深入理解Ember-Data特性(下)
写在前面
最近比较忙,换了新工作还要学习很多全新的技术栈,并给自己找了很多借口来不去坚持写博客。常常具有讽刺意味的是,更多剩下的时间并没有利用而更多的是白白浪费,也许这就是青春吧,挥霍吧,这不是我想要的,既然这样,我还要继续写下去,坚持把博客做好,争取进前100博客,在此谨记。
2015年5月7日深夜,于电脑旁。
文章索引
二、使用Ember-Data
为了更好的使用Ember-Data,你就需要使用Store,Store你可以认为是一个内存缓存,Ember-Data使用它去恢复和保存数据模型。事实上,Store还负责从服务端获取数据,通过已绑定的Adapter。

还可以自定义Adapter:

或者自定义serializer:

这里仅仅是指出自定义场景,接下来会详细分析。
Model中获取数据
下面列举两种简单的获取数据方式:
- Store.find(‘mainMenu’); 这种方式是试图获取mainMenu类型的所有数据。
- Store.find(‘mainMenu’,’JSFlotJAgent’);这种方式是试图获取类型为mainMenu, id为“JSFlotJAgent”类型的数据。
更多例子请参考:http://emberjs.com/api/data/classes/DS.Store.html
标识模型关系
以上模型中的mainMenu以及Children类型同为mainMenu,形成一个“无限极”树的概念,循环嵌套节点对象,下图展示了模型中mainMenu和Chart的关系图:
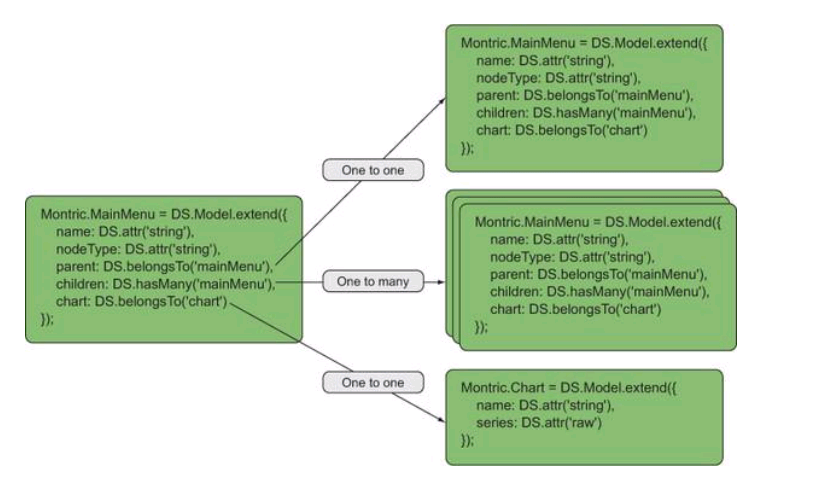
注:上图中的OneToOne、OneToMany等是有歧义,作者的这幅图应该改为OneToNone、ManyToNone。
这里mainMenu有一个parent节点标识上一层引用关系,一个children节点来表示孩子节点的集合,最后还有一个一对一的chart来表示图表数据。可以将chart理解为一个节点中的主要内容,parent和children则表示当前节点所在位置、关联关系,有些类似于两个指针分别指向父节点和孩子节点。

接下来一节我们详细分析Ember-Data中的模型关系。
三、Ember-Data模型关联关系
Ember-Data支持多种数据关系类型,这些关系类型用来期望从数据端返回的数据类型结构,接下来我们来详细分析这些API的作用。
理解Ember-Data关系模型
Ember-Data定义了5中关系模型,其中三种是真正的类型,另外两种可以理解为特殊例子。

注:图中第二行的OneToNone替换成OneToOne,作者这里可能是笔误。
其中,上一节我们讲过,Ember-Data中有很多约定,例如定义的属性要Camel风格(如modelA),列表数组属性结尾要用s(如modelAs),所有id要唯一性,这样便于读取从服务端传来的JSON Hash对象。
理解Ember-Data边缘(sideloaded)加载
边缘式加载的是通过增加数据层级来分步加载(可以理解为先加载第一层次的数据集合,然后按需加载子一级的数据集合)。
我们先来看下Model的定义:

这是一个典型的文章及评论的结构,即一个文章包含有多条评论,一条评论属于一篇文章。
下面来让我们看看边缘式加载是如何工作的:

