

mysql 优化相关
一.show [session|global] status 了解各种sql的执行频率
session(默认): 表示当前连接的统计结果
global:表示自数据库上次启动至今的统计结果
1.show status like "Com_%"
Com_xxx 表示每个xxx语句执行的次数,我们通常查看的是以下几个统计参数:
Com_select:执行select操作次数,一次查询累加1
Com_insert:执行insert操作次数,对于批量插入的insert,只累加1次
Com_update:执行update操作的次数
Com_delete:执行delete操作的次数
2.show status like "Innodb_%"
Innodb_rows_read:select查询返回的行数
Innodb_rows_inserted:执行insert操作插入的行数
Innodb_rows_updated:执行update操作更新的行数
Innodb_rows_deleted:执行delete操作删除的行数
3.show status like"slow_%"
Slow_queries:慢查询的次数
二.explain分析低效SQL的执行计划
相关字段对应的属性
1.select_type:表示select的类型,常见的取值有
SIMPLE(简单表,即不使用表连接或者子查询)
PRIMARY(主查询,即外层的查询)
UNION(UNION中的第二个或者后面的查询语句)
SUBQUERY(子查询中的第一个SELECT)
2.table:输出结果集的表
3.type:表示MySQL在表中找到所需行的方式,或者叫访问类型
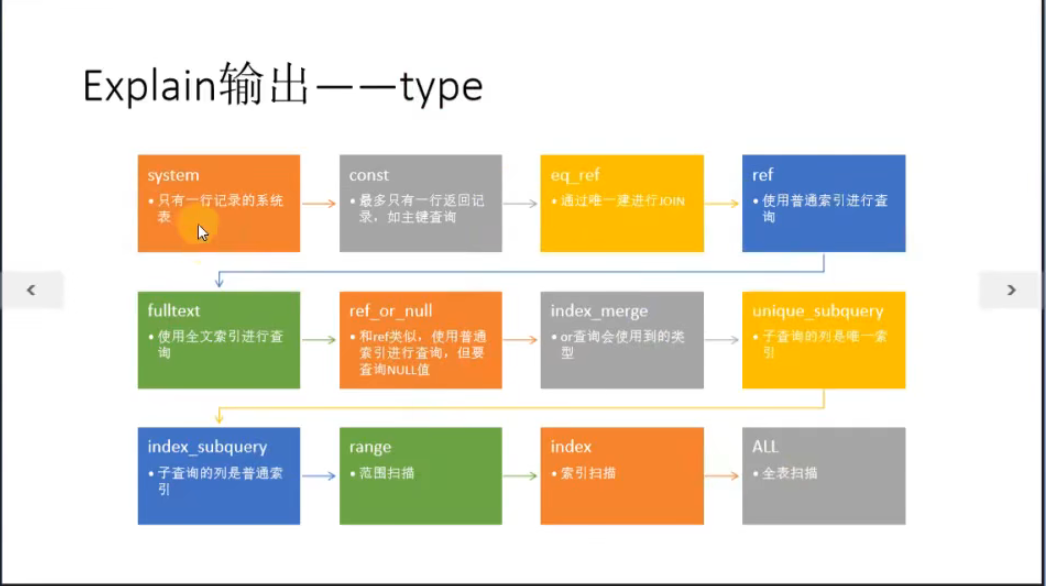

从左至右,性能由最差到最好
(1)ALL:全表扫描,MySQL遍历全表来找到匹配行
(2)index:索引全扫描,MySQL遍历整个索引来查询匹配行
(3)reange:索引范围扫描,常见于<、<=、>、>=、between等
(4)ref:使用非唯一索引扫描或唯一索引的前缀扫描,返回匹配某个单独值得记录行
(5)eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条匹配记录;即多表连接中使用primary key或者unique index作为关联条件
(6)const/system:单表中最多有一个匹配行,例如主键primary key 或者唯一索引unique index
(7)NULL:MySQL不用访问表或者索引就只能能够得到结论
type还有其他值,如ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)、index_merge(索引合并优化)、unique_subquery(in的后面是一个查询主键字段的子查询)、index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)
4.possible_keys:表示查询时可能使用的索引
5.key:表示实际使用的索引
6.key_len:使用到索引字段的长度
7.rows:扫描的行的数量
8.Extra:执行情况的说明和描述
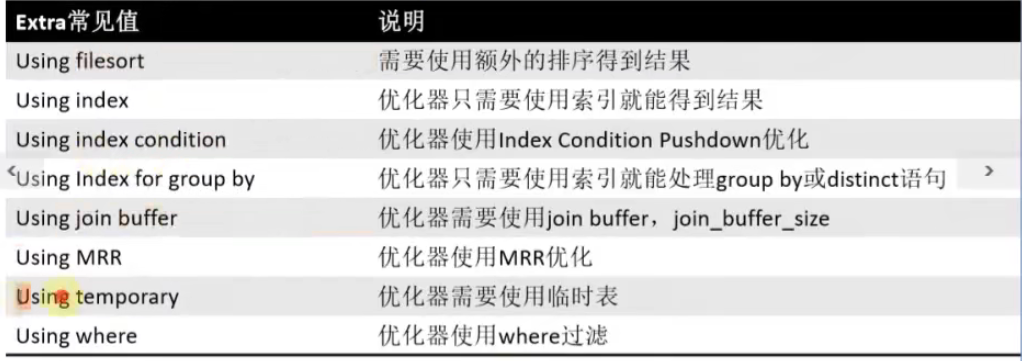
Using where(表示优化器除了利用索引来加速访问之外还需要根据索引回到表去查询数据)
Using index(表示直接访问索引就足够获取到所需要的数据)
Using filesort(表示虽然访问了索引就能够获取需要的数据,但是SQL中还需要额外的排序)
排序索引不生效场景:
order by key desc key2 asc.即使2个字段都创建了索引 但是只要排序顺序不统一则还需要额外的排序
where key1=xxx order by key2 desc.用于查询的关键字与排序的字段不一致
order by key3,key4.用非索引字段排序
Using temporary(表示是否使用了临时表)
三.优化相关语法
GROUP BY 排序:
group by时会同时的根据group by关键字做一次排序,如果使用group by key1 order by null 则可以在分组后避免消耗资源去额外的排序。
嵌套查询:
select * from tableA where key1 not in (select key1 from tableB )
==》
select * from tableA a left join tableB b on a.key1=b.key1 where b.key1 is null
OR:
where key1= xxx or key2 = xxx 可以创建key1 key2的索引来提升or的效率(如果where表达式中存在复合索引 那么or则不触发索引)
分页:
select * from tableA order by key1 limit 500,20;
==》
select * from tableA a inner join (select key1 from tableA order by key1 limit 500,20) b on a.key1 = b.key1;
如果排序字段key1创建索引 则优化后的语句效率更显著。

