C++ 原子操作
先打破一个认知
在学习编程语言的时候,通常都会讲到代码的几种执行方式:顺序、选择、分支;其中顺序执行的代码会按照编写顺序一行一行的执行。
然鹅,由于各种原因,代码的执行顺序并不一定是“顺序”的,而是可能会被优化为其他顺序。
在同一个线程里,如果两条语句没有依赖关系,那么其执行顺序不可预测;但是有依赖关系的代码是串行执行的。
为什么会有这样的情况? 有如下几类原因:
(1)编译器优化
编译器会假设程序是单线程执行
1 // 源代码 2 x = 1; 3 y = 2; 4 x = 3;
上面代码可以看出来,x没有被依赖,所以经过编译器优化的代码可能如下
1 // 经过编译器优化的代码 2 y = 2; 3 x = 3;
(2)处理器优化
现代处理器是按照流水线的方式工作的,CPU会允许指令乱序执行,以免因指令等待资源而导致CPU处于闲置状态。
(3)存储系统
现代处理器的架构大致如下
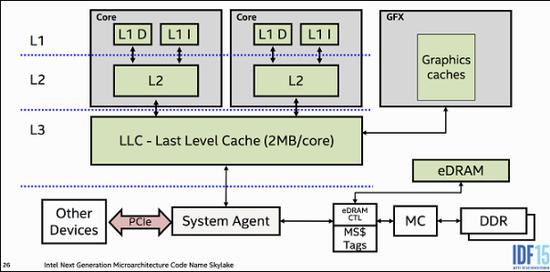
三级缓存(L1、L2、L3)是什么?
以近代CPU的视角来说,三级缓存(包括L1一级缓存、L2二级缓存、L3三级缓存)都是集成在CPU内的缓存,它们的作用都是作为CPU与主内存之间的高速数据缓冲区,L1最靠近CPU核心;L2其次;L3再次。运行速度方面:L1最快、L2次快、L3最慢;容量大小方面:L1最小、L2较大、L3最大。CPU会先在最快的L1中寻找需要的数据,找不到再去找次快的L2,还找不到再去找L3,L3都没有那就只能去内存找了。
(4)On-Chip Network(片上网络)
略
如何应对?
(1)乱序执行不可避免
(2)线程私有变量不受影响,共享变量会受影响
(3)解决方法:原子变量或者加锁
C++11承诺:如果程序没有竞争(race),那么程序运行起来就好像顺序一致性(SC for Data-Race-Free programs, SC-DRF);
什么是竞争?即多现场访问同一个变量时至少有一个现场有写操作。
看下如下两种情况是否存在竞争?
1 // thread1 2 foo() 3 { 4 return s.c; 5 } 6 7 // thread2 8 foo() 9 { 10 return s.d; 11 } 12 13 // case1 14 struct s{char c; char d;}; 15 // case2 16 struct s{int c:9; int d:7;} 17 18 // 两个线程一个访问s.c,另一个访问s.d,其中在两种s定义的情况下是否存在竞争?
答案是case1不存在竞争,case2存在竞争,因为对计算机来说一个最小单位仍然是字节,而为多少多少bit,所以case2里的结构体s的两个成员在访问时会存在竞争。
acquire / release语义
如下伪代码,其最终执行顺序可能会是怎么样的呢?
1 // 2 code1 3 acquire 4 code2 5 release 6 code3
直接上结论:
(1)code1可以下移,但是不能超过release
(2)code3可以上移,但是不能超过acqurie
std::atomic<> 语义
C++11提供的原子变量模板,其保证如下:
(1)原子性:读写都是原子,不会读到部分结果或中间结果
(2)顺序性:所有针对原子变量的读写都会按顺序执行,实现顺序一致性(Sequence Consistency, SC)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号