Python+flask+flask-apscheduer实现定时下发任务
Python+flask+flask-apscheduer实现定时下发任务
背景:
使用python+flask+mamaca实现的自动化用例管理平台,可以下发任务到具体的节点,进行执行测试用例,没有定时执行的功能,使用flask-apscheduler加上定时下发任务
一、Flask-apscheduler的基本内容介绍和基本操作
安装:
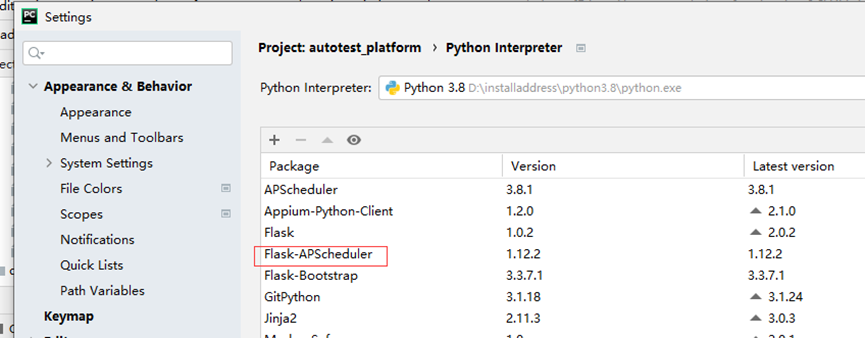
Pip install flask-APScheduler 或者pycharm如下截图,点击【+】输入名称查找,install package
二、简单的定时任务的例子
网上找了一个简单的例子,先来试试定时任务能不能根据配置启动起来
采用配置文件的方式,进行加载flask项目
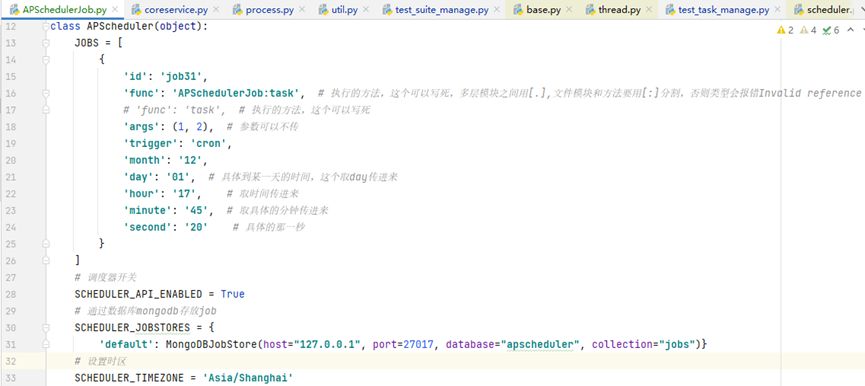
定义一个config类,里面配置jobs的基本信息,
例子:定时器为cron,在指定的12月,1号,17小时,45分,20s,执行方法task
from flask_apscheduler import APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.triggers.cron import CronTrigger
import datetime
from apscheduler.jobstores.mongodb import MongoDBJobStore
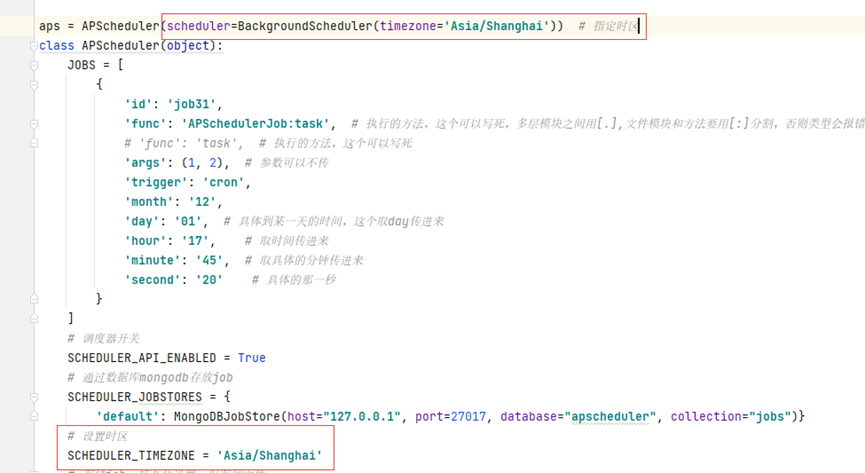
aps = APScheduler(scheduler=BackgroundScheduler(timezone='Asia/Shanghai')) # 指定时区
class APScheduler(object):
JOBS = [
{
'id': 'job31',
'func': 'APSchedulerJob:task', # 执行的方法,这个可以写死,多层模块之间用[.],文件模块和方法要用[:]分割,否则类型会报错Invalid reference
# 'func': 'task', # 执行的方法,这个可以写死
'args': (1, 2), # 参数可以不传
'trigger': 'cron',
'month': '12',
'day': '01', # 具体到某一天的时间,这个取day传进来
'hour': '17', # 取时间传进来
