
遗传算法解决旅行商问题(TSP)
遗传算法解决旅行商问题
- 作者:Cukor丘克
- 环境:MatlabR2020a + vscode
问题描述
旅行商问题(TSP). 一个商人欲从自己所在的城市出发,到若干个城市推销商品,然后回到其所在的城市。如何选择一条周游路线,使得商人经过每个城市一次且仅一次后回到起点,并使他所走过的路径最短?
TSP 即Travelling Salesman Problem. 中文翻译过来就是旅行商问题。
旅行商问题是一个典型的NP难问题。NP指的是Non-deterministic Polynomial,即多项式复杂程度的非确定性问题。由于该问题的组合特性,旅行商问题已成为测试新算法的标准问题,如模拟退火、神经网络和演化算法等都用旅行商问题作为测试用例。旅行商问题的一个实例可由一个距离矩阵所给定。
用遗传算法求解旅行商问题时,适应函数可以取为目标函数或目标函数的一个简单变换,选择策略可以是轮盘赌选择,所以算法设计的重点主要集中在以下三个方面:
- 采用适当的方法对周游路线编码
- 设计专门的遗传算子,以避免不可行性
- 防止过早收敛
下面讨论周游路线常用的几种表示及其相应的遗传算子。
周游路线编码
主要有3种编码表示
- 近邻表示
- 次序表示
- 路径表示
近邻表示
近邻表示将一条周游路线表示成\(n\)个城市 的一个排列\(Π=(Π_1,Π_2,...,Π_n)\),\(Π_i=j\)当且仅当周游路线中从城市\(i\)到达的下一个城市为\(j\).
例如,排列
\((2~4~8~3~9~7~1~5~6 )\)
表示周游路线为\(1-2-4-3-8-5-9-6-7-1.\)
显然,每一条周游路线都对应一个近邻表示,但任一近邻排列却不一定对应于一条周游路线。
例如,排列
\((2~4~8~1~9~3~5~7~6)\)
导致了不完全回路\(1-2-4-1\),因而无法对应一条周游路线。所以周游路线的近邻表示就没有必要再往下介绍。
次序表示
次序表示将一条周游路线表示为\(n\)个城市的有序表,其中,表中的第\(i\)个元素在\(1\)到\(n-i+1\)取值。该表的一个优点是每一个次序表示都对应于一条合法的周游路线。
次序表示的基本思想是:取\(n\)个城市的某个排列\((Π_1,Π_2,...,Π_n)\)作为参照排列,通常取\((1,2,...,n)\)作为参照排列,然后将周游路线中的城市按照其在参照排列中的次序记录下来,形成一个具有\(n\)个元素的有序表.具体做法如下:
对给定的一条路径\(Π_1-Π_2-...-Π_n\),首先记录城市\(Π_1\)在参照排列\((p_1,p_2,...,p_n)\)中的次序\(i_1\),将\(Π_1\)从\((p_1,p_2,...,p_n)\)中删除得\(n-1\)个城市的参照排列\((q_1,q_2,...,q_k),k=n-1\),再记录城市\(Π_2\)在参照排列\((q_1,q_2,...,q_k),k=n-1\)中的次序\(i_2\),然后将城市\(Π_2\)从\((q_1,q_2,...,q_k),k=n-1\)中删除得\(n-2\)个城市的参照排列\((r_1,r_2,...,r_k), k=n-2\),以此类推,直到城市\(Π_n\)的次序\(i_n\)记录下来为止。有序表\((i_1,i_2,...,i_n)\)称为路径\(Π_1-Π_2-...-Π_n\)的次序表示。注意\(i_j\)的取值范围为\(1 \le i_j \le n-j+1\).
例如,若取\((1,2,...,9)\)作为参照排列,那么路径
\(1-2-4-3-8-5-9-6-7\)
的次序表示为
\((1~1~2~1~4~1~3~1~1)\).
