43-缓冲区管理
缓冲区管理
缓冲区是一个存储区域,可以由专门的硬件寄存器组成,也可以利用内存作为缓冲区
利用硬件作为缓冲区的成本较高,容量也较小.一般仅用在对速度要求非常高的场合,由于对页表的访问频率极高,因此使用速度很快的联想寄存器来存放页表项的副本。
一般情况下,更多的是利用内存作为缓冲区
缓存区的作用
- 缓和CPU和I/O设备之间速度不匹配的矛盾
- 减少对CPU的中断频率,放宽对CPU中断相应时间的限制
- 解决数据颗粒度不匹配的问题
- 提高CPU与I/O设备之间的并行性。
缓冲区策略
单缓冲区
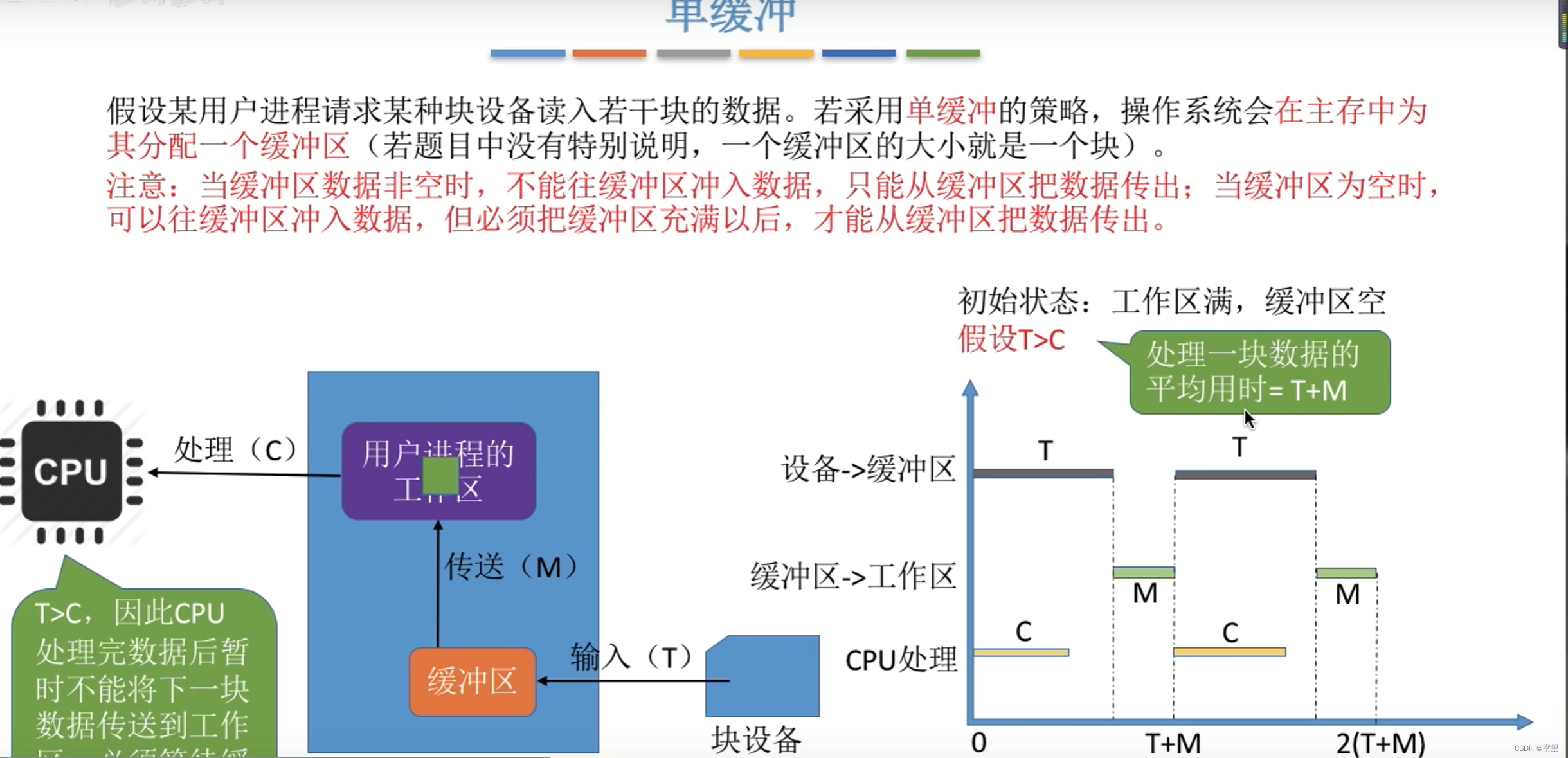
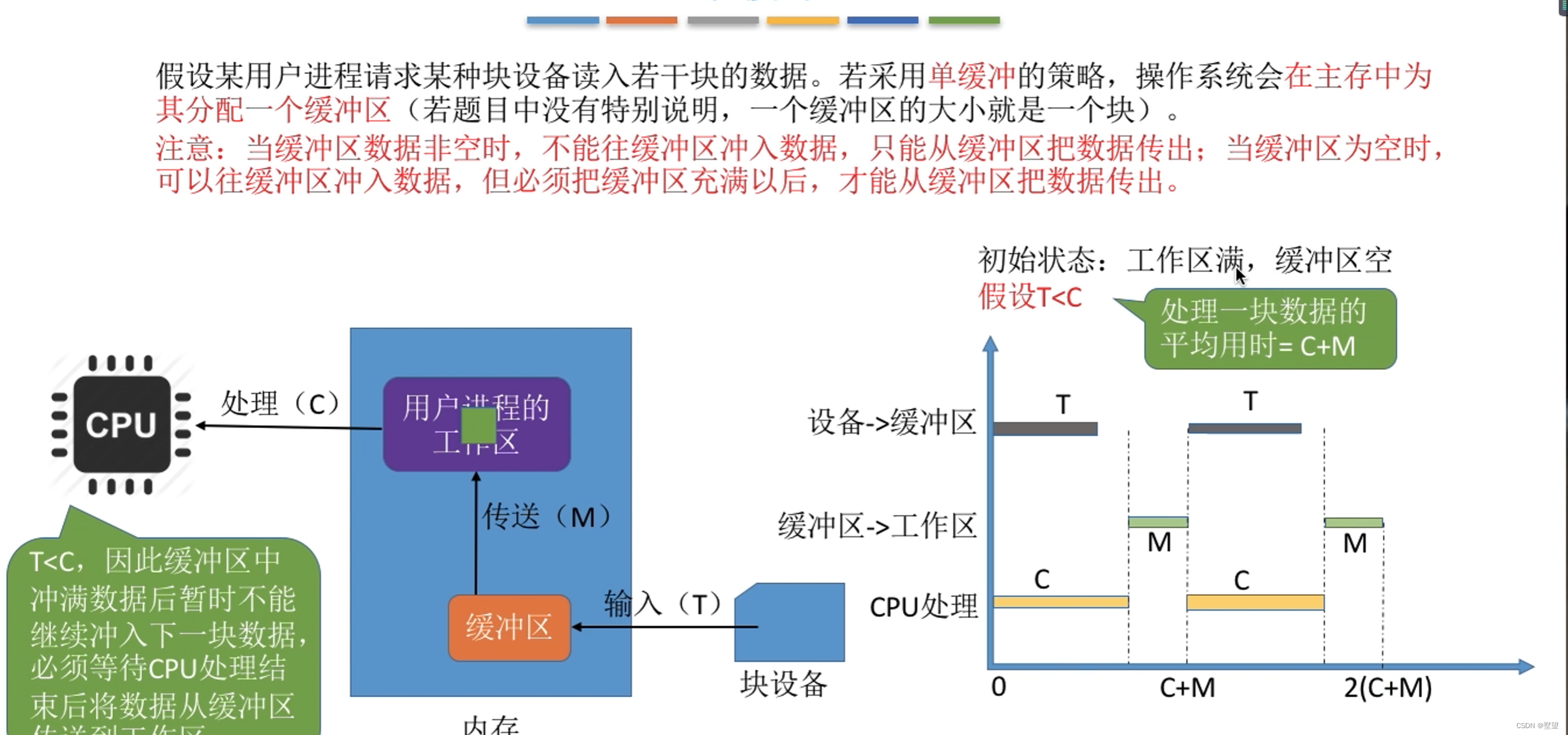
假设某用户进程请求某种块设备读入若干块的数据。若采用单缓冲的策略,操作系统会在主存中为其分配一个缓冲区