'minute': '45', # 取具体的分钟传进来
'second': '20' # 具体的那一秒
}
]
# 调度器开关
SCHEDULER_API_ENABLED = True
# 通过数据库mongodb存放job
SCHEDULER_JOBSTORES = {
'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="apscheduler", collection="jobs")}
# 设置时区
SCHEDULER_TIMEZONE = 'Asia/Shanghai'
配置信息配置完成后,即可开始获取配置信息,和添加定时任务
在app.config.from_object(APScheduler()) 获取配置信息后,获取到jobs的信息,会调起添加定时任务,检查scheduler的状态为开启,即可添加定时任务,代码执行到aps.start()时,代表scheduler开启,正在等待接收定时任务,并在指定的时间执行
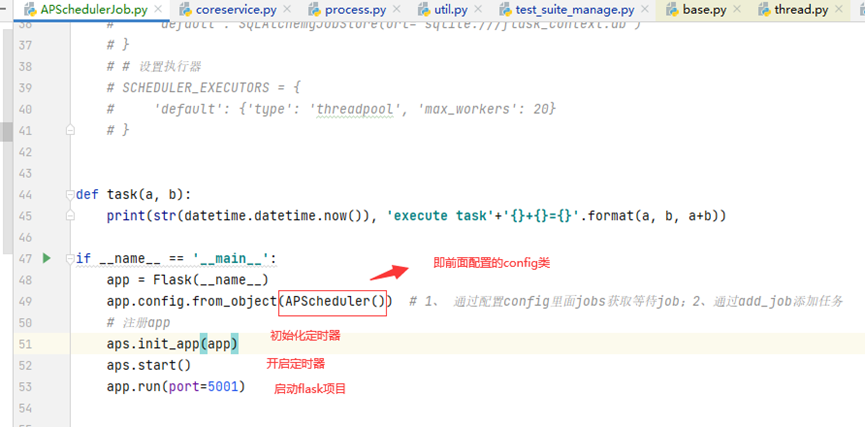
另外一个添加定时任务的方法,直接通过aps.add_job(添加对应的一些配置信息)
根据()括号内给定的参数,进行执行定时任务

时区问题,启动的时候加载local报错,类似timezone的错,可能是时区的问题,设置一下时区
三、定时基本组成部分的介绍
基本的例子看完之后,可以从例子里面看到三个基本部分,第一个是使用的调度器scheduler、trigger、作业存储job store,还有一个执行器,例子没有加入,程序使用默认的执行器,下面可以继续看看这些组成部分的详细内容
APScheduler有四种组成部分
调度器(scheduler)是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。Apscheduler提供的调度器有7种:
BlockingScheduler和BackgroundScheduler。
BlockingScheduler : 调度器在当前进程的主线程中运行,也就是会阻塞当前线程。
BackgroundScheduler : 调度器在后台线程中运行,不会阻塞当前线程。
AsyncIOScheduler : 结合 asyncio 模块(一个异步框架)一起使用。
GeventScheduler : 程序中使用 gevent(高性能的Python并发框架)作为IO模型,和 GeventExecutor 配合使用。
