SimpleTransformers库 | 使用BERT实现文本向量化
代码参考:
https://mp.weixin.qq.com/s/9D-h0T6ZBeEf09wUQBemnw
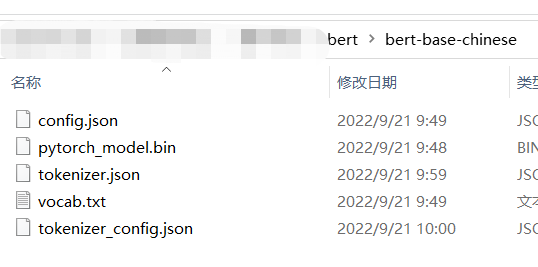
使用中文模型,需要下载的文件: 模型文件下载地址:bert-base-chinese at main (huggingface.co) 注意:另存为可能下载的是html,注意文件大小与原始文件大小匹配
可以新建文件夹-bert\bert-base-chinese 具体需要下载的文件如下面:
from simpletransformers.language_representation import RepresentationModel sentences = ["再重新安装一次", "风速和租车数量关系"] #it should always be a list model = RepresentationModel(model_type="bert",model_name="./bert/bert-base-chinese/", use_cuda=False) sentence_vectors = model.encode_sentences(sentences, combine_strategy="mean") print(sentence_vectors.shape) print(sentence_vectors)
(2, 768) [[ 0.33426642 0.33282867 -0.6713708 ... 0.59415036 -0.03538744 -0.5254581 ] [ 0.31958315 0.2777542 -0.2889337 ... 0.02864959 0.34866276 0.07708933]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号