分布式系统(一)——同步问题
分布式系统的优势就是可以将多个计算机结点一起协调工作,完成一个单机难以解决的大任务。如果这个任务是纯计算型的,而且可以拆分为若干个独立的计算,即一个计算结果不需要依附另一个计算结果的完成。那么便可以将这个大的计算任务进行拆分,分配到不同结点来完成,最后汇总结果。
上述任务并不涉及到同步问题,但是在分布式系统中,还有很多的任务需要多个结点间的协同工作,就好比在一个公司内不同的职员需要做不同的工作,大家为了完成一个任务可能需要相互配合来完成,彼此之间的任务具有依赖性,一个人的工作进度可能影响整个任务的完成。不同的职员就好比分布式系统中的结点,为了完成一个任务,不同的结点明确自己在什么时间应该做什么事,就是同步。在现实生活中,这个问题相对好解决,因为每个人无时无刻都知道准确的北京时间,大家可用同一个时间来约束彼此的工作行为,相互配合完成工作,但是在分布式系统中,问题便有些复杂,因为每个机器结点的时间并不一定是一致的,各自的误差不同导致经过时间的积累导致大家手中的时间不一致,会导致任务同步出错,甚至导致灾难性后果。
要解决同步问题,最先想到的就是和现实生活中一样,整个集群同步统一时钟(全局时钟),可以利用卫星,这种方式确实可行,但是成本开销比较大,而且很多环境中不一定能接收到卫星信号。
第二种方法就是计算机结点不利用外部的时间去对时,而是自己内部之间的时钟进行对时。
首先看两种算法:

Cristian算法有统一的服务器对时,所有的结点和这个内部服务器进行对时,但是不同的结点离服务器距离有一定差距,因为有传输时间,所以不够精确。
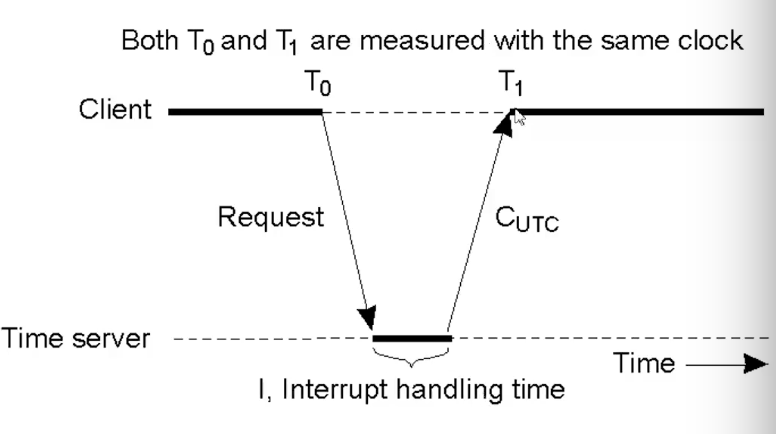
可以粗糙的用(t1-t0)/2来估计传输时间,来减去误差。
Berkeley算法没有统一外部服务器,内部自己来进行。
思想:多个机器求平均,这样误差相互抵消,机器越多越接近真实时间。
以上两种属于全局统一物理时钟,都是通过对时来完成。但是对时代价太高(对时频率需要很高,网络通信浏览大,不去进行昂贵的对时是我们追求的)于是想到逻辑时钟的概念。