虽然次序表示具有可以使用传统杂交算子的优点,但实验表明在次序表示与传统的杂交算子相结合所得到的结果并不理想。
路径表示
路径表示也许是周游路径最自然的一种表示。例如,一条周游路线
\(5-1-7-8-9-4-6-2-3-5\)
可表示为排列\((5~1~7~8~9~4~6~2~3)\),这里将排列看成一个首尾相接的圆形排列。
本次案例对周游路线的编码采用路径表示的方案。
杂交
路径表示的杂交算子主要有以下几个:
- 部分映射杂交
- 次序杂交
- 循环杂交
- 基于位置杂交
部分映射杂交
部分映射杂交算子通过从一个父体中选择一个子序列,并尽可能多地保持另一个父体中城市的次序和位置的方式产生 后代。具体过程如下:
对给定的两个父体\(p_1,p_2\),部分映射杂交首先随机地在父体上选择两个杂交点,然后交换父体\(p_1,p_2\)在这两点之间的中间段得到两个后代\(o_1,o_2\),这一交换同时定义了一个部分映射。这时,\(o_1,o_2\)上除了这两点之间的城市外,其他的城市尚未确定。对\(o_1,o_2\)中尚未确定的城市,分别保留各自父体 中与中间段无冲突的城市,对与中间段有冲突的城市,则执行部分映射,直到与中间段无冲突为止,再将该城市填入相应的位置即可。
例如,给定下列两个父体,随机地选择两个杂交点 (以"|"标记),
\(p_1=(2~6~4~|~7~3~5~8~|~9~1),\)
\(p_2=(4~5~2~|~1~8~7~6~|~9~3),\)
将\(p_1,p_2\)在这两点之间 的中间段交换得
\(o_1=(\#~\#~\#~|~1~8~7~6~|~\#~\#),\)
\(o_2=(\#~\#~\#~|~7~3~5~8~|~\#~\#),\)
其中,\(\#\)表示待定城市。这一交换所确定的部分映射为
\(1<->7,\)
\(8<->3,\)
\(7<->5,\)
\(6<->8.\)
然后,再从各自父体中填入与中间段无冲突的城市得
\(o_1=(2~\#~4~|~1~8~7~6~|~9~\#),\)
\(o_2=(4~\#~2~|~7~3~5~8~|~9~\#),\)
对\(o_1,o_2\)中与中间段有冲突的\(\#\)部分,执行部分映射,直到无冲突为止。例如,\(o_1\)中的第一个\(\#\)初始为6,但6与中间段中的城市冲突,部分映射将6映射到8,但8仍与中间段冲突,部分映射到3,3与中间段不冲突,这时第一个\(\#\)填入3.类似地可以确定其他的\(\#\)部分,最后所得到的\(o_1,o_2\)如下:
\(o_1=(2~3~4~|~1~8~7~6~|~9~5),\)
\(o_2=(4~1~2~|~7~3~5~8~|~9~6),\)
部分映射杂交实现起来比较麻烦,跳来跳去的,所以本次案例不适用部分映射杂交。
次序杂交
次序杂交算子通过从一个父体中选择一个子序列,并保持另一个父体中城市的相对次序的方式产生后代。具体操作如下:
对给定的两个父体\(p_1,p_2\),次序杂交首先随机地再父体上选择两个杂交点,分别保留父体\(p_1,p_2\)在这两个杂交点之间的中间段得到两个后代\(o_1,o_2\).这时\(o_1,o_2\)上除了这两个中间段中的城市外,其他的城市尚未确定。对\(o_1\)中尚未确定的城市,首先将\(p_2\)中的城市从第二个杂交点开始按其相对次序列出,然后将该序列中在\(o_1\)中间段中出现的城市删除,再将剩余子序列从第二个杂交点填入\(o_1\)的相应位置即可。同样的方式可得\(o_2\).
