redis数据结构---跳跃表
跳跃表(skiplist)是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的。
跳跃表支持平均 O(\log N) 最坏 O(N) 复杂度的节点查找, 还可以通过顺序性操作来批量处理节点。
跳跃表的实现
redis 的跳跃表由 zskiplistNode 和 zskiplist 两个结构定义,zskiplistNode 结构用于表示跳跃表节点,zskiplist 结构则用于保存跳跃表节点的相关信息
跳跃表节点
typedef struct zskiplistNode { // 后退指针 struct zskiplistNode *backward;
// 分值 double score; // 成员对象 robj *obj; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode;
- 层:跳跃表节点的 level 数组可以包含多个元素, 每个元素都包含一个指向其他节点的指针, 程序可以通过这些层来加快访问其他节点的速度, 一般来说, 层的数量越多, 访问其他节点的速度就越快。每次创建一个新跳跃表节点的时候, 程序会随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。
- 前进指针: 用于从表头向表尾方向访问节点
- 跨度:用于记录两个节点之间的距离,两个节点之间的跨度越大, 它们相距得就越远。指向 NULL 的所有前进指针的跨度都为 0 , 因为它们没有连向任何节点。
- 后退指针:用于从表尾向表头方向访问节点:,跟可以一次跳过多个节点的前进指针不同, 因为每个节点只有一个后退指针, 所以每次只能后退至前一个节点。
- 分值:是一个 double 类型的浮点数, 跳跃表中的所有节点都按分值从小到大来排序。
- 成员:是一个指针, 它指向一个字符串对象, 而字符串对象则保存着一个 SDS 值。
zskiplist结构
虽然仅靠多个跳跃表节点就可以组成一个跳跃表,但通过使用一个zskiplist结构来持有这些节点, 程序可以更方便地对整个跳跃表进行处理, 比如快速访问跳跃表的表头节点和表尾节点, 又或者快速地获取跳跃表节点的数量(也即是跳跃表的长度)等信息。
typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;
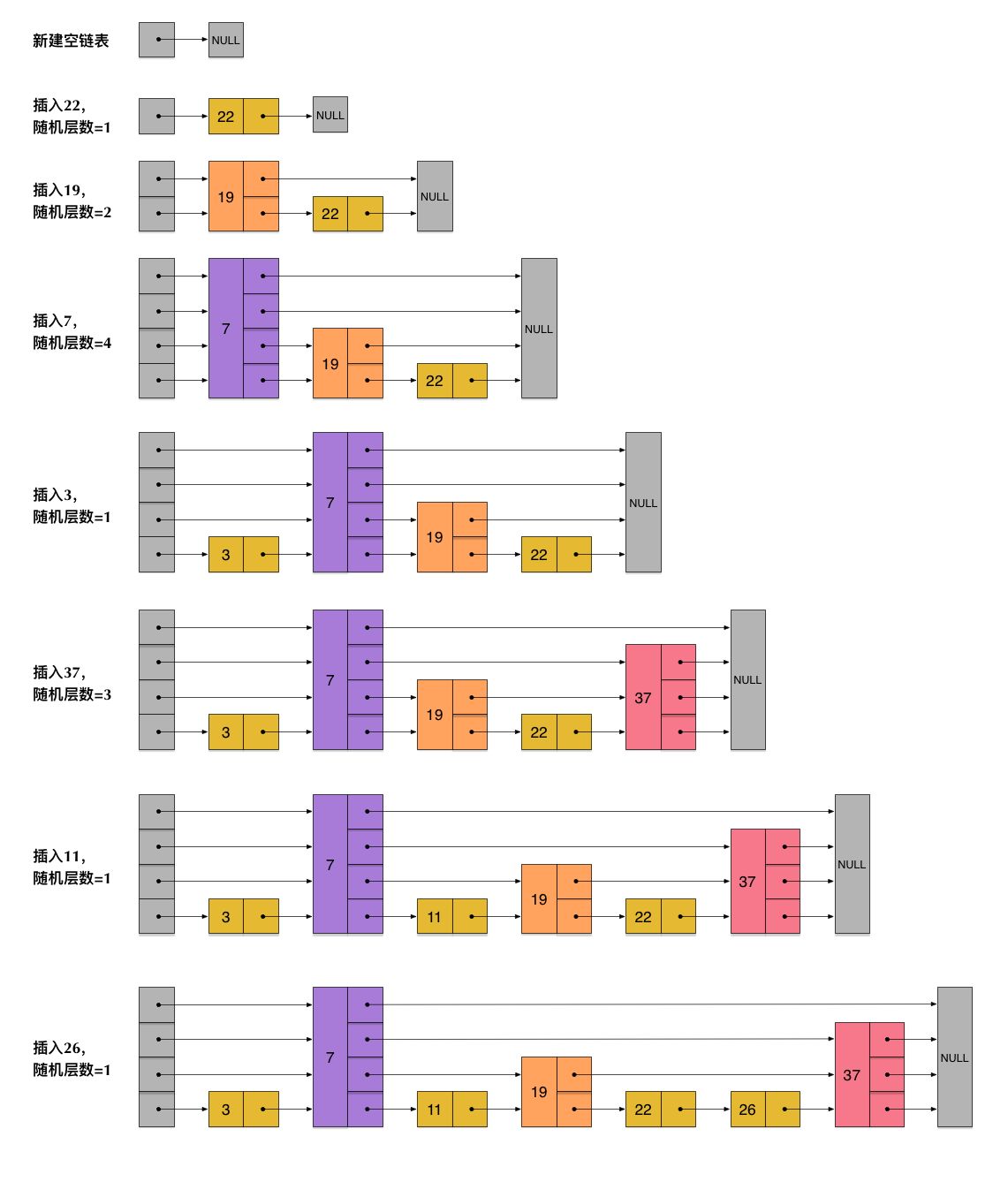
跳表创建过程
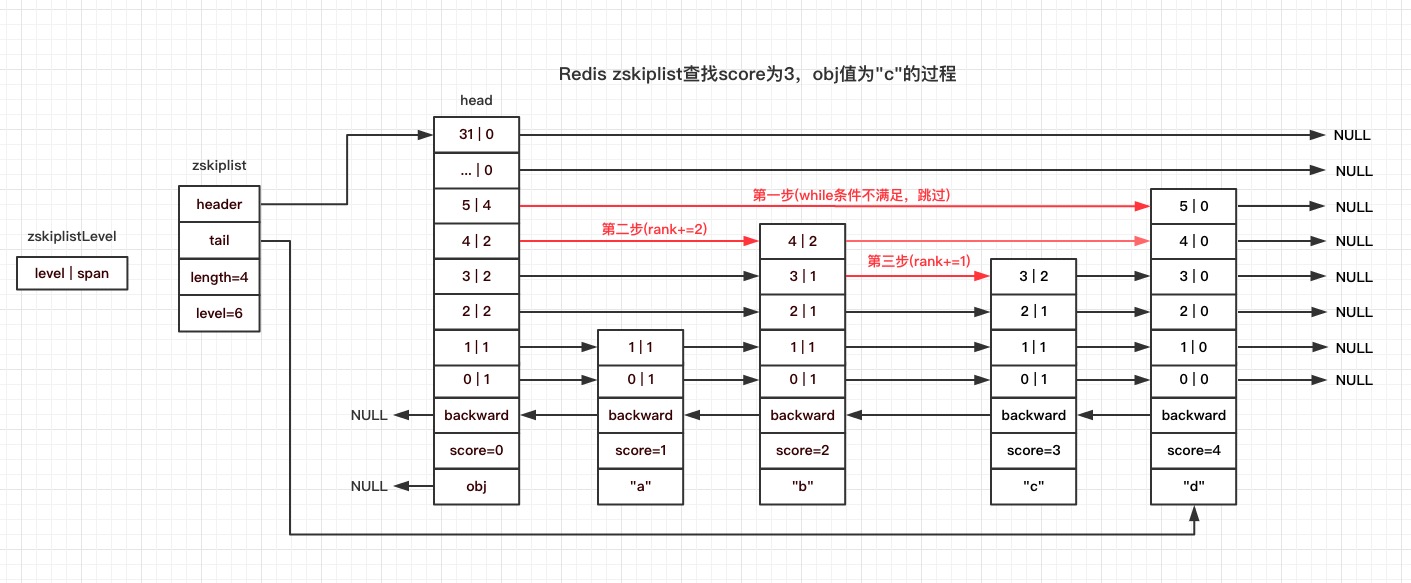
跳表查询过程
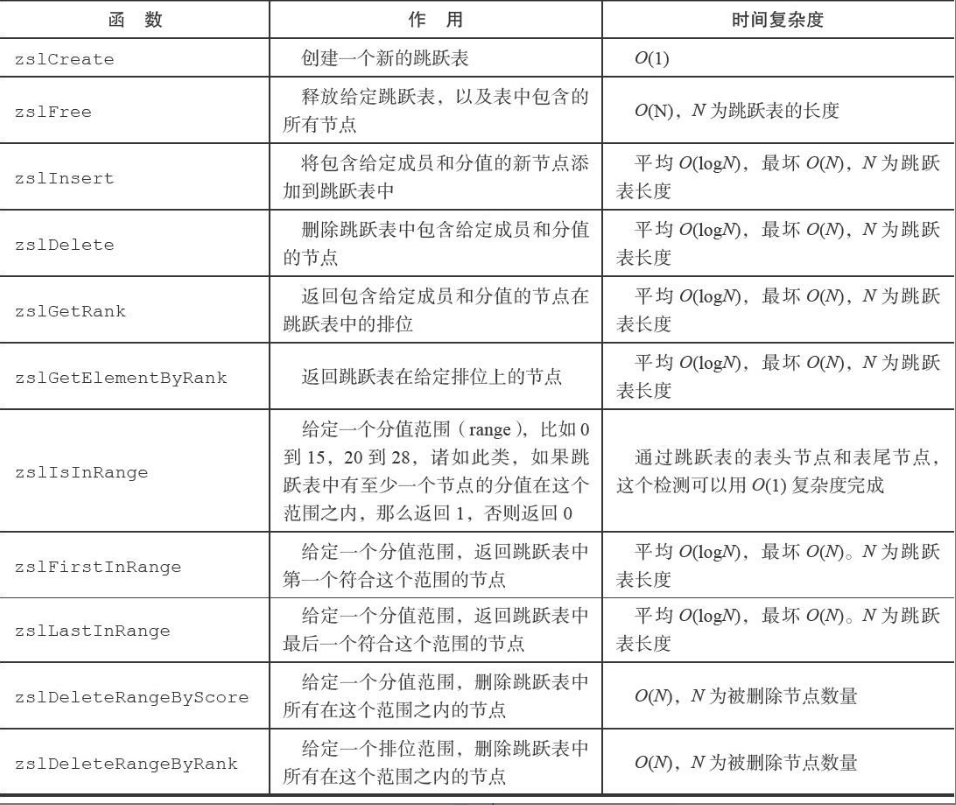
跳跃表API
本文参考《Redis设计与实现》(感觉书上的图不太好理解,自己从网上找的图)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号