XGBoost的优点
1. Gradient boosting(GB)
Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题![]() 残差和负梯度也是相同的。
残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量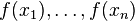 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
2. Gradient boosting Decision Tree(GBDT)
GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,
GBDT实际的核心问题变成怎么基于 使用CART回归树生成
使用CART回归树生成 ?
?
3. Xgboost
xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。
从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
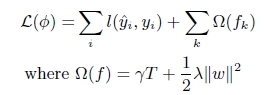
(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次的loss:
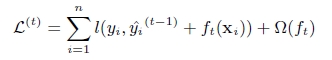
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
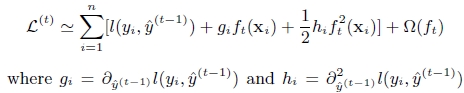
(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,XGBoost的并行是在特征粒度上的,XGBoost预先对特征的值进行排序,然后保存为block结构
xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关
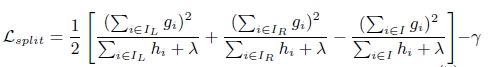
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
4)xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率
5)列抽样。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
凡是这种循环迭代的方式必定有停止条件,什么时候停止呢:
(1)当引入的分裂带来的增益小于一个阀值的时候,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有点预剪枝的意思(其实我这里有点疑问的,一般后剪枝效果比预剪枝要好点吧,只不过复杂麻烦些,这里大神请指教,为啥这里使用的是预剪枝的思想,当然Xgboost支持后剪枝),阈值参数为γγ 正则项里叶子节点数T的系数(大神请确认下);
(2)当树达到最大深度时则停止建立决策树,设置一个超参数max_depth,这个好理解吧,树太深很容易出现的情况学习局部样本,过拟合;
(3)当样本权重和小于设定阈值时则停止建树,这个解释一下,涉及到一个超参数-最小的样本权重和min_child_weight,和GBM的 min_child_leaf 参数类似,但不完全一样,大意就是一个叶子节点样本太少了,也终止同样是过拟合;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号