python sweetviz_数据分析及解决报告图表中文乱码
python sweetviz_数据分析
python 做数据分析,传入数据进去,就可以使用python现有的插件,进行数据分析,生成数据分析的报表,可以将复杂的数据,通过图表的形式,清晰将数据展示出来
其实,就是将负责的数据,通过图表的形式,统计各个数据的情况
python 做数据分析的探索
第一种:探索数据分析由几个部分组成,再通过画图表的方法,进行数据分析
参考:http://www.py.cn/jishu/jichu/13184.html
第二种:现有已提供Sweetviz,只需要几行代码,即可进行数据分析,综合考虑,先使用这种进行数据分析
参考:https://www.jb51.net/article/226963.htm
使用Sweetviz数据分析的实际操作
首先将Sweetviz安装,自动安装
Pip install sweetviz 或直接通过pycharm工具进行搜索下载
安装好之后,操作文章里面,进行数据分析,希望得到的效果,生成数据分析的html报告
Sweetviz基本用法
- 数据准备:使用pandas读取数据之前,要将数据存放到csv格式的文件里面
- 数据读取:pandas进行读取数据,这里需要根据csv文件,配置文件的编码格式,否则报告中包含中文的也是乱码
- 使用sweetviz.analyze(),将读取回来的dataframe的数据,进行分析
- 分析完成后,分析结果以html的格式进行展示
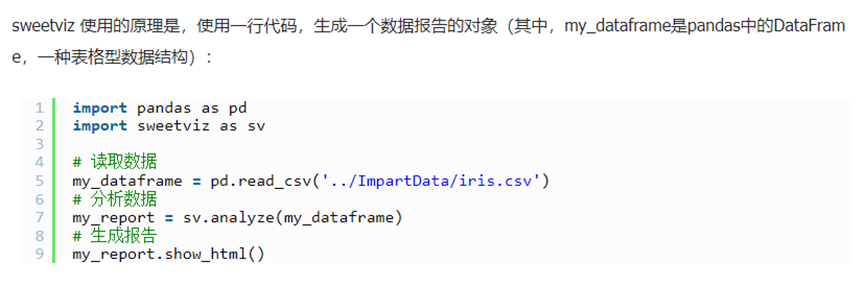
实操代码
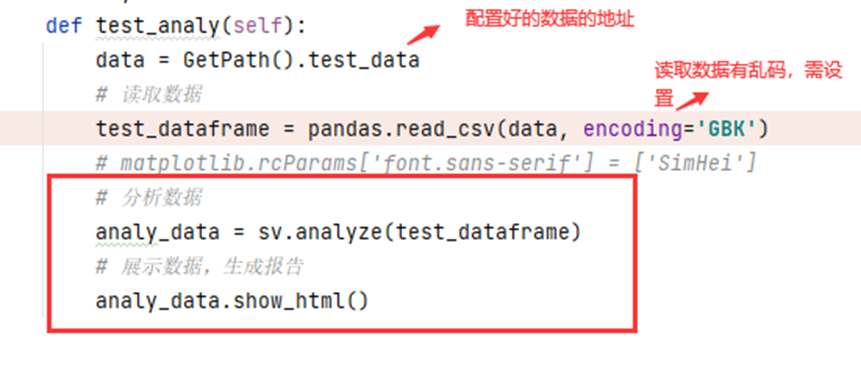
def test_analy(self):
data = GetPath().test_data
# 读取数据
test_dataframe = pandas.read_csv(data, encoding='GBK')
# 分析数据
analy_data = sv.analyze(test_dataframe)
# 展示数据,生成报告
analy_data.show_html()
解决图表中的中文乱码
来到第4步都很顺利执行完成,打开报告查看的时候,发现报告里面的图表有中文的,展示成框框
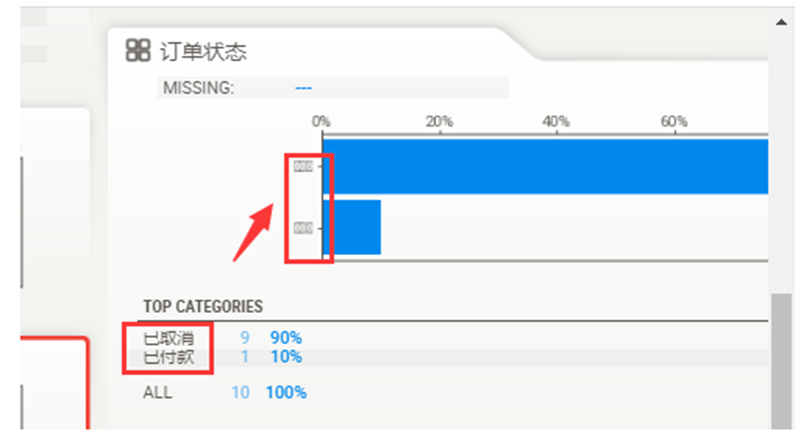
分析报错
Glyph绘制图表时,可在控制台看到报错,UserWarning: Glyph xxxxx missing from current font,字面意思就是确实了常用的字符

