


内存泄漏导致频繁Full GC
1、问题发现
Prometheus报警user-center服务的Old GC过多,需要排查
2、问题分析
user-center服务生产环境部署4个结点,整个堆的大小设置为2g,新生代的大小设置为1g。这次的报警,4个结点都有报,查看其中一个结点发现该结点,从10点30分左右到11点20分左右,不到一个小时的时间里,竟然产生了5次Full GC,这个是极其不正常的。

3、使用GCViewer分析GC日志
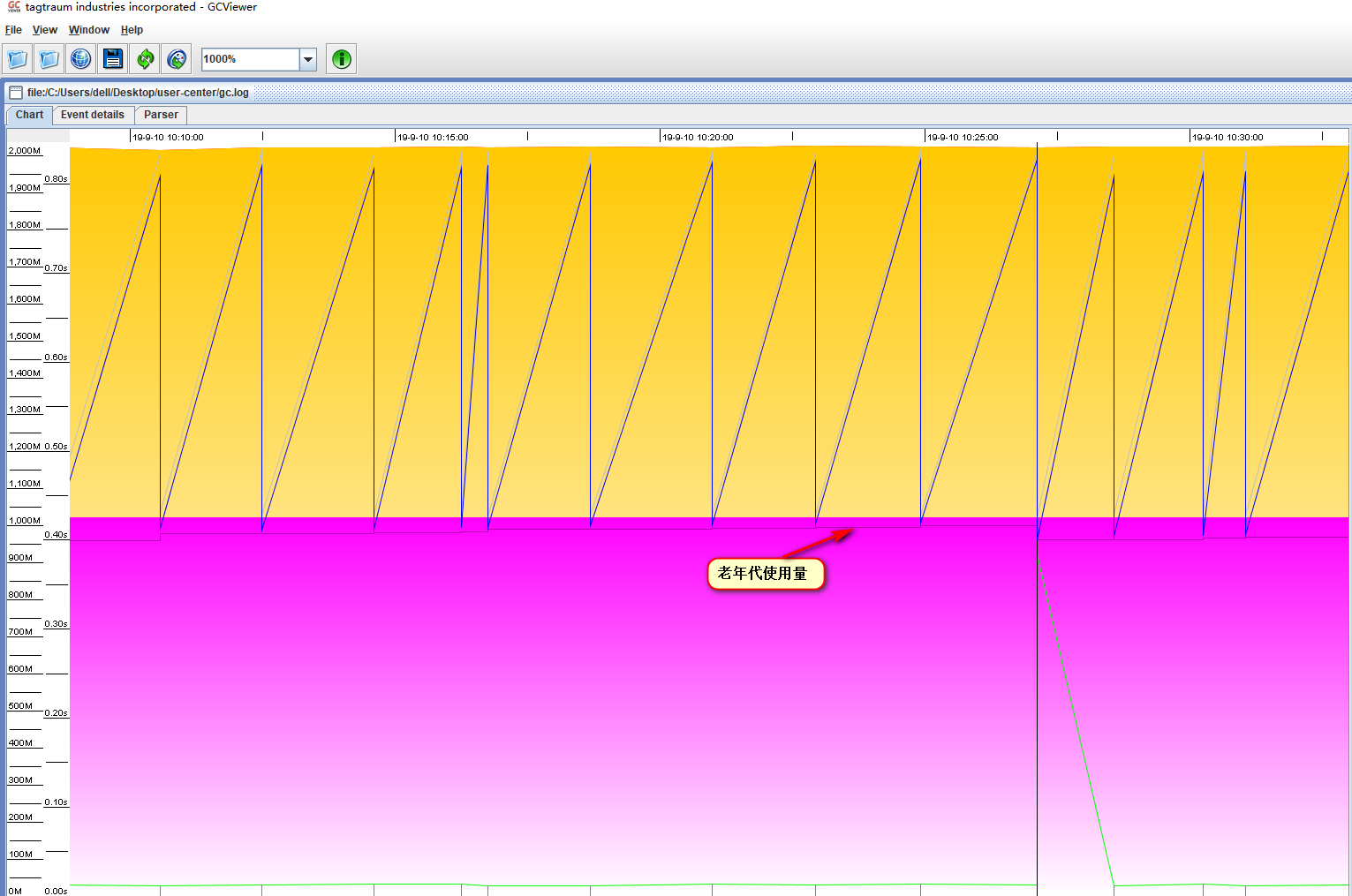
可以看出,整个老年代1g的内存,几乎已经全部被占用了,而且在Full GC之后,并没有回收多少内存,很显然,内存泄漏了。内存泄漏导致老年代内存空间不足,新生代的对象到了一定的年龄,需要提升,提升时发现老年代内存不够,就进行Full GC,但每次Full GC之后,并没用回收多少内存,虽然并没有导致OOM,但是很快下次提升就又需要Full GC了。
4、dump堆快照文件