例如,给定下列两个父体,随机地选择两个杂交点,
\(p_1=(2~6~4~|~7~3~5~8|~9~1),\)
\(p_2=(4~5~2~|~1~8~7~6~|~9~3),\)
保留\(p_1,p_2\)上两个杂交点之间的中间段得
\(o_1=(\#~\#~\#~|~7~3~5~8~|~\#~\#),\)
\(o_2=(\#~\#~\#~|~1~8~7~6~|~\#~\#),\)
其中,\(\#\)表示待定城市。然后从第二个杂交点 开始,将\(p_2\)中的城市按原次序列出得
\(9-3-4-5-2-1-8-7-6,\)
从中删除\(o_1\)中间段中的城市得
\(9-4-2-1-6.\)
将该子序列从第二个杂交点开始依次填入到\(o_1\)中得
\(o_1=(2~1~6~|~7~3~5~8~|~9~4),\)
类似可得
\(o_2=(4~3~5~|~1~8~7~6~|~9~2).\)
本次案例使用的杂交算子就是次序杂交。
循环杂交
循环杂交算子如下产生后代:后代中的每个城市是某个父体相应位置的城市。具体过程如下:
对给定的两个父体\(p_1=(u_1,u_2,...,u_n)\),\(p_2=(v_1,v_2,...,v_n)\),先确定后代\(o_1\)中来自于父体\(p_1\)中的城市。假定\(p_1\)中的第一个城市\(u_1\)在\(o_1\)中,即将\(o_1\)中的第一个位置填入\(u_1\),那么\(o_1\)中的城市\(v_1\)不可能来自\(p_2\),必来自于\(p_1\).假设\(v1=u_1\),若\(u_i\)还没填入\(o_1\)中,则在\(o_1\)的第\(i\)个位置上填入\(u_i\).同样,\(o_1\)中的城市\(v_i\)不可能来自\(p_2\),必来自于\(p_1\).假设\(v_i=u_i\),若\(u_j\)还没有填入\(o_1\)中,则在\(o_1\)的第\(j\)个位置上填入\(u_j\).这样继续下去直到将某个\(u_k\)填入到\(o_1\)后,\(p_2\)中与其相应的城市\(v_k\)也已经填入到\(o_1\)为止,这就构成一个循环。再将\(p_2\)中尚未在\(o_1\)中出现的城市直接填入到\(o_1\)中相应的位置即可。类似可得后代\(o_2\).
例如,给定下列两个父体:
\(p_1=(2~6~4~7~3~5~8~9~1),\)
\(p_2=(4~5~2~1~8~7~6~9~3),\)
先从\(p_1\)中取第一个城市2作为\(o_1\)的第一个城市得
\(o_1=(2~\#~\#~\#~\#~\#~\#~\#~\#).\)
\(p_1\)中城市2对应\(p_2\)中的城市4,而4还没有填入到\(o_1\)中,将4填入到\(o_1\)中得
\(o_1=(2~\#~4~\#~\#~\#~\#~\#~\#).\)
\(p_1\)中城市4对应\(p_2\)中的城市2,但2已经填入\(o_1\)中了,这完成了一个循环。将\(p_2\)中尚未在\(o_1\)中出现的城市直接填入到\(o_1\)中相应的位置后得
\(o_1=(2~5~4~1~8~7~6~9~3).\)
类似可得
\(o_2=(4~6~2~7~3~5~8~9~1).\)
基于位置杂交
基于位置杂交类似于次序杂交,唯一的区别在于:在基于位置杂交中,不是选取父体的一个连续的子序列,而是随机地选取一些位置,再按次序杂交的方式产生后代。
例如,给定下列两个父体:
\(p_1=(2~6~4~7~3~5~8~9~1),\)
\(p_2=(4~5~2~1~8~7~6~9~3),\)
假定随机地选取的位置为2,3,6,8.保留\(p_1,p_2\)上这些位置的城市得
\(o_1=(\#~6~4~\#~\#~5~\#~9~\#),\)
\(o_2=(\#~5~2~\#~\#~7~\#~9~\#),\)
然后从最后一个选取位置的后面开始,将\(p_2\)中的城市按原次序列出得
\(3-4-5-2-1-8-7-6-9,\)
从中删除\(o_1\)中已经选取的城市得
\(3-2-1-8-7.\)
将该子序列从最后一个选取位置的后面开始依次填入\(o_1\)中得
\(o_1=(2~6~4~1~8~5~7~9~3),\)
\(o_2=(6~5~2~4~3~7~8~9~1).\)
变异
路径表示的变异算子有下面几个:
- 倒位变异
- 插入变异
- 移位变异
- 互换变异
倒位变异
倒位变异的过程如下:
首先在父体上随机地选择两个城市,然后将这两个城市之间的子序列反转。
例如,设有父体