注意:当缓冲区数据非空时,不能往缓冲区冲入书,只能把缓冲区的数据传出;当缓冲区为空时;可以往缓冲区读入数据,但必须把缓冲区充满以后,才能从缓冲区把数据传出。
用户进程的内存空间时,会分出一片工作区来接受输入/输出数据(一般也默认工作区大小与缓冲区大小相同)
T>C
T小于C
双缓冲
假设某用户进程请求某种块设备读入若干块的数据。若采用双缓冲的策略,操作系统会在主存中为其分配两个缓冲区
情况1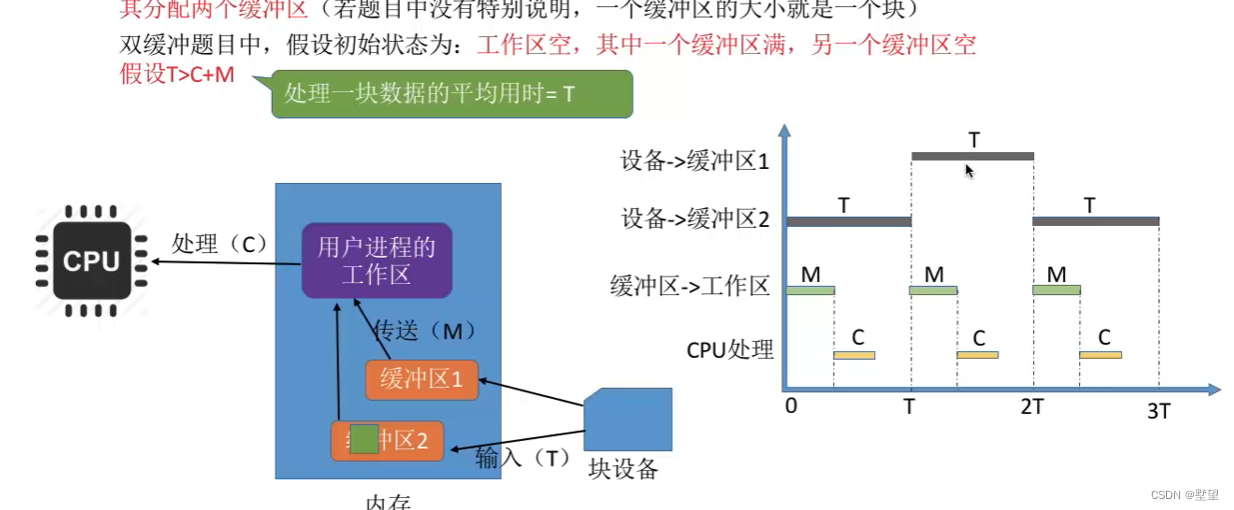
情况2
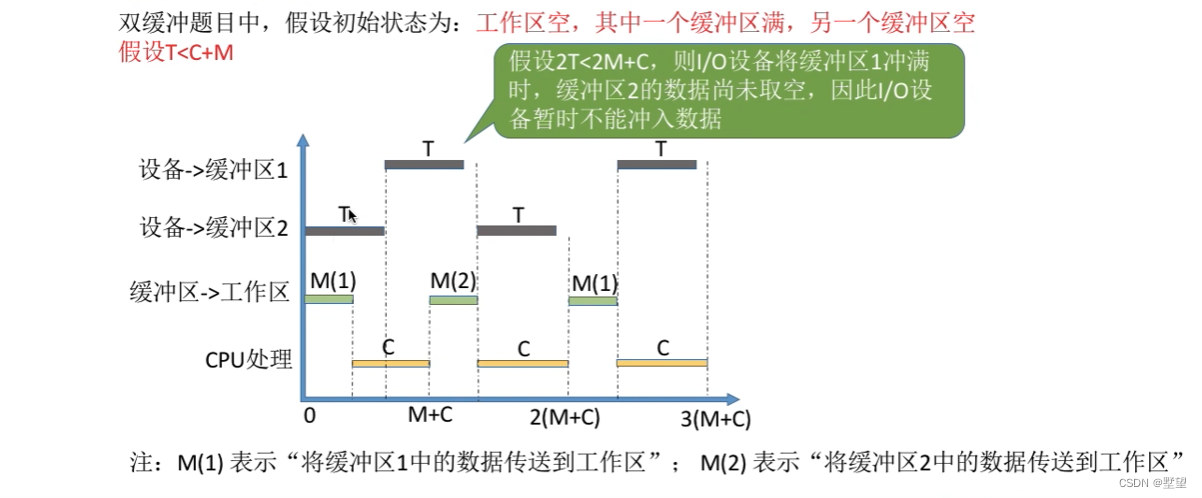
当T<C+M时,意味着设备输入数据块的速度要比处理机处理数据块的速度更快。每处理一个数据块平均耗时C+M.
采用双缓冲策略。处理一个数据块的平均耗时Max(T,C+M)
使用单缓冲/双缓冲在通信时的区别
类比单通道和双通道
- 若两台相互通信的机器只设置单缓冲,在任一时刻只能实现数据的单向传输。
- 若两台相互通信的机器设置双缓冲,则同一时刻可以实现双向传输
其实管道通信中的管道就是缓冲区。要设置数据的双向传输,必须设置两个管道
循环缓冲区
将多个大小相等的缓冲区链接成一个循环队列
in指针:指向下一个可以冲入数据的空闲缓冲区
out指针:指向下一个可以取出数据的满缓冲区
缓冲池
缓冲池由系统中共用的缓冲区组成,可以根据使用状况分为空缓冲队列,装满输入数据的缓冲队列,装满输出数据的缓冲队列。
另外,根据一个缓冲区在实际运算中扮演的功能不同,又设置了四种工作缓冲区,用于收容输入数据的工作缓冲区(hin),用于提取输入数据的工作缓冲区(sin),用于收容输出数据的缓冲区(hout),用于提取输出数据的工作缓冲区(sout)
var code = “ed7452a5-e1b3-4798-9fdf-5c75813ba1e5”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号