正则表达式学习
正则表式(Regular Expression)简写为regex、regexp或RE
正则表达式(相对于找规律),正则表达式是对字符串操作的一种逻辑公式,用事先特定好的一些字符。作用:正则表达式主要用来验证、搜索和替换
正则表达式是一个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式通常被用来检索、替换那些某个模式的文本。用老师的话来说就是找规则,总结出规则来匹配你要找的字符。
正则表达式表:
|
正则字符 |
释义 |
举例 |
|
+ |
前面元素至少出现一次 |
ab+:ab、abbbb 等 |
|
* |
前面元素出现0次或多次 |
ab*:a、ab、abb 等 |
|
? |
匹配前面的一次或0次 |
Ab?: A、Ab 等 |
|
^ |
作为开始标记 |
^a:abc、aaaaaa等 |
|
$ |
作为结束标记 |
c$:abc、cccc 等 |
|
\d |
数字 |
3、4、9 等 |
|
\D |
非数字 |
A、a、- 等 |
|
[a-z] |
A到z之间的任意字母 |
a、p、m 等 |
|
[0-9] |
0到9之间的任意数字 |
0、2、9 等 |
下面是正则表达式的匹配模式
g: 表示全局(global)模式,表示pattern会应用于所有字符串,而不是找到一个匹配项后立即停止。
i :表示不区分大小写(ignore)模式。即忽略pattern和字符串的大小写。
m:表示多行(multiple)模式。 即到一行文本末尾时还会继续查找下一行中是否存在匹配的项。
练习:
在正则表达式中最间单最粗暴的就是纯文本匹配,刚开始学习的时候。听到说纯文本也是正则表达式也是惊了。接触过的正则都是各种字符组成的奇怪的字符。
也就是说要匹配1,那就打1.这可谓是最简单的正则匹配了。
1.验证字符串的组成规则,第一个须为数字,后面可以是字母、数字、下划线,总长度为5-20位
/^\d{1}[\w|_|\d]{4,19}$/
2.让2013-6-7 变成 2013.6.7
var str = '2013-06-07' str.replace(/-/g,'.') 或者 let regExp = /-/g; str.replace(regExp, '.')
3.请使用正则取出:Tech,Sales,内容1,内容2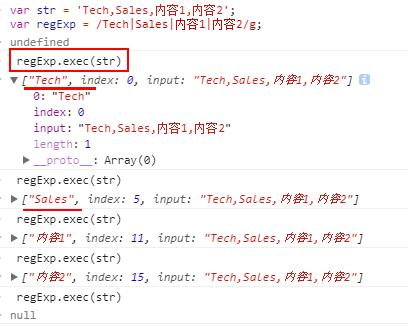
str.match(regExp) //-------- ["Tech", "Sales", "内容1", "内容2"]
4. var str = "get-element-by-id";改成驼峰命名
let regExp = /-(\w)/g; str= str.replace(regExp, function(word) { return word.substring(1).toUpperCase(); })
5. 单词首字母都大写
var name = ' han mei mei'; name = name.replace(/\b\w+\b/g, function(word){ return word.substring(0,1).toUpperCase()+word.substring(1);} );
6.从一个字符串中提取链接地址。
var str = 'IT面试题博客中包含很多 <a href="http://hi.baidu.com/mianshiti/blog/category/微软面试题">微软面试题</a>'; var regExp = /<a(?: [^>]*)+href="(.*)"(?: [^>]*)*>/; console.log(str.match(regExp)[1])
7.用正则表达式匹配邮箱
在新学习了正则规律中,一般情况下,看到下面的这句。
您好这是我的邮箱:Abc2334464@qq.com。请收到留言后给我回复
最先都是想到的这样匹配它的
(?<=:).+?(?=,)
这里使用了(?<=exp):零宽后行断言,它匹配文本中的某些位置,这些位置的前面能给定的前缀匹配exp,(?=exp):一个点加一个+号表示:.可以匹配任意字符,+加号代表着限定符表示连接。?号是:懒惰模式(尽可能少的匹配,因为默认下正则表达示是贪婪模式,有多少匹配多少)零宽先行断言,它匹配文本中的某些位置,这些位置的后面能匹配给定的后缀exp。在上面中这句中能成功匹配。但是有局限的。看了正则文档发现还有更好的匹配方式。这能更好的匹配到绝大多数的邮箱。
Email地址:
^\w+([+.]\w+)@\w+([.]\w+).\w+([.]\w+)*$
这里的匹配:
^ 匹配字符串的开始
$ 匹配字符串的结束
\ 转义符 在一些语言中在符号会代表着特定的功能,转义字符的可以更好识别。
9.去掉以下字符串中所有的字母
“aaaa1ahNvuhfewoi11384209e7439fsDhfdohd8892489”
[a-zA-Z] 匹配字母大小写,这里匹配出来后将匹配的字符替换成空,即可去掉字符中所有的字母。


10.匹配的用户密码(以字母开头、内容可包含数字、字母、下划线)Acb_88dcfsv
[a-zA-Z]{1}/w{7-9}这里的[]号里的匹配的是大以大小写字母开始的,后面的花括号则是匹配的是一位数。\w匹配的则是数字字母下划线后面的花括号则是需要匹配的多少位。
11.将以下内容中标签的样式全部去掉
<p class="Normal" style="text-align:justify;page-break-inside:auto;page-break-after:auto;page-break-before:auto;margin-top:0pt;margin-bottom:
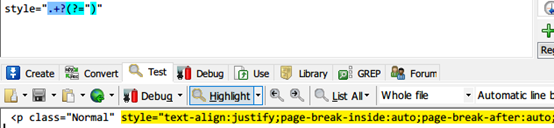
上面以style=”纯文本字符,也就是特定字符开始匹配,后面加一个零宽先行断言以双引号结尾。这样便匹配了sytle标签里的样式,去掉它也是替换它为空即可。
通过一些练习,可以更好的了解正则表达式,了解它的匹配规律。不难发现。正则表达式的高效实用。巧用正则表达式可以让程序开发更具效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号