当请求类型所有数据时,Ember-Data发现仓库中没有此类数据,则向服务器发起请求,而服务器仅仅返回文章内容及评论id(可以理解为仅仅返回评论的预览,而非一条评论的全部信息),然后当再次请求评论详情时,服务端返回评论的真实信息。
你可以在第一次请求数据时,让服务端返回所有数据:(而不是等待评论请求时再返回)
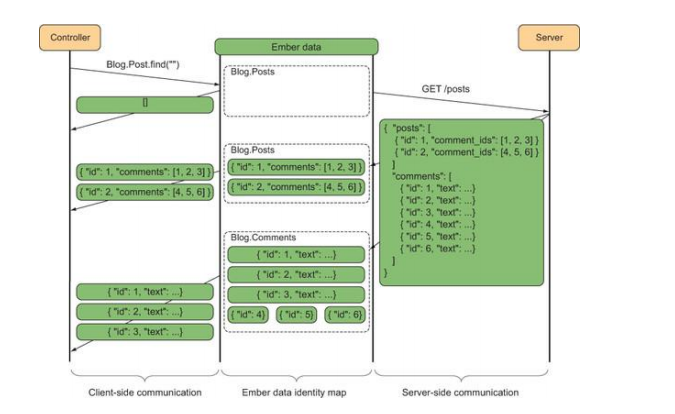
注:这样的场景下,如果用户没有查看评论,则评论永远也没有被显示出来,也就是说数据可能毫无意义的加载了。
当然这还要取决于你的数据场景,可能这样模式并不适合你,这样做会产生更多的HTTP请求,但同时又减小了“可用”数据的返回量,如何取舍还需仔细分析,当然你也可以自定义如何返回数据。
四、定制Adapter和Serializer
这里Ember提供了三种基本的重写Adapter的场景:
- 服务端API传来的数据对数据类型没有通用的标准。
- 服务端API传来的数据不同于你定义的数据类型。
- 重写Adapter并保留Serializer,来保证服务端传来的Json数据顶级结构中的类型与你定义的类型不同,而子类型相同。
定制Adapter
下面来让我们看下这种场景:
在我们上一节的数据类型中,mainMenu包含一个一对一的Chart类型,现在的需求是希望可以设置Chart的Timespan来部分获取Chart数据,如果没有设置则默认为10minutes。
首先,从DS.RESTAdapter中扩展一个类型,并且要遵循Adapter的命名规范(XXXXAdapter这种模式必须遵循)。
然后,可以重写如下的方法:
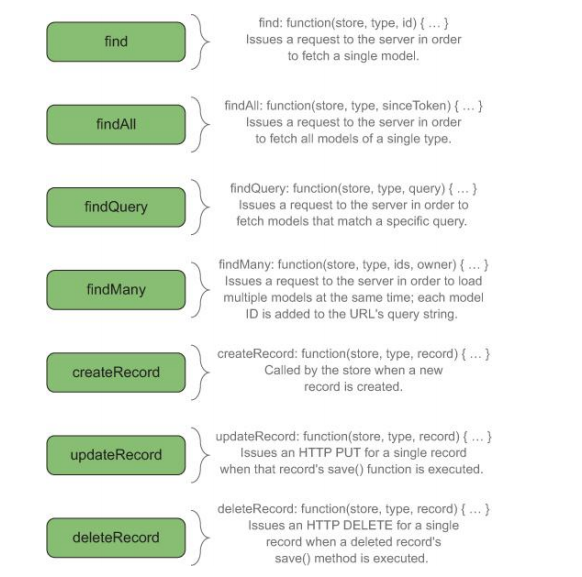
对于我们目前的需求来说,我们仅仅需要重写find()方法即可,方法中将进行一个HTTP请求。

其中,重要的是用Timespan重组http请求,已达到我们的目的。
更多请参考:http://guides.emberjs.com/v1.11.0/models/customizing-adapters/
定制Serializer
相对于RESTSerializer而言,我们给出如下的非标准数据模型:

在这个返回类型中,user_name、account_name、user_role是非标准的数据相对RESTSerializer来说。而且最顶层的属性名称user_model也不符合。
我们可以重写Adapter中的方法以达到我们的目的:

这里我们需要重写normalize方法为了解决user_name、account_name、user_role非标准化问题,重写typeForRoot方法解决user_model问题。

定制URL
你可以定制Adapter的ULR访问类型以及转换定义,下面是一个很好的例子: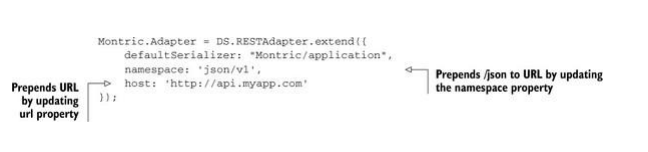
最终将访问如下网址:http://api.myapp.com/json/v1/mainMenus
FAQ
- 使用Store存储数据的优势是否能结合Filter?
Store能自动cache数据并保持数据同一性,通过id属性。并且允许用户使用Filter来过滤不需要的数据。
- Ember-Data如何通知新数据已经到达?
当你使用store.find()时,数据会自动更新RecordArray,任何计算属性或者监听在RecordArray上都将获得通知。如果你不需要请求并且要加载数据的话,可以使用Store.push或者pushPayload 来向Store中推送数据,这样Store也会获得监听事件的触发。例如SSE或WebSocket场景。
引用
Ember-Data更新日志:https://github.com/emberjs/data/blob/master/TRANSITION.md
参考书目:《Ember.js In Action》
作者:Stephen Cui
出处:http://www.cnblogs.com/cuiyansong
版权声明:文章属于本人及博客园共有,凡是没有标注[转载]的,请在文章末尾加入我的博客地址。
如果您觉得文章写的还不错,请点击“推荐一下”,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号