这一个feature map投影到像素空间得到的照片,第一个是来自input image的投影,其余是来自其它图片。
-
d图是正确类别的概率关于关于灰色遮挡位置的函数。
-
e图是最有可能的类别关于遮挡位置的函数。
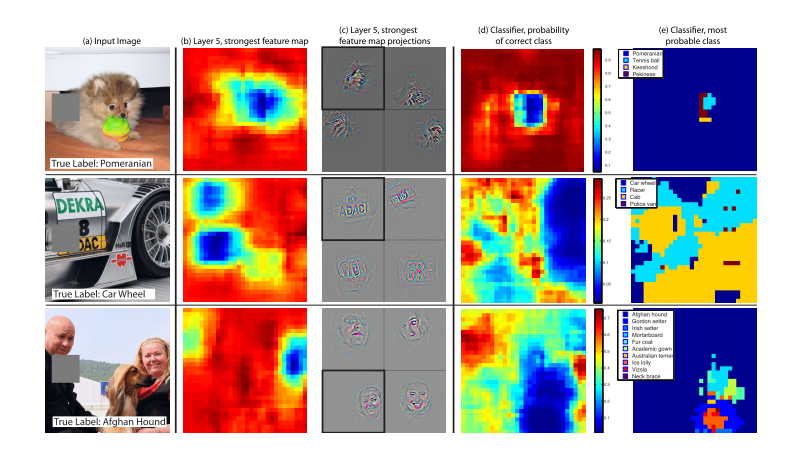
当然第一个小狗的最好理解了,当小狗的脸被遮挡时,无论是最强feature map的值,还是预测为小狗的概率都明显下降。从本质上看,这个最强的feature map能学到关于类似于小狗脸的一些特征,当小狗脸被遮挡时,这个最强feature map得不到激活。因此当小狗脸被遮挡时,关于那个 ball 的feature map 就 “凸显”出来了,因此Tennis ball的概率变高。
再来看第二张图,这个最强feature map能学习到关于一些 “图标文字的信息”,但是真正影响car wheel概率的还是轮子的像素位置。
再来看第三张图,这个最强feature map能学习到关于一些 “人脸”的信息,但是真正影响预测为阿富汗猎犬概率的还是猎犬对应的那些像素。
那么问题来了,第二张图的正确 label 是 car wheel,第三张图的正确 label 是afgan hound,那么最强激活的feature map为什么不是有关car wheel或者afgan hound的纹理?
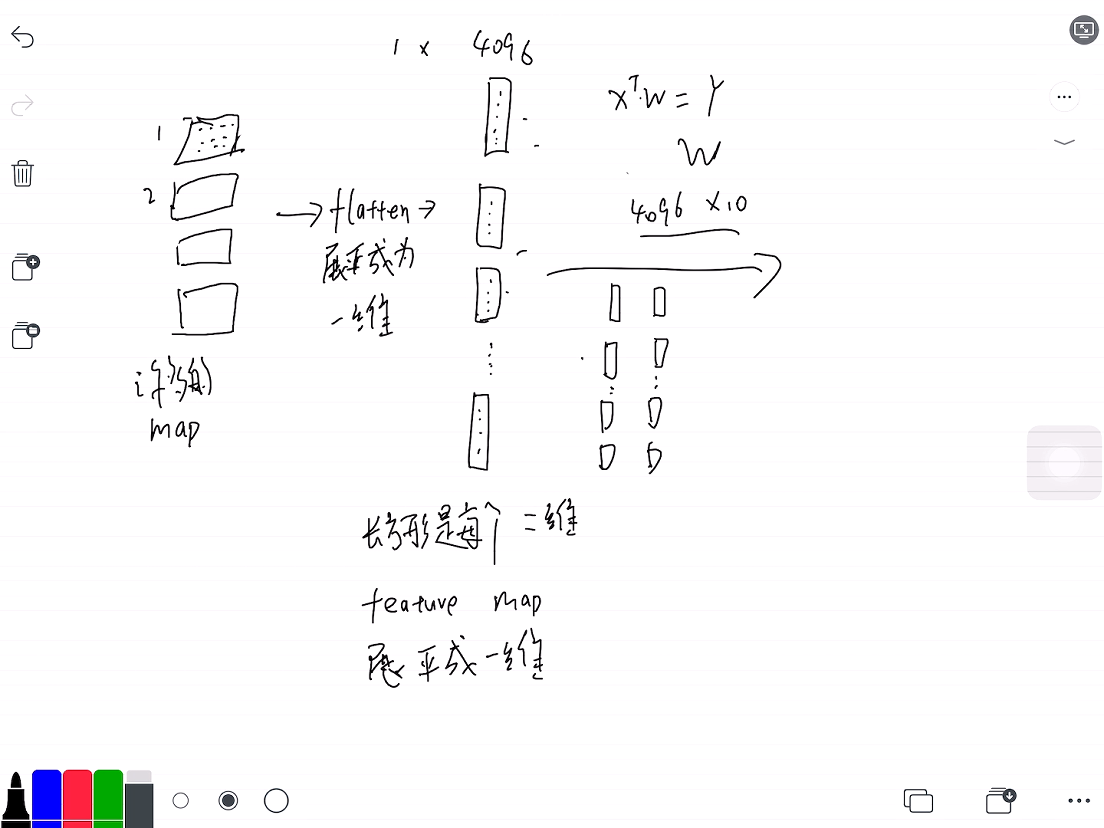
这样似乎形成了一个悖论,我们在layer 5 训练结束后,将得到的feature map其展平,那么进行矩阵相乘后的最大值位置应该是对应的最强feature map的位置相对应。
关于这个地方的猜想和试验,我会另外写一篇博客。
我的猜想:(当然很有可能是错的),的确,许多的feature map,能学到不同的信息,比如有的对狗头敏感,有的对人脸敏感,有的对一些文字信息敏感,但是图片的标签不能保证最后一个卷积层的最强Feature map学习到的就是对应标签的特征,也有可能是别的,比如上图的车子,最强的那个feature map反映的是一些文字信息。但是这些信息的综合处理,是在最后面的全连接层实现的,也就是说,全连接层综合 “考虑”了这些信息。
Experiments
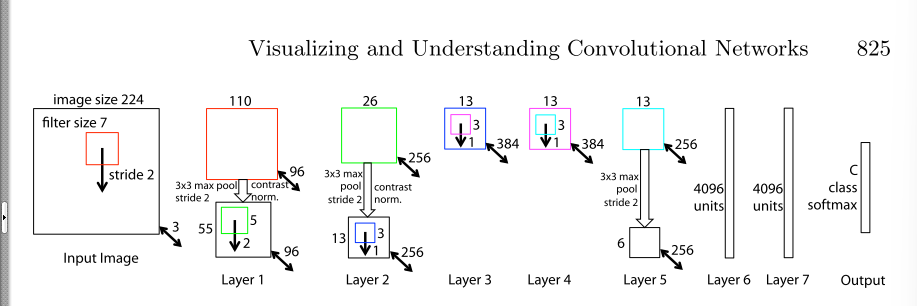
基于可视化后对AlexNet模型进行了修改,提升了表现,说明可以通过可视化的技巧分析和改善模型。修改后的结构:
- 模型结构调整
-
移除layer 6 layer 7,对模型的性能影响不大,尽管这两层的参数是是整个模型中的大多数。
-
移除了两个卷积层,对模型的整体性能影响也不大
-
但是当模型层数太少时,性能剧烈变坏。
-
增大中间卷积层的size使得模型性能变好,但是增加全连接层的size影响不大
这几个点相关的实验以前做过了https://www.cnblogs.com/programmerwang/p/15129658.html