使用命令jinfo -flag +HeapDumpBeforeFullGC 28679和jinfo -flag +HeapDumpAfterFullGC 28679,在Full GC之前和Full GC之后dump堆内存快照(注意:dump完成之后,一定要关闭这两个参数,不然频繁Full GC 导致频繁dump,会占用大量磁盘空间);使用命令jinfo -flag -HeapDumpBeforeFullGC 28679和jinfo -flag -HeapDumpAfterFullGC 28679关闭两个参数。其实也可以不用非要加上这两个参数然后等待Full GC的出现,由于是内存泄漏,老年代内存不能回收,那么直接使用命令jmap -dump:format=b,file=before.hprof 28679和
jmap -dump:live,format=b,file=after.hprof 28679来dump堆快照文件也是可以的,加上live表示只保存存活对象。
5、使用Eclipse MAT分析对快照
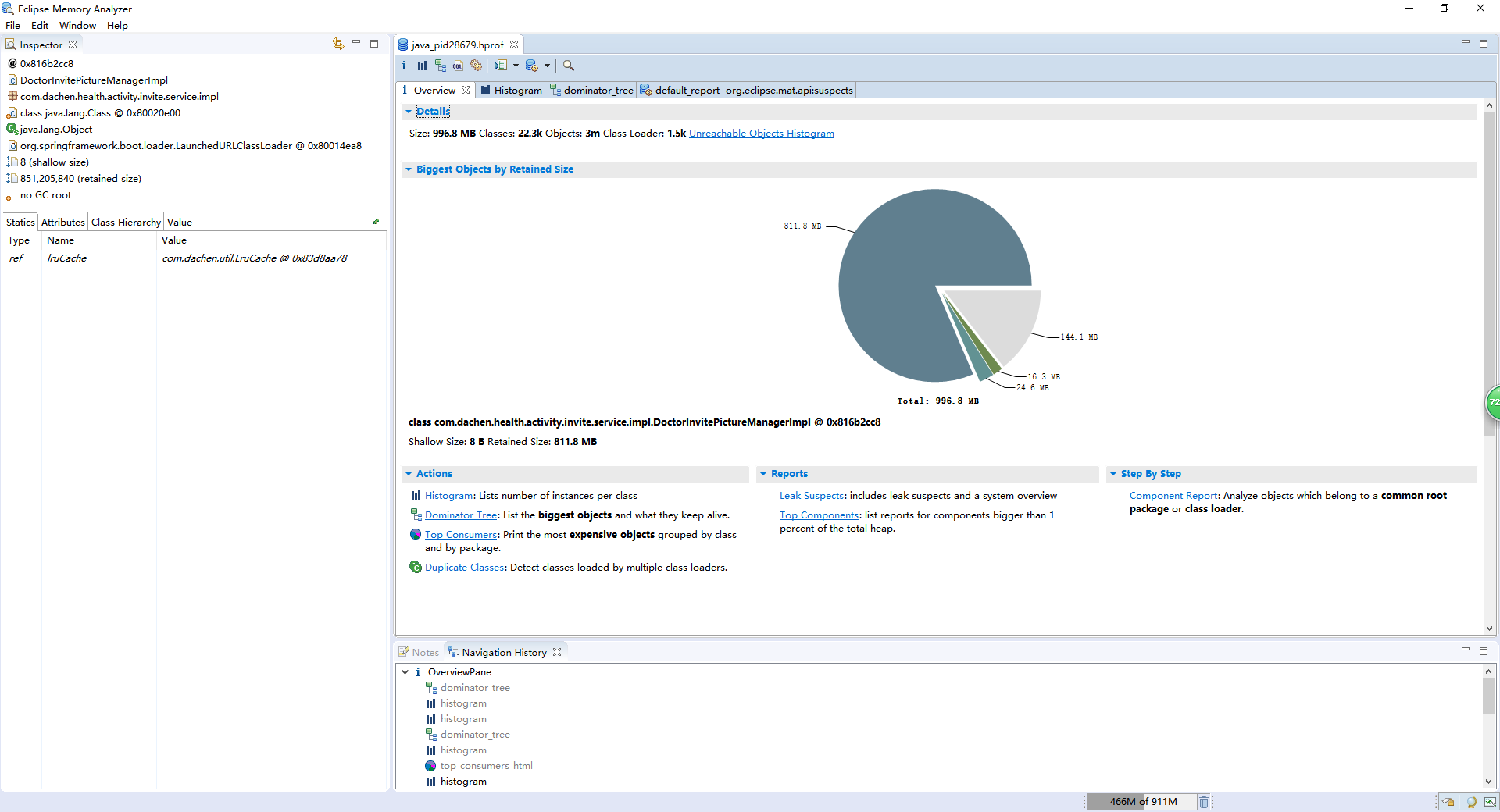
很显然可以看到堆内存被对象DoctorInvitePictureManagerImpl占用了811.8M,就是它导致了内存泄漏。剩下的就需要业务同学排查代码了。