TornadoScheduler : 程序中使用 Tornado(一个web框架)的IO模型,用 ioloop.add_timeout 完成定时唤醒。
TwistedScheduler : 配合 TwistedExecutor,用 reactor.callLater 完成定时唤醒。
QtScheduler : 你的应用是一个 Qt 应用,需使用QTimer完成定时唤醒。
触发器(trigger)包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
Date:是最基本的一种调度,任务只会在指定日期时间执行一次
interval触发器:根据设置的时间间隔,每间隔执行一次
crontab触发器:在特定时间周期性地触发,如每天,周循环等场景
作业存储(job store)存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。如果任务不考虑持久执行,可以不加入任务存储器,如果考虑到任务可能需要重跑等,则可以加上任务存储器,这个配置mongodb,配置对应的数据的地址,端口,数据库以及具体的collections
SCHEDULER_JOBSTORES = {
'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="apscheduler", collection="jobs")}
执行器(executor)处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
ThreadPoolExecutor: 线程池执行器。
ProcessPoolExecutor: 进程池执行器。
GeventExecutor: Gevent程序执行器。
TornadoExecutor: Tornado程序执行器。
TwistedExecutor: Twisted程序执行器。
AsyncIOExecutor: asyncio程序执行器。
触发器(作业运行的控制)的例子
date触发器:是最基本的一种调度,任务只会在指定日期时间执行一次。
参数说明:
run_date:任务的运行日期或时间 (datetime 或
str)
timezone:指定时区(datetime.tzinfo 或
str)
# 在2020年5月22日执行一次 scheduler.add_job(func=func, trigger="date", run_date=date(2020, 5, 22), timezone="Asia/Shanghai") # 在2020年8月13日 14:00:01执行一次 scheduler.add_job(func=func, trigger="date", run_date='2020-08-13 14:00:01')
2.interval触发器:根据设置的时间间隔,每间隔执行一次。间隔开始计算时间,为任务创建时间