-
5.2 模型的泛化能力
ResNet在几个数据集上的表现。论文中作者使用了一种特殊的训练方式,即给定的每个class里面分别有15,30,45,60张图片,但是我直接使用了原数据集的所有数据。
终于跑出来了,由于Caltech101,Caltech256和Pasca2012的数据集需要自己编写Dataset类,但由于自己对pytorch还有一些图像基础的相关知识不熟,遇到了很多奇怪的问题。
-
一开始以为Caltech都是彩色图,就当成彩色图3通道处理的,然后报错了。这篇博文解决了我的问题,https://blog.csdn.net/weixin_44012382/article/details/108190384
-
由于是使用Resnet18做分类数不确定的分类问题,需要自行修改模型结构(Resnet默认是1000分类问题)。
通过以下代码修改了ResNet的结构。
def get_model(): model = models.resnet18(pretrained=True) # 提取fc层中固定的参数 fc_features = model.fc.in_features # 修改类别为102 model.fc = nn.Linear(fc_features, 102) model.to(device) return model这是ResNet在相关数据集上的实验记录:
数据集 训练第一个epoch的准确率(训练集,验证集) 最高准确率(训练集,验证集,epoch) Caltech101 (85.41%, 85.60%) (95.37%,96.88%,8) Caltech256 (62.10%, 63.08%) (89.90%,94.72%,8) Pascal2012 由于笔记本算力限制,未测试在Pascal2012数据集上的表现。
-
Summary
- 提出了一种可视化CNN的方法,说明了内部特征并不是随机的,是可以解释的。
- Deconvolutional NetWork -> pixel space
- 卷积核可视化
- 通过可视化CNN了解到了一些直觉上的特性,比如随着增加层数,类别的可区分度越高,特征越有用。
- 通过可视化CNN可以对模型进行分析和改善。具体可见Section Convnet Visualization
- 高层的feature map需要40-50epochs才能显现出来
- 通过卷积核可视化修改模型结构
- 通过可视化CNN的遮蔽实验,发现模型对局部结构是敏感的,并不是只用到了广阔的场景信息。
- 展示了ImageNet的预训练模型可以很好地泛化到其它数据集。
- 通过实验学习到了一点如何使用raw data训练自己的网络的知识
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15408078.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号