\((1~2~3~4~5~6~7~8~9).\)
假定随机地选择的两个城市为3, 7,则对该个体进行倒位变异后得
\((1~2~7~6~5~4~3~8~9).\)
插入变异
插入变异的过程如下:
首先在父体中随机地选择一个城市,然后在该城市插入到某个随机的位置上。
例如,设有父体
\((1~2~3~4~5~6~7~8~9).\)
假定随机地选择的城市为2,随机地选择位置为6,那么将城市2插入到第6个位置上得
\((1~3~4~5~6~2~7~8~9).\)
要注意的是,当将所选择的城市插入到所选择的位置上时,有两种城市移动方式。若所选择的城市在要插入的位置的左边,则所选择城市到插入位置之间的城市(包括插入位置上的城市)向左移动一个位置,否则向右移动一个位置。
移位变异
移位变异的过程如下:
首先在父体中随机地选择一个连续子序列,然后将该子序列插入到某个随机的位置上。
例如,设有父体
\((1~2~3~4~5~6~7~8~9).\)
假定随机地选择的子序列为4 5 6,随机地选择的位置是8,那么经移位变异后得
\((1~2~3~7~8~4~5~6~9).\)
互换变异
互换变异随机地选择两个城市,并将这两个城市互换。
例如,设有父体
\((1~2~3~4~5~6~7~8~9).\)
随机地选择的两个城市为3,7,那么经互换变异后得
\((1~2~7~4~5~6~3~8~9).\)
本次案例采用的变异算子是互换变异。
算法实现
本次使用Matlab来实现遗传算法解决旅行商问题。其中,所涉及到的各子函数放到附录中。
程序目录结构如下:
主函数
- main.m
%% 遗传算法解决旅行商问题
%% 清屏
clear; close; clc;
%% 加载数据
city = xlsread('./resources/city.xlsx'); % 加载Excel表格数据
%% 参数初始化
% 主要的参数
popsize = 200; % 种群大小
pc = 0.9; % 交叉概率
pm = 0.05; % 变异概率
gen = 1000; % 迭代次数
% 次要的参数
D = Distance(city); % 城市距离矩阵
[citycount, ~] = size(city); % 记录城市个数
best_fitvalue = zeros(gen, 1); % 记录每一代最优的适应值
minlen = zeros(gen, 1); % 记录每一代路径最小值
%% 初始化种群
pop = initpop(popsize, citycount);
%% 开始迭代
for it = 1:gen
fitvalue = fitness(pop, D); % 计算适应值
[best_fitvalue(it), best_index] = max(fitvalue); % 记录适应值最高的值与下标
best_solution = pop(best_index, :); % 记录当前代的最优个体
minlen(it) = decode(best_solution, D, citycount); % 记录每一代的最短路径
newpop = parent_selection(pop, fitvalue); % 父体选择
newpop = crossover(newpop, pc); % 交叉
newpop = mutation(newpop, pm); % 变异
pop = newpop; % 更新种群
pop(mod(ceil(rand * citycount), citycount)+1, :) = best_solution; % 保留最优个体
end
%% 画图
figure(1)
for i = 2:citycount
plot([city(best_solution(i-1), 1), city(best_solution(i), 1)], ...
[city(best_solution(i-1), 2), city(best_solution(i), 2)], 'bo-');
hold on;
end
plot([city(best_solution(citycount), 1), city(best_solution(1), 1)], ...
[city(best_solution(citycount), 2), city(best_solution(1), 2)], 'ro-');
title(['优化最短距离:', num2str(min(minlen))]);
figure(2)