参数说明
weeks:间隔几周。int
days:间隔天数。int。
hours:间隔小时数。int。
minutes:间隔分钟数。int。
seconds:间隔秒数。int。
start_date:间隔触发的起始时间。(datetime 或 str)
end_date:间隔触发的结束时间。(datetime 或
str)
timezone:指定时区。(datetime 或 str)
# 每5秒执行一次func()函数 scheduler.add_job(func=func, trigger="interval", seconds=5) # 在8月13~20日之间,每天执行一次 scheduler.add_job(func=func, trigger="interval", days=1,start_date='2020-08-13 14:00:01', end_date='2020-08-20 14:00:01')
3. crontab触发器:在特定时间周期性地触发,如每天,周循环等场景,它是功能最强大的触发器。
参数范围只适用于int类型,str类型有无限可能,自己踩坑去吧
year: 年,4位数字。int 或 str
month: 月 (范围1-12)。int 或 str
day: 日 (范围1-31)。int 或 str
week:周 (范围1-53)。int 或 str
day_of_week: 周内第几天或者星期几 (范围0-6,0是周一,6是周天 或者
mon,tue,wed,thu,fri,sat,sun)。int 或 str
hour: 时 (范围0-23)。(int 或 str)
minute: 分 (范围0-59)。(int 或 str)
second: 秒 (范围0-59)。(int 或 str)
start_date: 最早开始日期(包含)。(datetime 或 str)
end_date: 最晚结束时间(包含)。(datetime 或 str)
timezone: 指定时区。(datetime 或 str)
