【Zookeeper】知识点
1 zookeeper是什么?
Zookeeper是一个分布式、开源的分布式应用程序的协调服务,是一个树形的目录服务
主要功能:
- 配置管理
- 分布式锁
- 集群管理
2 zookeeper入门
2.1命令
启动服务端:./zkServer.sh start
关闭服务器:./zkServer.sh stop
启动客户端:./zkCli.sh -server localhost:2181
退出客户端:quit
查看节点状态:./zkServer.sh status
查看命令帮助:help
显示指定目录下节点:ls 目录
显示指定目录详细信息:ls -s 目录
创建节点:create [-es] /节点path value
获取节点值:get /节点path
设置节点值:set /节点path value
删除单个节点:delete /节点path
删除带有子节点的节点:deleteall /节点path
2.1数据模型
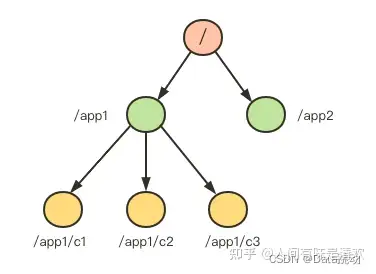
- Zookeeper是一个树形目录服务,其数据模型拥有一个层次化结构
- 这里面的每一个节点被称为:ZNode,每个节点上都会保存自己的数据和节点信息
- 节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点下
- 节点类型:
- PERSISTENT:持久化目录节点
- PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点 -s
- EPHEMERAL:临时目录节点。当前会话未结束数据会一直存在 -e
- EPHEMERAL_SEQUENTIAL:临时顺序编号目录节点 -es
2.3Curator
Curator是Apache Zookeeper的Java客户端库
/**
* @author olic
* @date 2022/6/2814:25
* @描述 Curator
*/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = JedisTests.class)
public class CuratorTests {
private CuratorFramework client;
/**
* 创建连接
*/
@Before
@Test
public void coon(){
// connectString:多个地址用,隔开; connectionTimeoutMs:连接超时时间; retryPolicy:重试策略
// minSessionTimeout, maxSessionTimeout:一般,客户端连接zookeeper的时候,都会设置一个session timeout,如果超过这个时间client没有zookeeper server有联系,则这个session被设置为过期(如果这个session上有临时节点,则会被全部删除),但是这个时间不是客户端可以无限设置的,服务器可以设置这两个参数来限制客户端设置的范围
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(retryPolicy)
.namespace("phenom") //此时phenom就是'/'目录
.build();
//开启连接
client.start();
}
/**
* 释放资源
*/
@After
@Test
public void close(){
if(client != null){
client.close();
}
}
/**
* 创建节点
*/
@Test
public void create() throws Exception {
// 创建节点不指定数据时,默认将当前客户端的ip作为数据存储
String path = client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.forPath("/app1/p1", "234".getBytes());
System.out.println(path);
}
/**
* 查询节点
*/
@Test
public void select() throws Exception {
// 节点值
byte[] bytes = client.getData().forPath("/app1");
// 子节点
List<String> sons = client.getChildren().forPath("/");
// 节点状态
Stat stat = new Stat();
client.getData().storingStatIn(stat);
System.out.println("子节点列表:"+ sons);
System.out.println("节点值为:"+ Arrays.toString(bytes));
System