plot(best_fitvalue);
xlabel('迭代次数')
ylabel('目标函数值')
title('适应值变化曲线')
figure(3)
plot(minlen);
xlabel('迭代次数')
ylabel('目标函数值')
title('最短路径变化曲线')
%% 打印周游路线
disp('周游路线:')
words = num2str(best_solution(1));
for i = 2:citycount
words = append(words, '->', num2str(best_solution(i)));
end
words = append(words, '->', num2str(best_solution(1)));
disp(words);
效果图:
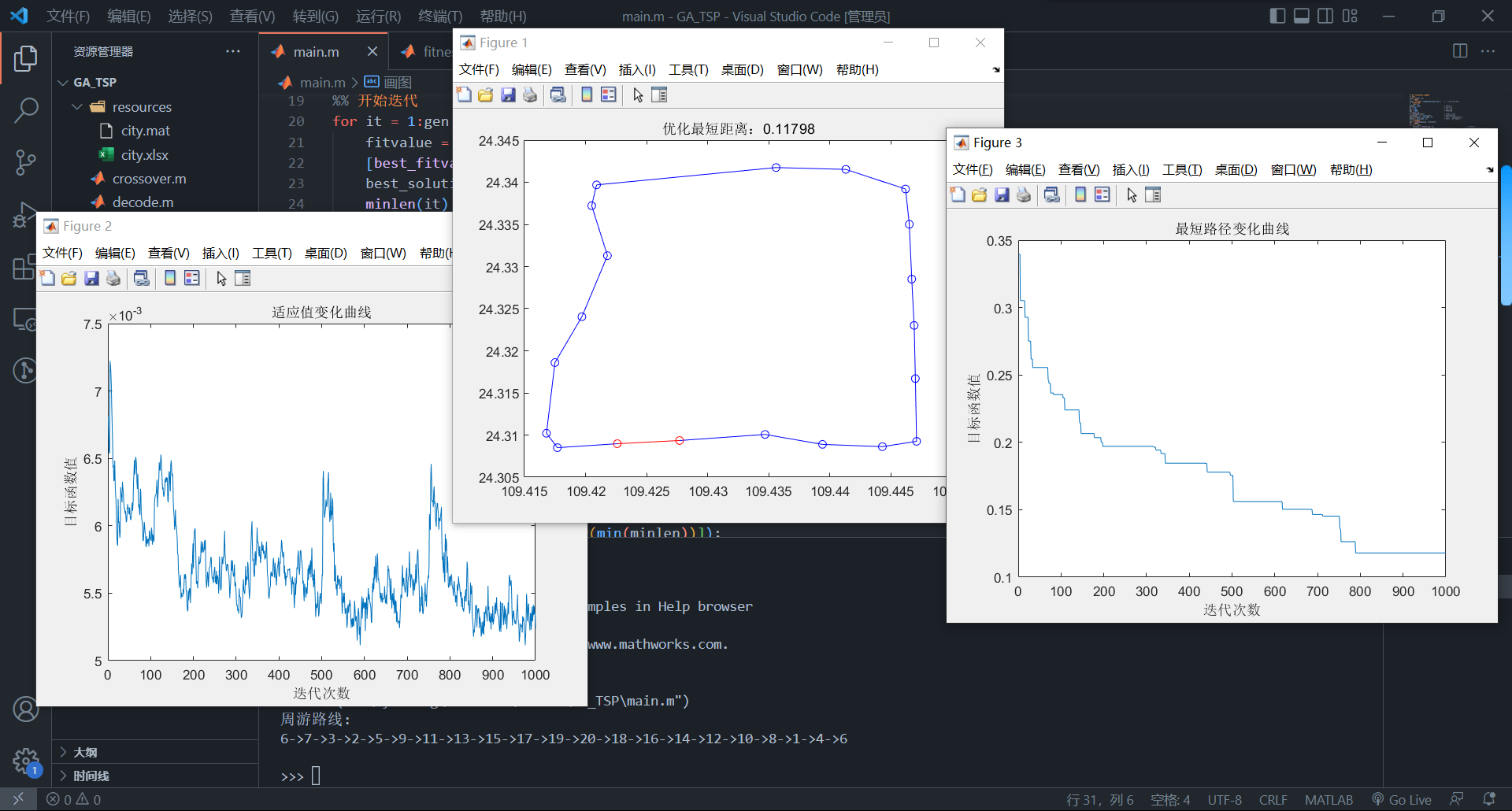
从图1中可以看到优化最短路径为0.11798(单位自己换算,一开始用的点是经纬度表示的)周游路线已绘出,没有交叉的小圈,基本上是最优解了;图2是适应值变化曲线,这个是记录每一代的最优个体的适应值,一直在波动,很符合遗传算法的随机性;图3记录的是每一代的最短路径,基本在第800代左右收敛到最优解;命令窗口也将周游路线打印出来,得本次运行的最短路线为
6->7->3->2->5->9->11->13->15->17->19->20->18->16->14->12->10->8->1->4->6。
附录
各个子函数的Matlab代码实现。
- Distance.m
function D = Distance(city)
%Distance - 计算两个城市之间的距离
%
% Syntax: D = Distance(city)
%
% Long 返回的是一个距离矩阵,记录每两个城市之间的距离
[n, ~] = size(city);
D = ones(n, n);
for i = 1:n
for j = i:n
D(i, j) = sqrt((city(i, 1) - city(j, 1)).^2 + (city(i, 2) - city(j, 2)).^2);
D(j, i) = D(i, j);
end
end
end
- decode.m
function path_len = decode(code, D, n)
%decode - 对种群个体解码
%
% Syntax: path_len = decode(code, D, n)
%
% Long 返回的是路径长度,一个1*1的矩阵(变量)
path_len = 0;
for j = 2:n
path_len = path_len + D(code(j-1), code(j));
end
path_len = path_len + D(code(n), code(1));
end
- initpop.m
function pop = initpop(popsize, citycount)
%initpop - 初始化种群
%
% Syntax: pop = initpop(popsize, citycount)
%
% Long 返回一个popsize*citycount的矩阵
pop = ones(popsize, citycount);
for i = 1:popsize
pop(i, :) = randperm(citycount);
end
end
- fitness.m
function fitvalue = fitness(pop, D)
%fitness - 计算适应值
%
% Syntax: fitvalue = fitness(pop, D)
%
% Long 返回的是px行1列的矩阵,记录的是当前种群pop的每一个个体的适应值
[px, py] = size(pop);
fitvalue = zeros(px, 1);
for i = 1:px
fitvalue(i) = decode(pop(i, :), D, py);
end
fitvalue = 1./fitvalue;
fitvalue = fitvalue./sum(fitvalue); % 适应值归一化
end
- parent_selection.m
function newpop = parent_selection(pop, fitvalue)
%parent_selection - 父体选择
%
% Syntax: newpop = parent_selection(pop, fitvalue)