# 每天23点定时执行 scheduler.add_job(func=func, trigger="cron", day_of_week="0-6", hour=23 ) # 在每年 1、2、3、7、8、9 月份中的每月第4天和星期日中的 00:00, 01:00, 02:00 和 03:00 执行 func 任务 scheduler.add_job(func=func,trigger="cron",month="1-3,7-9",day="4th sun", hour="0-3") # 每周一早晨9点30分执行func任务 scheduler.add_job(func=func, trigger="cron", day_of_week=0, hour=9, minute=30) # 间隔5分钟执行一次,与interval触发器使用功能相同 scheduler.add_job(func=func, trigger="cron", minute="*/5" )
原文链接:https://www.jianshu.com/p/4c5bc85fc3fd
原文链接:https://blog.csdn.net/weixin_39241397/article/details/82746096
四、定时任务配置参数config
l id:可以随便起;
l func:要执行的方法,这个可以写死,多层模块之间用【.】,文件模块和方法要用【:】分割,【:】前配置的模块不对的,后面添加jobs的时候,会无法导入module,这个时候要检查模块的导入地址,【:】后的为具体指定的方法,这个方法要在前面导入模块的基础上可以找的到,否则类型会报错Invalid reference,即没办法在当前模块下,找到这个方法

l args:参数,若func方法需要参数,可使用args传入
l trigger:触发器,date cron interval
l month、day、hour、minute、second:配置定时器执行的时间
l SCHEDULER_API_ENABLED:调度器开关,默认开启
l SCHEDULER_JOBSTORES:jobs任务存储器配置

l SCHEDULER_TIMEZONE:设置时区
l SCHEDULER_EXECUTORS:设置执行器,包括执行器类型、是否允许最大多少个同时
l SCHEDULER_JOB_DEFAULTS: 设置容错时间为 2min,coalesce积攒得任务跑几次,在时间允许得范围内 True:默认最后一次,False:在时间允许范围内全部提,max_instances 同时允许并发的最大并发量,misfire_grace_time 如果重启任务在这个时间范围内,就能继续重启

五、定时任务的执行顺序
5.1添加任务
1、调起add_job方法