实际报错中的36890,对应的是unicode中的中文字符,当前的配置中,找不到对应的字体文件对应,所以这个中文缺失,前端展示成框框


参考:https://blog.csdn.net/weixin_43257735/article/details/120170615
下载字体
只是当前的字体没有对应中文的字体文件,不是解析中文,就去下载可以显示中文的字体,进行配置
下载黑体的字体,包含中文,
字体地址:http://www.font5.com.cn/font_download.php?id=151&part=1237887120
下载成功后,将SimHei.ttf,放到对应的文件夹目录下
有点提个醒,使用的是sweetviz进行数据分析,而不是直接使用matplotlib
中的graph进行画图,将下载的字体,放置到matplotlib的font/下,是起不了作用的
直接从报错的信息中,发现sweetviz里面也有graph文件来生成图表,要到这个路径下,将字体放置到font里面,
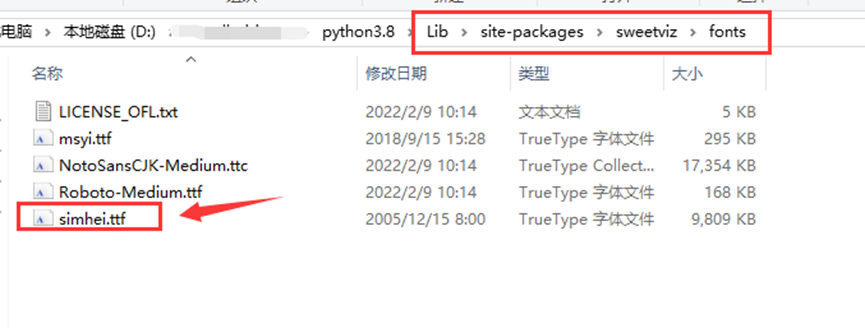
配置使用字体
再到配置文件graph_base.mplstyle,设置graph使用的字体
…\python3.8\Lib\site-packages\sweetviz\mpl_styles\graph_base.mplstyle
找到配置文件里面的font的配置,将配置改成使用黑体