%
% Long 返回和pop一样大小的矩阵,新种群,采用轮盘赌选择策略
[px, py] = size(pop);
newpop = zeros(px, py);
%% 设计轮盘
p = cumsum(fitvalue); % 在计算适应值函数中已经做好归一化
%% 转动轮盘
r = sort(rand(px, 1));
j = 1;
for i = 1:px
while r(i) > p(j)
j = j + 1;
end
% r(i) <= p(j)
newpop(i, :) = pop(j, :);
end
end
- crossover.m
function newpop = crossover(pop, pc)
%crossover - 交叉
%
% Syntax: newpop = crossover(pop, pc)
%
% Long description
[px, ~] = size(pop);
newpop = pop;
for i = 2:2:px
if rand <= pc
[newpop(i, :), newpop(i-1, :)] = sub_crossover(pop(i, :), pop(i-1, :));
end
end
end
function [newcode1, newcode2] = sub_crossover(code1, code2)
%sub_crossover - 子交叉函数
%
% Syntax: [newcode1, newcode2] = sub_crossover(code1, code2)
%
% Long 采用次序杂交的方式进行杂交
newcode1 = code1;
newcode2 = code2;
n = length(code1);
front = -1;
rear = -1;
while front < 1 || rear <= front || rear >= n
front = ceil(rand * n);
rear = ceil(rand * n);
end
p2 = code2;
p1 = code1;
for i = front:rear
p2(p2 == code1(i)) = [];
p1(p1 == code2(i)) = [];
end
j = 1;
for i = 1:n
if i < front || i > rear
newcode1(i) = p2(j);
newcode2(i) = p1(j);
j = j + 1;
end
end
end
- mutation.m
function newpop = mutation(pop, pm)
%mutation - 变异
%
% Syntax: newpop = mutation(pop, pm)
%
% Long 采用互换变异算子
[px, py] = size(pop);
newpop = pop;
cnt = ceil(rand*py/2); % 确定变异点的个数
pos = mod(ceil(rand(px, cnt) * py), py) + 1; % 变异点的位置
for i = 1:px
if rand <= pm
for j = 2:2:cnt
temp = newpop(i, pos(i, j));
newpop(i, pos(i, j)) = newpop(i, pos(i, j-1));
newpop(i, pos(i, j-1)) = temp;
end
end
end
end
城市数据
>>> city
city =
109.4177 24.3085
109.4443 24.3086
109.4394 24.3089
109.4226 24.3090
109.4471 24.3092
109.4277 24.3093
109.4347 24.3101
109.4168 24.3102
109.4470 24.3167
109.4175 24.3186
109.4469 24.3230
109.4197 24.3240
109.4467 24.3285
109.4218 24.3313
109.4465 24.3350
109.4205 24.3372
109.4462 24.3392
109.4209 24.3397
109.4413 24.3415
109.4356 24.3418
下面是我在bilibli发布的视频讲解链接:
Cukor丘克-遗传算法解决旅行商问题