进而调到scheduler.py里面的_scheduler.add_job(**job_def)

2、调到schedulers\base.py
文件里面的add_jobs

进到add_job方法后,开始创建触发器、分别读取传入参数
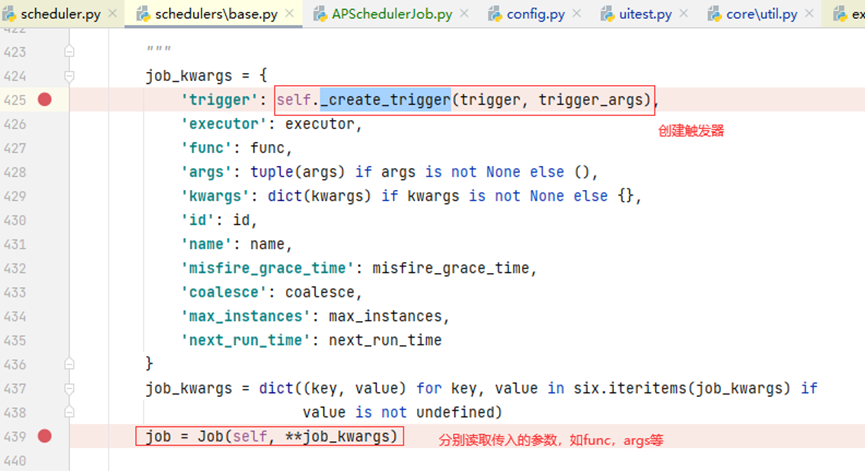
3、Job(self,**job_kwargs)初始化job
进到job.py里面的初始化任务,调起_modify()方法,对传入的参数进行检验
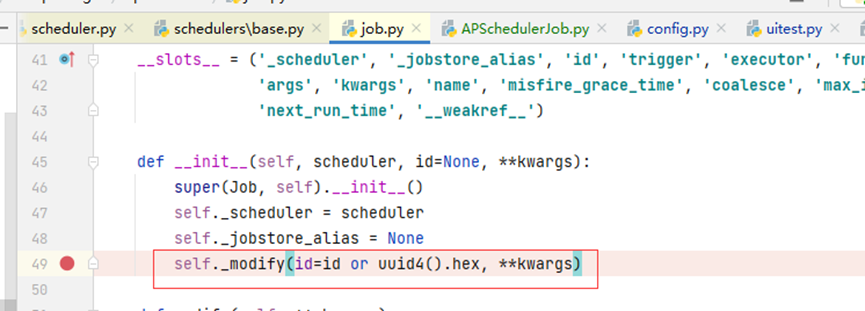
4、参数校验
具体的_modify()方法
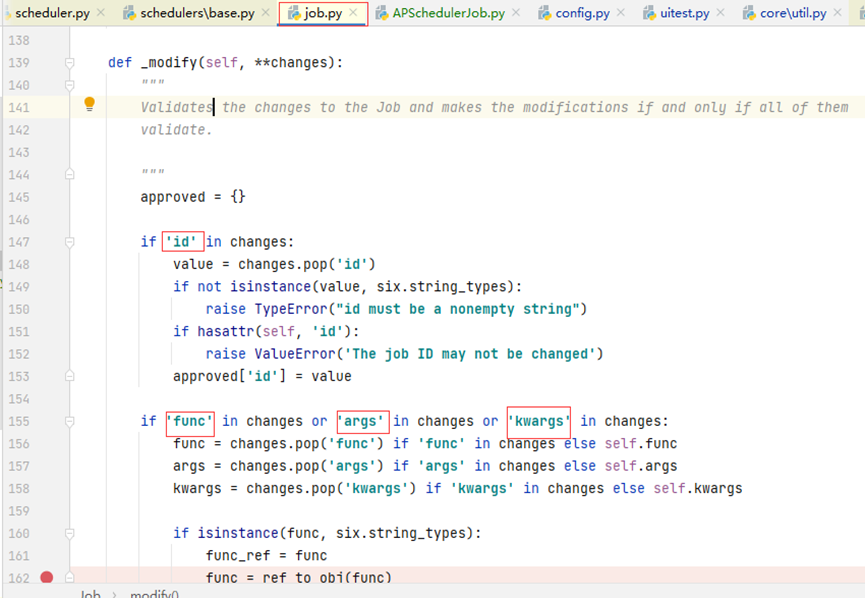
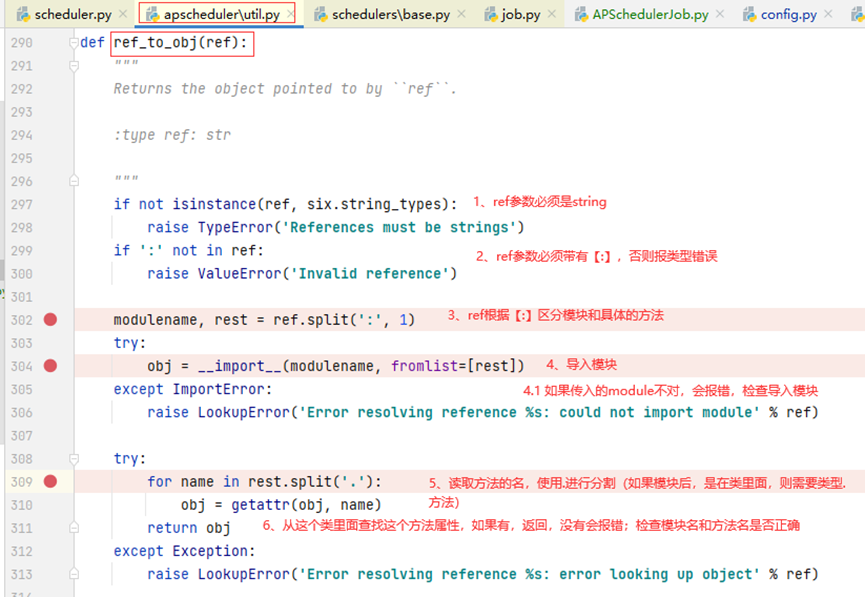
先看传入的func方法的参数,根据参数的类型,走不同的分支,方法进到的ref_to_obj,将func的文件名和具体的方法转化为对象
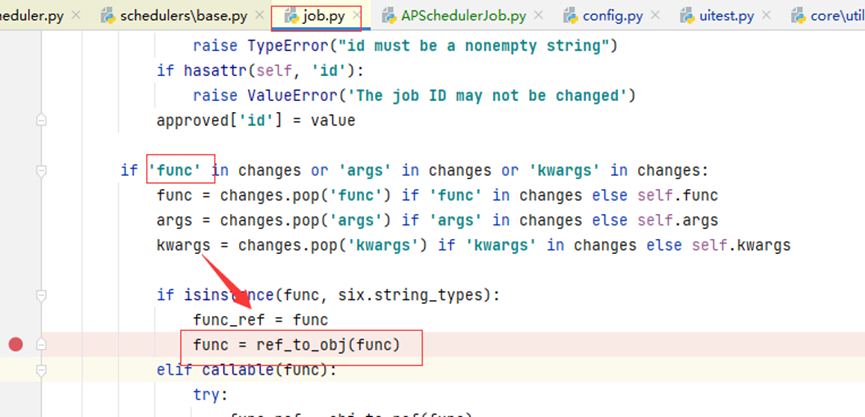
Ref_to_obj:方法用于对传进来的func参数,进行分割,分割出对应的模块名和具体的方法,来导入模块和检查方法是否存在
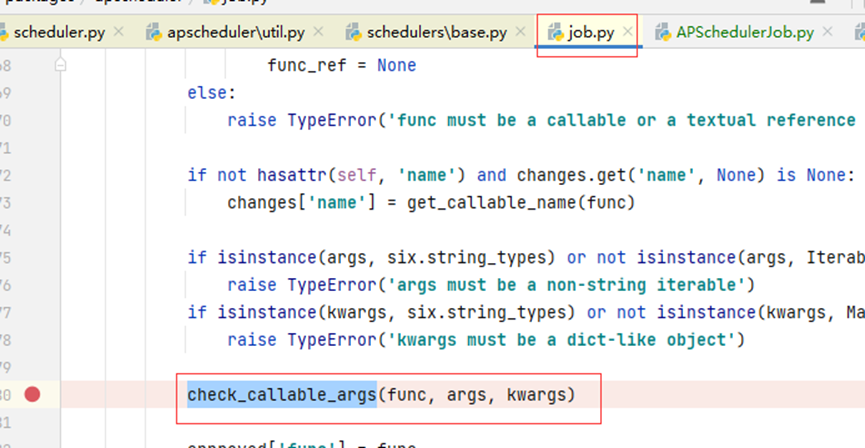
和func相关联的参数是args用来给func传递方法的参数,args一样有程序的检查规则,比如传进来的参数个数和给定的func方法定义的参数一致,如果不一样会报错
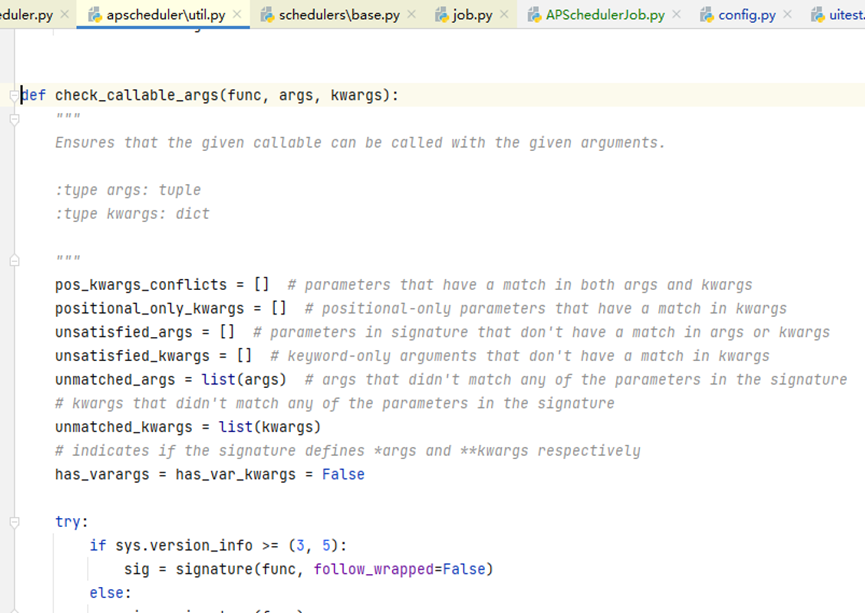
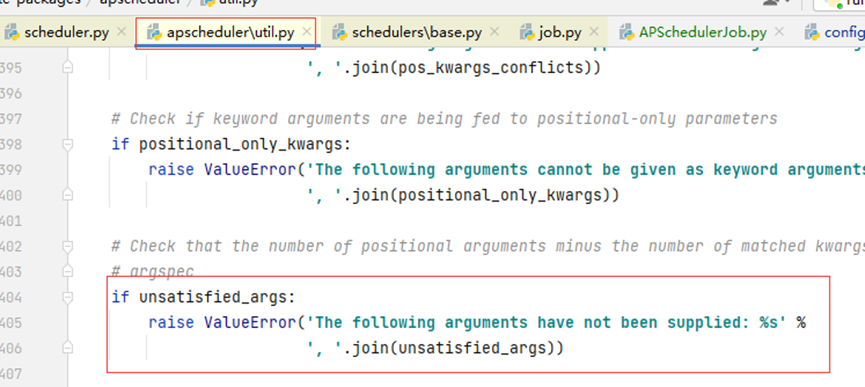
如果传入的参数个数不对,会报相应的错误,这个要检查参数,对应类里面的定义的方法,一般第一个参数是带有self的,这个也要作为参数,传入到args里面
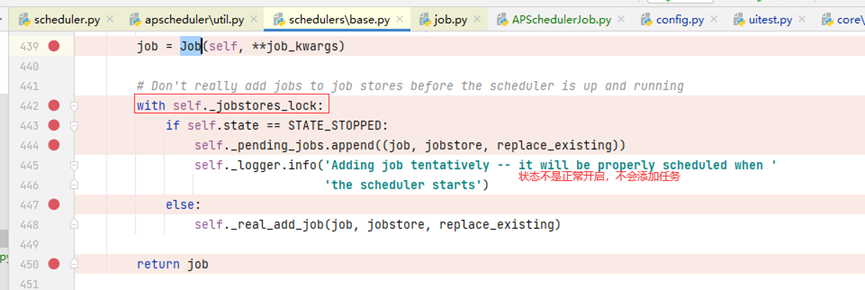
5、判断调度器的状态是否正常
一般启动flask项目的时候,会加上aps.start(),启动调度器,调度器正确,状态为正常,添加定时任务成功
5.2 执行任务
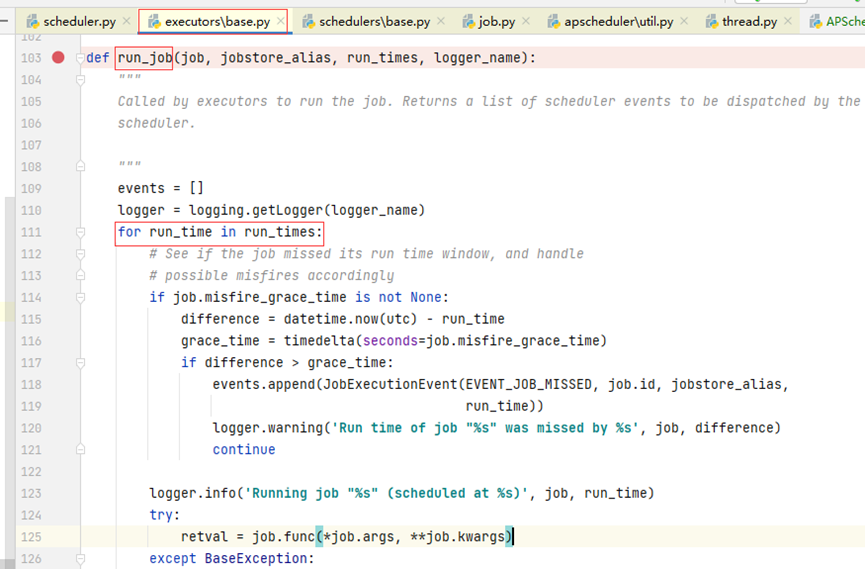
前面添加了定时任务,Scheduler在指定时间内,执行任务
六、定时任务结合项目的实际操作
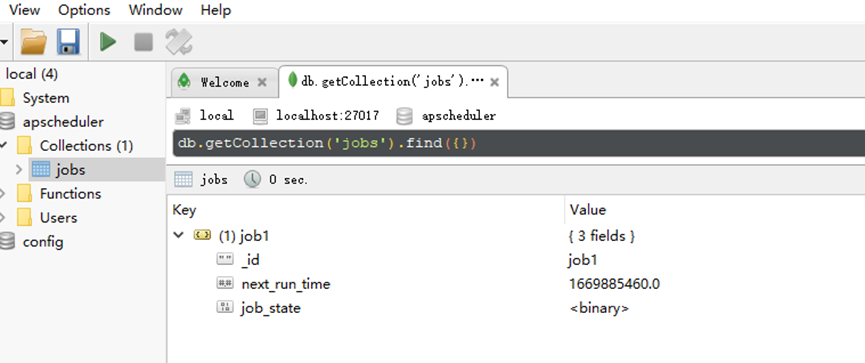
1、Jobs任务存储,Mongodb存储
有多种方式,可存放到mongo
1、 安装mongodb服务