首先介绍Happens-Before概念:因为很多应用的同步问题并不一定需要精确到同样的时间,可以仅仅是一个先后顺序的约束,只定义谁先谁后,去掉不必要的时钟同步,仅仅在需要同步的两台机器上进行同步就可以了,解决物理时钟不知道什么时候同步,频率难以控制的问题。
规则:
解释:HB1很好理解,对于单机来说只有一个执行的先后顺序;HB2的意思是接收消息的时候调时间。保证接受机器的时间不能小于发送机器发送时的时间;HB3指happens—before关系具有传递性。
举例:
图中abcdf有happens before关系,而a,e执行先后没有规定,都可以。
逻辑时钟就是基于happens before关系建立起来的。
逻辑时钟的一个实现:
顺序计数器 (lamport时钟)

举例:
(上图发送没问题,回来的过程有问题,需要按规则修改) 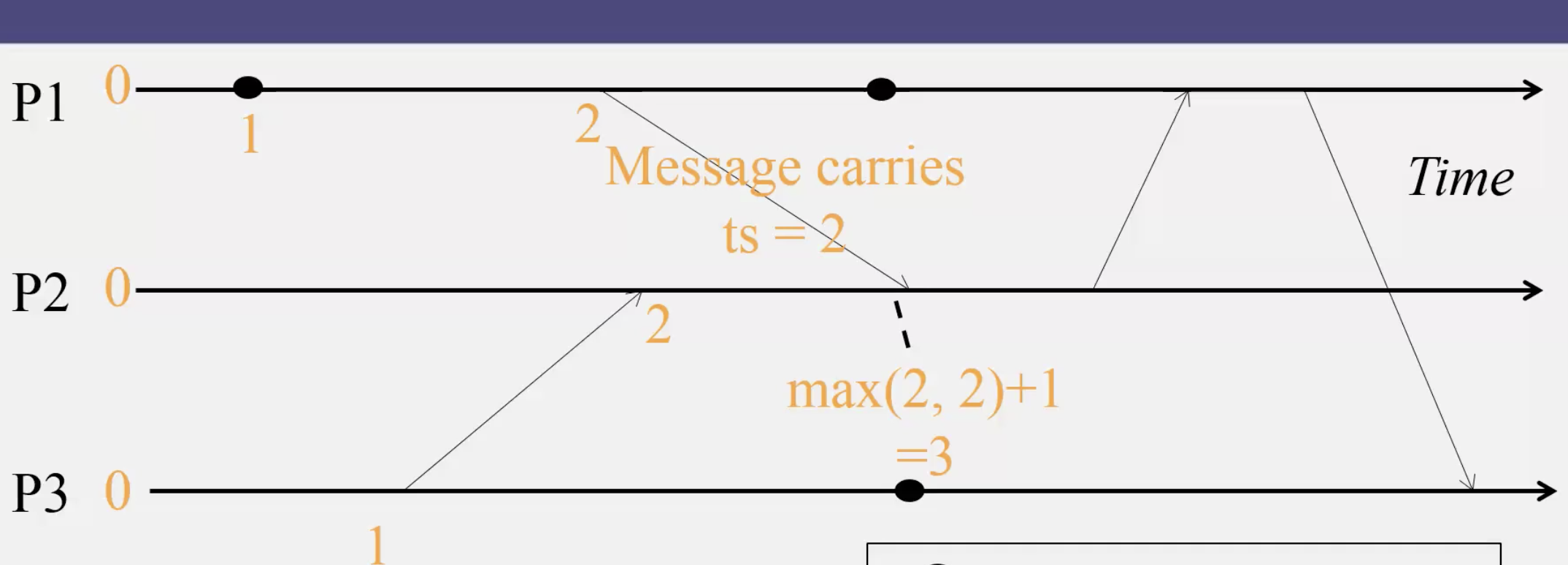
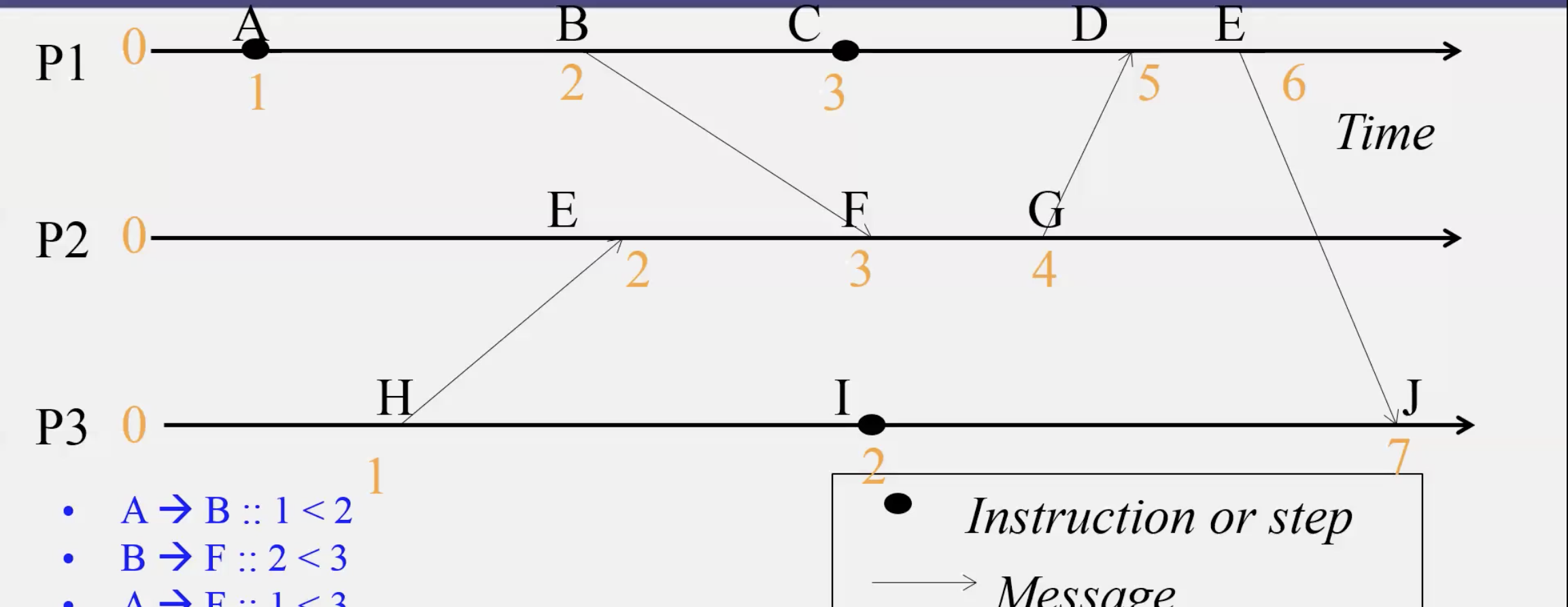
ps:ab之间有happenbefore关系则a值小于b值(如H和E),但是如果a值小于b值则不一定a在b之前,比如图中C3 H1,但是H和C的先后顺序不确定。即数字大小并不能推出先后关系。
这就是逻辑时钟的问题,仅凭数字时间无法推测出时间发生的先后顺序,想像QQ群场景,AB发送消息,A先发B后发,按理应该C接受A、B这么一个顺序,但是用lamport时钟,A为3B为5,无论先A,改成4,然后B改成6还是先B改成6后A不变,最后都是6,没什么差别,这时顺序图都是一样的,无法保证接收AB的先后性(发送可以保证),也就是之前说的数字没法控制先后顺序。要想实现这种因果序列,则需要矢量时钟。可以用全局序(QQ场景可以统一server,然后各个节点去拉取,有服务器一般都可以大大简化系统设计难度。(选举的集中式比纯分布式简化很多,我的理解就像zab和paxos这种区别。)集中式也是被广泛运用的),如果没有服务器或不能做全局序(纯分布式lamport时钟实现代价太大),就要用其他方法。于是就有了第三类向量时钟。更深入的学习向量时钟,参考博文:分布式系统:向量时钟

