MapReduce高级_MapReduce运行机制-Map阶段
12-MapReduce运行机制-Map阶段

====================================================================================================================================================================
15-MapReduce-Reduce端join操作-步骤分析
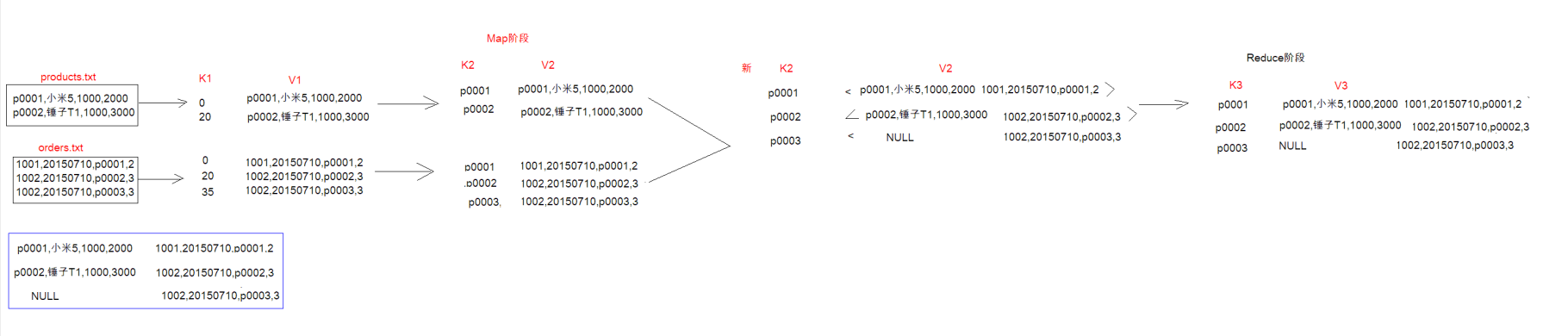
利用MapReduce来模拟数据中的连表查询

orders.txt
1001,20150710,p0001,2
1002,20150710,p0002,3
1002,20150710,p0003,3
----------------------------------------------------------------------------------------------------
product.txt
p0001,小米5,1000,2000
p0002,锤子T1,1000,3000
-------------------------------------------------------------------------------------------------------
=================================================================================================================================================
16-MapReduce-Reduce端join操作-Map阶段代码
ReduceJoinMapper.java
package com.mapreduce_reduce_join;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//将k1 v1,变成k2 v2
//首先判断数据来自于那个文件
FileSplit fileSplit = (FileSplit) context.getInputSplit();//数据切片
String fileName = fileSplit.getPath().getName();
if (fileName.equals("orders.txt")) {
//获取pid
String[] split = value.toString().split(",");
context.write(new Text(split[2]), value);
} else {
//获取pid
String[] split = value.toString().split(",");
context.write(new Text(split[0]), value);
}
}
}
---------------------------------------------------------------------------------------------------------------------------------------------------------------
ReduceJoinReducer.java
package com.mapreduce_reduce_join;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceJoinReducer extends Reducer<Text , Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String first="";
String second="";
for (Text value : values) {
if (value.toString().startsWith("p")) {
first=value.toString();
} else {
second=value.toString();
}
}
if (first.equals("")) {
context.write(key, new Text("NULL"+"\t"+second));
} else {
context.write(key, new Text(first+"\t"+second));
}
}
}
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ReduceJoinJobMain.java
package com.mapreduce_reduce_join;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReduceJoinJobMain extends Configured implements Tool{
@Override
public int run(String[] arg0) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_reduce_join");
//打包在集群运行时,需要做一个配置
job.setJarByClass(ReduceJoinJobMain.class);
//设置任务对象
//第一步:设置读取文件的类:K1和V1(读取原文件TextInputFormat)
job.setInputFormatClass(TextInputFormat.class);
//设置从哪里读
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/input/reduce_join"));
//第二步:设置Mapper类
job.setMapperClass(ReduceJoinMapper.class);
//设置Map阶段的输出类型: k2和v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//进入Shuffle阶段,采取默认分区,默认排序,默认规约,默认分组
//第三,四,五,六步,采取默认分区,默认排序,默认规约,默认分组
//第七步:设置Reducer类
job.setReducerClass(ReduceJoinReducer.class);
//设置reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步: 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
//注意:wordcount_out这个文件夹一定不能存在
TextOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/out/reduce_join_out"));
boolean b= job.waitForCompletion(true);//固定写法;一旦任务提交,处于等待任务完成状态
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个任务
//返回值0:执行成功
int run = ToolRunner.run(configuration, new ReduceJoinJobMain(), args);
System.out.println(run);
}
}
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------


 浙公网安备 33010602011771号
浙公网安备 33010602011771号