2、 安装可视化工具,查看mongodb数据库
3、 创建定时任务jobstore时,设置为mongodb,配置mongodb的配置文件
Robo 3t连接本地的数据库报错

原因:本机没有安装mongodb的服务,没安装之前,没有MongoDB Server的服务,安装成功之后,有MongoDB Server的服务

参考:https://www.cnblogs.com/simple-li/p/11334484.html
服务安装成功后,再次使用robo 3t连接,即可连接成功

Flask配置信息里面配置Mongodb信息,配置具体的host,具体的数据库、collections
2、定时任务的配置信息
定时任务的配置信息,和当前的flask项目的配置信息放到同一个config文件
BOOTSTRAP_SERVE_LOCAL = True
from flask_apscheduler import APScheduler as _BaseAPScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.executors.pool import ThreadPoolExecutor
# # 重写实现上下文机制
class APScheduler(_BaseAPScheduler):
def run_job(self, id, jobstore=None):
with self.app.app_context():
super().run_job(id=id, jobstore=jobstore)
# 定时器配置
# 持久化配置,数据持久化到mongodb
SCHEDULER_JOBSTORES = {'default': MongoDBJobStore(host="127.0.0.1", port=27017, database="apscheduler", collection="jobs")}
# 线程池配置,最大6个线程
SCHEDULER_EXECUTORS = {'default': ThreadPoolExecutor(6)}
# 调度器开关开启
SCHEDULER_API_ENABLED = True
# 设置容错时间为 2min
# coalesce积攒得任务跑几次,在时间允许得范围内 True:默认最后一次,False:在时间允许范围内全部提交
# max_instances 同时允许并发的最大并发量
# misfire_grace_time 如果重启任务在这个时间范围内,就能继续重启
SCHEDULER_JOB_DEFAULTS = {'coalesce': False, 'max_instances': 3, 'misfire_grace_time': 60}