查看效果
这个时候,重新运行程序,进行数据分析,控制台没有输出缺失字体,报告收集成功,生成到当前文件下

报告中生成的图表的中文,正常显示,问题解决

Sweetviz三种常用的方法
其中,分析数据有三种函数可以用,除了上面提到的analyze函数,还有 compare 和 compare_intra 函数。
首先是analyze函数:
analyze(source: Union[pd.DataFrame, Tuple[pd.DataFrame, str]],
target_feat: str = None,
feat_cfg: FeatureConfig = None,
pairwise_analysis: str = 'auto')
source: 以pandas中的DataFrame数据结构作为分析对象。可见其有以下4个参数可以配置:
target_feat: 需要被标记为目标对象的字符串。
feat_cfg: 需要被跳过、或是需要被强制转换为某种数据类型的特征。
pairwise_analysis: 相关性分析可能需要花费较长时间。如果超过了你的忍受范围,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
compare()丨两个数据集比较
my_report = sv.compare([my_dataframe, "Training Data"], [test_df, "Test Data"], "Survived”)
要比较两个数据集,只需使用该 compare() 函数。它的参数与 analyze() 相同,只是插入了第二个参数来覆盖比较数据帧。建议使用 [dataframe, “name”] 参数格式以更好地区分基础数据帧和比较数据帧。(例如 [my_df, "Train"] 比 my_df 更好)
Sweetviz比较数据
用于比较两个数据集,比如一样的数据,不同的用户或不同的平台,进行数据比较,可以得出数据分析的结果
使用到的compare()方法
Compare基本用法
1、 数据准备:两组比较的数据的文件,csv格式
2、 其他参数配置,按需进行配置
3、 使用compare(),进行比较
4、 最后将分析的结果,通过html展示
参数配置:
1、 source: 以pandas中的DataFrame数据结构作为分析对象。
2、 target_feat: 需要被标记为目标对象的字符串。
3、 feat_cfg: 需要被跳过、或是需要被强制转换为某种数据类型的特征。
4、 pairwise_analysis: 相关性分析可能需要花费较长时间。如果超过了你的忍受范围,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
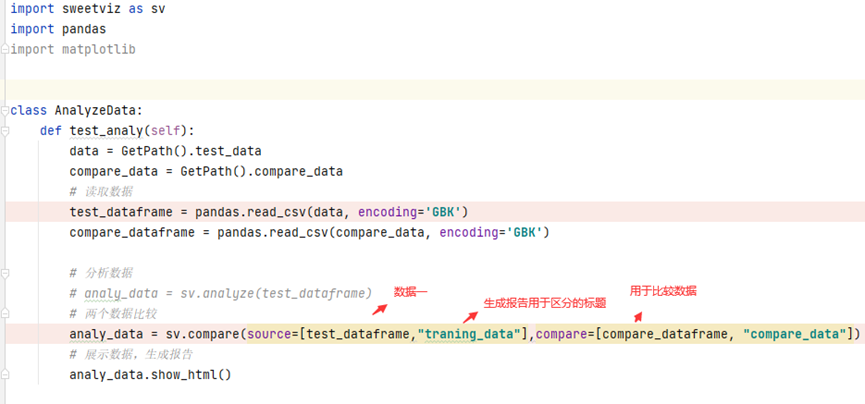
def test_analy(self):
data = GetPath().test_data
compare_data = GetPath().compare_data
# 读取数据
test_dataframe = pandas.read_csv(data, encoding='GBK')
compare_dataframe = pandas.read_csv(compare_data, encoding='GBK')
# 两个数据比较
analy_data = sv.compare(source=[test_dataframe,"traning_data"],compare=[compare_dataframe, "compare_data"])
# 展示数据,生成报告
analy_data.show_html()
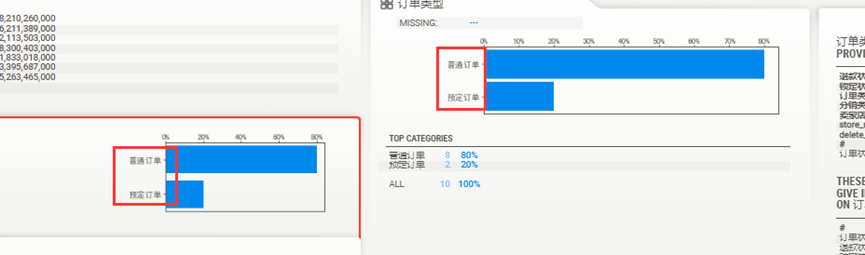
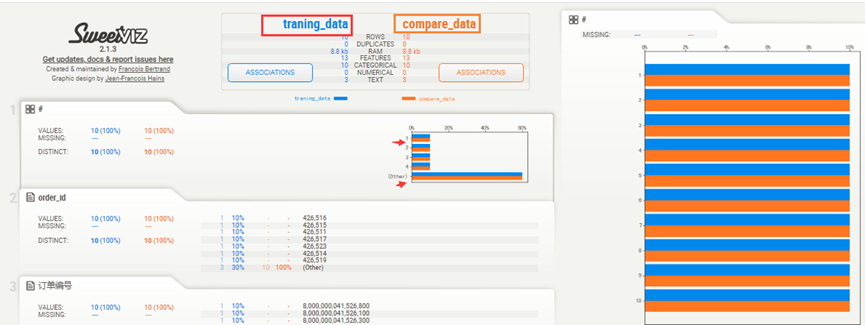
比较完成后的报告
看生成的报告中的分别用不同的颜色,标注两组不同的数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号