爬取静态网页
进入网站之后需要获取网站正确url
使用Chrome自带检查工具 在网页右键--检查 利用全局搜索(ctrl+f) 12306 获取数据存储文件 list
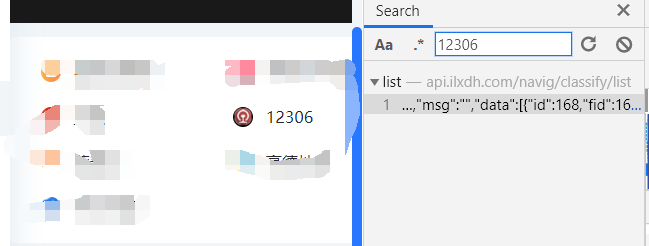

得到url:http://xxxxx
同时得到response method 为post 在最下方得到 Request Payload信息
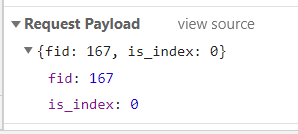
在Response栏获得json数据 将其全选 复制到json在线解析网站 得到json数据正确格式 并利于分析

根据所需数据 修改代码
以下为代码示例,我只获取了分类名和网站名,然后将其写入txt文件中
import requests
url = 'http://xxxxxxxxxxx' #获取网站正确url
data ={
'fid': '167',
'is_index': '0',
}
headers = {
#请求头信息
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.post(url=url,headers=headers,data=data).json()['data']
with open('wangzhan.txt','w',encoding='utf-8') as fp:
for i in response:
fp.write(i['name']+'\n')
for i in i['web']:
fp.write(i['name']+'\n'+i['url']+"\n")
print('下载完成')
以下为文档内容部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号