# 配置时区
SCHEDULER_TIMEZONE = 'Asia/Shanghai'
有的项目可能存在多个config,这个时候,要看flask项目启动的时候,读取是哪一个config文件,建议在app.run()断点debug,大概就知道使用的是哪一个config配置文件,如果配置错config文件,可能会出现flask项目启动不了的情况,逐个debug找到问题,然后再解决
3、配置到flask项目
前端点击定时执行,设置定时执行的时间

静态页面逐个配置,调到view里面的方法,进行add_jobs方法
aps = APScheduler(scheduler=BackgroundScheduler(timezone='Asia/Shanghai'))
# test_suite_manage.test_suite_manage().new_test_run_list(id)
# fun:前面的模块要用[.],后面的具体的方法名用[:],这个方法应该是更新测试用例集的状态,然后main方法会去检查
# fun:需要传入参数,要用args,不能直接在fun里面传
# aps.add_job(id='run_job', func='app.core.coreservice:coreservice', trigger='cron', month=month,
# day=day, hour=hour, minute=time, second='00')
aps.add_job(id='run_job', func='app.db.test_suite_manage:test_suite_manage.new_test_run_list',args=('self',str(id)), trigger='cron', month=month,
day=day, hour=hour, minute=time, second='00')
aps.start()
如果有配置job持久化存储,这个时候就可以到对应文件或数据库,查看有没有一个叫run_job的定时任务,如果有,定时任务就创建成功了,等待执行即可,如果没有,则需要add_job debug逐层查看是不是在哪一步出现了错误,可参考上面的添加任务的步骤
和项目结合,看着虽然只有三个步骤,在参考资料较少的情况下,用了不少的时间啊。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号